


こんにちは。Tomoyuki(@tomoyuki65)です。
2026年現在、IT業界は生成AIの渦に飲まれ、システム開発におけるコーディングにおいては「人が書くもの」から「AIに書かせるもの」へ急速に移行しています。
もう既に生成AIを使った開発は避けられないため、エンジニアの仕事をしている方は適宜キャッチアップし、生成AIを使った開発手法として『AI駆動開発』を使いこなす必要があります。
そんなAI駆動開発において、次に覇権を取りそうだなと思っているプログラミング言語のフレームワークとして「Ruby on Rails」があります。
その理由としては、Ruby on Railsの設計思想は「設定より規約」となっており、ディレクトリ構成やコードの書き方、ベストプラクティスがほぼ標準化されていて、実装パターンの揺れが小さく、生成AIが前提として学習・再現しやすい構造になっているからです。
ということで、私もRuby on RailsでAI駆動開発を試してみることにしました。
この記事では、そんな私が試したRuby on RailsによるAI駆動開発の実践方法についてご紹介します。
目次
- 1 Ruby on Railsで始めるAI駆動開発×TDD実践|Codexとハーネスエンジニアリングで作るDDDモジュラーモノリス
- 2 OpenAI「Codex」におけるハーネスエンジニアリング設定
- 3 GitHub ActionsによるCIの導入
- 4 作成したプロジェクトをGitHubのリポジトリに登録
- 5 OpenAI「Codexアプリ」のプランモードで開発計画を立てる
- 6 OpenAI「Codexアプリ」でタスク実行を試す
- 7 スキル「auto-commit」でコミット処理をする
- 8 スキル「auto-pr」で自動PR作成を試す
- 9 本番環境用のDockerコンテナについて
- 10 AIツール利用時のセキュリティ対策について
- 11 最後に
Ruby on Railsで始めるAI駆動開発×TDD実践|Codexとハーネスエンジニアリングで作るDDDモジュラーモノリス
まず今回はmacOS(Apple silicon)のPCを使い、パッケージ管理に「Homebrew」、コード管理に「Git」や「GitHub」、ローカル開発環境に「Docker」、AIツールはOpenAIの「Codex」を利用する前提で進めます。
以降の内容を参考にしたい場合は、事前にこれらを利用できるように準備して下さい。
※GitHub CLIとして「gh」コマンドも準備が必要です。これはHomebrewでインストールできます。
関連記事
・OpenAI Codex CLI / Codexアプリの使い方【ChatGPT時代のAI開発ツール入門】
Ruby on Railsのローカル開発環境構築
次にRuby on Railsのローカル開発環境を構築します。
まずは以下のコマンドを実行し、各種ファイルを作成します。
$ mkdir rails-aidd && cd rails-aidd
$ mkdir -p deploy/docker/local/db && touch deploy/docker/local/db/Dockerfile
$ mkdir -p deploy/docker/local/ruby && touch deploy/docker/local/ruby/Dockerfile
$ mkdir src && touch src/Gemfile src/Gemfile.lock
$ touch .env compose.yml .gitignore
次に作成したファイルをそれぞれ以下のように記述します。
・「deploy/docker/local/db/Dockerfile」
FROM postgres:18.3
ENV LANG ja_JP.utf8
# PostgreSQLの日本語化で「ja_JP.utf8」を使うために必要
RUN apt-get update && \
apt-get install -y locales && \
rm -rf /var/lib/apt/lists/* && \
localedef -i ja_JP -c -f UTF-8 -A /usr/share/locale/locale.alias ja_JP.UTF-8※DBはPostgreSQLのバージョンは「18.3」を使います。
・「deploy/docker/local/ruby/Dockerfile」
FROM ruby:4.0.2-slim
RUN apt-get update -qq && \
apt-get install -y --no-install-recommends \
locales \
build-essential \
git \
libpq-dev \
libyaml-dev && \
rm -rf /var/lib/apt/lists/*
RUN echo "ja_JP.UTF-8 UTF-8" > /etc/locale.gen && \
locale-gen
WORKDIR /src
COPY src/Gemfile src/Gemfile.lock .
# bundlerのバージョンは固定して実行
RUN gem install bundler -v 4.0.10
RUN bundle _4.0.10_ install
COPY ./src /src
EXPOSE 3000※Rubyのバージョンは「4.0.2」、bundlerのバージョンは「4.0.10」を使います。
・「src/Gemfile」
source 'https://rubygems.org'
gem 'rails', '8.1.3'※Ruby on Railsのバージョンは「8.1.3」を使います。
・「.env」
ENV=local
RAILS_ENV=development
TZ=Asia/Tokyo
LANG=ja_JP.UTF-8
LC_ALL=ja_JP.UTF-8
PORT=3000
DB_HOST=db
DB_USER=root
DB_PASSWORD=root※今回はこのような環境変数を使い、それを.envを使って利用しますが、このような機密情報を扱う可能性があるものについては、ちゃんと使い方を理解してから使うようにして下さい。特にこれからのAI駆動開発では、AIツールから見える範囲にAPIキーなどの機密情報を置くべきではない(.envだろうが、1Password CLIだろうが、根本原因の解決にならず、プロンプトインジェクションの可能性を防げない)ので、APIキーを使う必要がある場合などは、そもそもAIツールを使わずに開発するなどして下さい。
関連記事
・生成AIで機密情報は大丈夫?AIツール開発のセキュリティ対策|ゼロトラスト・サンドボックス・環境変数(.env)管理
・「compose.yml」
services:
app:
container_name: rails-app
build:
context: .
dockerfile: ./deploy/docker/local/ruby/Dockerfile
command: bash -c "rm -f tmp/pids/server.pid && bundle exec rails s -b 0.0.0.0 -p 3000"
volumes:
- ./src:/src
ports:
- "3000:3000"
env_file:
- .env
tty: true
stdin_open: true
depends_on:
db:
condition: service_healthy
db:
container_name: rails-db
build:
context: .
dockerfile: ./deploy/docker/local/db/Dockerfile
environment:
POSTGRES_USER: ${DB_USER}
POSTGRES_PASSWORD: ${DB_PASSWORD}
TZ: ${TZ}
# ローカル環境でもパスワードを有効化する設定
POSTGRES_INITDB_ARGS: --auth-local=scram-sha-256 --auth-host=scram-sha-256
volumes:
- rails-db-data:/var/lib/postgresql
ports:
- "5432:5432"
env_file:
- .env
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${DB_USER}"]
interval: 5s
timeout: 5s
retries: 5
volumes:
rails-db-data:
・「.gitignore」
.DS_Store
.env
次に以下のコマンドを実行し、Dockerコンテナをビルドします。
$ docker compose build --no-cache
次に以下のコマンドを実行し、Railsのプロジェクトを作成します。
$ docker compose run --rm app rails new . -d postgresql \
--css=tailwind \
--skip-action-mailer \
--skip-action-mailbox \
--skip-action-text \
--skip-active-storage \
--skip-action-cable \
--skip-jbuilder \
--skip-test \
--skip-system-test※DBにPostgreSQLを使うのでオプション「-d postgresql」を付与、CSSにTailwind CSSを使うのでオプション「–css=tailwind」を付与、そしてできるだけ最小構成でやるため各種スキップオプションを付与してます。
実行後、ファイル「src/Gemfile」を上書きしていいか聞かれるので、「y」を入力して実行します。

上記処理ではGitの初期化処理はスキップせず、.gitignoreを合わせて作成するようにしていますが、Git管理は不要なので、以下のコマンドを実行してGit管理を削除します。
$ docker compose run --rm app rm -r .git
全て完了後、以下のようにRailsのプロジェクトとして各種ファイルが作成されればOKです。

次にファイル「src/Gemfile」に対して以下のように追加のライブラリを記述します。
・・・
group :development, :test do
# See https://guides.rubyonrails.org/debugging_rails_applications.html#debugging-with-the-debug-gem
gem "debug", platforms: %i[ mri windows ], require: "debug/prelude"
# Audits gems for known security defects (use config/bundler-audit.yml to ignore issues)
gem "bundler-audit", require: false
# Static analysis for security vulnerabilities [https://brakemanscanner.org/]
gem "brakeman", require: false
# Omakase Ruby styling [https://github.com/rails/rubocop-rails-omakase/]
gem "rubocop-rails-omakase", require: false
# ERB用のlint
gem "erb_lint", require: false
# テストライブラリ
gem "rspec-rails", require: false
# テストデータ用
gem "factory_bot_rails", require: false
end
・・・
# テスト用
group :test do
gem "faker"
gem "capybara"
gem "selenium-webdriver"
gem "webdrivers"
gem "shoulda-matchers", require: false
end※「group :development, :test do」の中に、「gem “erb_lint”, require: false」、「gem “rspec-rails”, require: false」、「gem “factory_bot_rails”, require: false」を追加してます。そしてテスト用として「group :test do」でテスト用の各種gemを追加してます。
次にファイル「src/config/application.rb」に対して、以下のようにタイムゾーン設定を追加します。
・・・
module Src
class Application < Rails::Application
# Initialize configuration defaults for originally generated Rails version.
config.load_defaults 8.1
# Please, add to the `ignore` list any other `lib` subdirectories that do
# not contain `.rb` files, or that should not be reloaded or eager loaded.
# Common ones are `templates`, `generators`, or `middleware`, for example.
config.autoload_lib(ignore: %w[assets tasks])
# Configuration for the application, engines, and railties goes here.
#
# These settings can be overridden in specific environments using the files
# in config/environments, which are processed later.
#
# config.time_zone = "Central Time (US & Canada)"
# config.eager_load_paths << Rails.root.join("extras")
# Don't generate system test files.
config.generators.system_tests = nil
# タイムゾーン設定
config.time_zone = ENV.fetch("TZ", "UTC")
end
end
次にファイル「src/config/database.yml」に対して、以下のようにdefault設定にDB接続設定を追加、production設定のusernameとpasswordはコメントアウトします。
・・・
default: &default
adapter: postgresql
encoding: unicode
# For details on connection pooling, see Rails configuration guide
# https://guides.rubyonrails.org/configuring.html#database-pooling
max_connections: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
# DB接続設定を追加
host: <%= ENV.fetch("DB_HOST") { "localhost" } %>
username: <%= ENV.fetch("DB_USER") { "postgres" } %>
password: <%= ENV.fetch("DB_PASSWORD") { "password" } %>
・・・
production:
primary: &primary_production
<<: *default
database: src_production
# コメントアウト
# username: src
# password: <%= ENV["SRC_DATABASE_PASSWORD"] %>
・・・
次に以下のコマンドを実行し、Dockerコンテナを再ビルドします。
$ docker compose build --no-cache
次に以下のコマンドを実行し、Dockerコンテナを起動します。
$ docker compose up -d
次に以下のコマンドを実行し、Dockerコンテナの起動を確認します。
$ docker compose ps
コマンド実行後、appコンテナとdbコンテナが起動すればOKです。

次に以下のコマンドを実行し、DBを作成します。
$ docker compose exec app rails db:create
次にブラウザで「http://localhost:3000」にアクセスし、以下のようにエラーにならずに正常にトップページが表示されればOKです。

テストフレームワーク「RSpec」の導入
次に以下のコマンドを実行し、Railsで人気のテストフレームワーク「RSpec」を導入していきます。
$ docker compose exec app rails g rspec:install
次に作成された設定ファイル「src/.rspec」について、「--color」と「--format documentation」を追加します。
・「src/.rspec」
--require spec_helper
--color
--format documentation
次にファイル「src/config/application.rb」に対して、以下のようにジェネレーター設定を追加します。
・・・
module Src
class Application < Rails::Application
# Initialize configuration defaults for originally generated Rails version.
config.load_defaults 8.1
# Please, add to the `ignore` list any other `lib` subdirectories that do
# not contain `.rb` files, or that should not be reloaded or eager loaded.
# Common ones are `templates`, `generators`, or `middleware`, for example.
config.autoload_lib(ignore: %w[assets tasks])
# Configuration for the application, engines, and railties goes here.
#
# These settings can be overridden in specific environments using the files
# in config/environments, which are processed later.
#
# config.time_zone = "Central Time (US & Canada)"
# config.eager_load_paths << Rails.root.join("extras")
# Don't generate system test files.
config.generators.system_tests = nil
# タイムゾーン設定
config.time_zone = ENV.fetch("TZ", "UTC")
# ジェネレーター設定
config.generators do |g|
g.test_framework :rspec
g.fixture_replacement :factory_bot, dir: "spec/factories"
g.view_specs false
g.helper_specs false
g.routing_specs false
g.controller_specs false
g.system_tests nil
end
end
end※コントローラーファイルなどを作成時に不要なファイルを作らないようにする設定を追加してます。
次にファイル「src/spec/rails_helper.rb」のENV[‘RAILS_ENV’]の設定について以下のように修正します。
# This file is copied to spec/ when you run 'rails generate rspec:install'
require 'spec_helper'
# RSpec実行時の環境変数「RAILS_ENV」の値が「test」になるように修正
# ENV['RAILS_ENV'] ||= 'test'
ENV['RAILS_ENV'] = 'test'
・・・※RSpec実行時に「RAILS_ENV=test」で実行できるように修正
次にファイル「src/spec/rails_helper.rb」において、まず「require “factory_bot_rails”」を追加後、RSpec.configureの部分でfixtureの設定をコメントアウトし、FactoryBotの設定を追加します。
・・・
require 'rspec/rails'
# Add additional requires below this line. Rails is not loaded until this point!
# FactoryBot追加
require "factory_bot_rails"
RSpec.configure do |config|
# Remove this line if you're not using ActiveRecord or ActiveRecord fixtures
# fixtureの設定をコメントアウト
# config.fixture_paths = [
# Rails.root.join('spec/fixtures')
# ]
# FactoryBotの設定を追加
config.include FactoryBot::Syntax::Methods
・・・※テストデータ作成が必要な際はFactoryBotを使う。
次に以下のコマンドを実行し、appコンテナを再起動します。
$ docker compose restart app
次に以下のコマンドを実行し、RSpecの実行を試します。
$ docker compose exec app bundle exec rspec
実行後、以下のように表示されればOKです。

shoulda-matchersとcapybaraの設定追加
次に「shoulda-matchers」(モデルのバリデーションチェック用)と「capybara」(ブラウザの画面テスト用)を使えるようにするため、ファイル「src/spec/rails_helper.rb」を以下のように修正します。
・・・
require 'rspec/rails'
# Add additional requires below this line. Rails is not loaded until this point!
# FactoryBot追加
require "factory_bot_rails"
# shoulda-matchers追加
require "shoulda/matchers"
# capybara追加
require 'capybara/rspec'
・・・
RSpec.configure do |config|
〜
end
・・・
# shoulda-matchers設定追加
Shoulda::Matchers.configure do |config|
config.integrate do |with|
with.test_framework :rspec
with.library :rails
end
end
# capybara設定
Capybara.default_driver = :selenium_chrome_headless※「require “shoulda/matchers”」と「require ‘capybara/rspec’」を追加、「Shoulda::Matchers.configure do |config| 〜 end」を追加、「Capybara.default_driver = :selenium_chrome_headless」を追加
「rubocop」でフォーマッターと静的コード解析を試す
Railsにおけるフォーマッターと静的コード解析用として「rubocop」を入れているため、それぞれ試します。
まずは以下のコマンドを実行し、フォーマッターを試します。
$ docker compose run --rm app bundle exec rubocop -A --only Layout※オプション「-A」は自動修正、オプション「–only Layout」はレイアウトのみ対象
実行後、以下のように表示されればOKです。

次に以下のコマンドを実行し、静的コード解析を試します。
$ docker compose run --rm app bundle exec rubocop
実行後、以下のように表示されればOKです。

「erb_lint」の設定を追加してビュー用の静的コード解析を試す
Railsにおけるビューの静的コード解析用として「erb_lint」を入れているため、設定を追加して試します。
まずは以下のコマンドを実行し、設定ファイル「src/.erb_lint.yml」を追加します。
$ touch src/.erb_lint.yml
次に作成したファイルを次のように記述します。
・「src/.erb_lint.yml」
linters:
ErbSafety:
enabled: true
FinalNewline:
enabled: true
TrailingWhitespace:
enabled: true※ErbSafetyは危険なERBコードを検出、FinalNewlineはファイルの最後に改行があるかチェック、TrailingWhitespaceは行末の余計なスペースを検出です。
次に以下のコマンドを実行し、ビューの静的コード解析を試します。
$ docker compose run --rm app bundle exec erb_lint app/views
実行後、以下のように表示されればOKです。

※今回はRubyの最新バージョンを利用しているため、警告が出ていますが無視して下さい。
「brakeman」でRailsの脆弱性検査を試す
次に以下のコマンドを実行し、「brakeman」によるRailsの脆弱性検査を試します。
$ docker compose exec app bundle exec brakeman --no-pager※デフォルトではlessページャー(lessコマンド)を使って結果を出力するようになっており、このままだとCIに組み込んだりできない(実行後に止めるにはEnterを押す必要)ため、オプション「–no-pager」を使って結果をターミナルに直接出力するようにします。
実行後、以下のように表示されればOKです。

Git管理
次に以下のコマンドを実行し、Git管理できるようにします。
$ git init
$ git add -A
$ git commit -m "init"
Gitフック管理ツール「Lefthook」を導入(任意)
次にチーム開発向け(任意)になりますが、Go言語製のGitフック管理ツール「Lefthook」を導入し、フォーマッターや静的コード解析、そしてテスト実行を自動化させます。
ツールはHomebrewで入れるため、以下のコマンドを実行してインストールして下さい。
$ brew install lefthook
次に以下のコマンドを実行し、lefthookを導入します。
$ lefthook install
次に作成されたファイル「lefthook.yml」を以下のように修正します。
pre-commit:
parallel: true
commands:
rubocop_format:
run: docker compose run --rm app bundle exec rubocop -A --only Layout
rubocop_lint:
run: docker compose run --rm app bundle exec rubocop
erb_lint:
run: docker compose run --rm app bundle exec erb_lint app/views
brakeman:
run: docker compose run --rm app bundle exec brakeman --no-pager
pre-push:
commands:
rspec:
run: |
docker compose up -d
docker compose exec -T app rails db:prepare
docker compose exec -T app bundle exec rspec※pre-commit設定にコミット時に実行させたい処理、pre-push設定にプッシュ時に実行させたい処理を設定します。
関連記事
・Go言語(Golang)開発でLefthookの使い方|pre-commitでformat・lint(静的解析)を自動化
ログ出力にリクエスト単位の一意のID(リクエストID)を出力する方法
実務などでは障害調査やデバッグのしやすくするため、ログ出力にはリクエスト単位の一意のID(リクエストID)を出力するようにしたりしますが、Railsであれば設定を追加することで簡単に実装可能です。
設定したい場合は、「src/config/environments」配下にある環境にあわせた設定ファイル(開発用ならdevelopment.rb、本番環境ならproduction.rb)に「config.log_tags = [ :request_id ]」を追加して下さい。
require "active_support/core_ext/integer/time"
Rails.application.configure do
・・・
# ログ出力にリクエストIDを追加
config.log_tags = [ :request_id ]
end
設定後にDockerコンテナを再起動すると設定が反映され、ログ出力を試すと以下のようにログの先頭に一意のID(リクエストID)が付与されます。

OpenAI「Codex」におけるハーネスエンジニアリング設定
AI駆動開発をする際には何らかのAIツールを利用しますが、今回はOpenAIの「Codexアプリ」または「Codex CLI」を利用する前提としています。
そしてAIツールを上手く使って開発するためには『ハーネスエンジニアリング』が重要になっており、事前にしっかりハーネス設計をする必要があります。
ハーネスエンジニアリングとは?
AIツールにおける『ハーネスエンジニアリング』とは、AIモデルやAIエージェントを安全かつ安定して動作させるため、入力・出力の制御やルール設定、評価・テストの仕組みなどを設計・構築する技術のことです。
これによってAIの挙動を管理し、品質や再現性を担保した状態で実運用できるようにします。
OpenAI「Codex」におけるハーネス設計について
OpenAI「Codex」でハーネス設計をしたい場合は、以下のようなディレクトリ構成で各種ファイルを作成し、それぞれ内容を定義していくことになります。
/my-project
├── /.codex
| ├── config.toml ※codexに関する設定
| |
| ├── /rules ※sandbox外で実行できるコマンド制御の設定
| | └── default.rules
| |
| ├── /agents ※サブエージェントを利用する場合の例
| | ├── orchestrator.toml ※指揮者(全体制御)
| | ├── tester.toml ※テスター(テストコード作成・検証)
| | ├── implementer.toml ※実装者(テストコードを通すように実装)
| | └── reviewer.toml ※レビュワー(設計や品質チェック)
| |
| ├── /workflows ※ワークフローを利用する場合の例
| | └── tdd_flow.md ※TDD(テスト駆動開発)のフロー
| |
| └── /skills ※Agent Skillsを利用する場合
|
├── AGENTS.md ※ルートディレクトリ用(共通ルール)
|
├── /src
| └── AGENTS.md ※サブディレクトリ用(専用ルール)
|
└── /docs ※詳細仕様にファイル分割して格納(各種AGENTS.mdから指定する)
└── /rules
├── architecture.md ※設計思想のルール定義
├── database.md ※DB設計のルール定義
├── sub.md ※サブディレクトリ用のルール定義
└── testing.md ※テスト用のルール定義
codexの設定ファイルを作成
まずはcodexの設定ファイルを作成するため、以下のコマンドを実行してファイルを作成します。
$ mkdir .codex && touch .codex/config.toml
次に作成したファイルを以下のように記述します。
・「.codex/config.toml」
model = "gpt-5.2"
model_reasoning_effort = "medium"
sandbox_mode = "workspace-write"※今回はモデルに「gpt-5.2」を指定(利用中のプランで使用可能なものを指定して下さい)、モデルの推論設定に「medium(バランス型)」を指定、サンドボックスモードに「workspace-write(書き込み許可)」を指定
尚、Codexアプリなどで対象のプロジェクトに設定した「.codex/config.toml」を有効化するには、対象のプロジェクトを信頼するプロジェクトにする必要があります。
対象のプロジェクトを信頼するプロジェクトにしたい場合は、グローバル設定の方のconfig.toml(~/.codex/config.toml)で、以下のような設定を追加して下さい。
[projects."対象のプロジェクトのフルパス"]
trust_level = "trusted"※設定変更を反映するにはCodexアプリの再起動が必要です。
sandbox外のコマンド制御設定を追加
次にsandbox外で実行できるコマンドを制御するため、以下のコマンドを実行してファイルを作成します。
$ mkdir -p .codex/rules && touch .codex/rules/default.rules
次に作成したファイルを以下のように記述します。
・「.codex/rules/default.rules」
# --- ディスク破壊(即禁止) ---
prefix_rule(
pattern=["mkfs", "dd if=", "wipefs"],
decision="forbidden",
justification="ストレージ破壊操作"
)
# --- Git履歴破壊(即禁止) ---
prefix_rule(
pattern=["git push --force", "git push -f", "git push --force-with-lease"],
decision="forbidden",
justification="履歴改変(強制push)によるリポジトリ破壊の可能性"
)
# --- GitHub CLI 危険操作 ---
prefix_rule(
pattern=["gh repo delete"],
decision="forbidden",
justification="リポジトリ削除(不可逆)"
)
prefix_rule(
pattern=["gh pr merge --admin"],
decision="prompt",
justification="保護ルール無視の強制マージ"
)
prefix_rule(
pattern=["gh workflow run"],
decision="prompt",
justification="CI/CDの強制実行"
)
prefix_rule(
pattern=["gh secret set", "gh secret delete"],
decision="prompt",
justification="機密情報の変更"
)
# --- 危険削除(確認) ---
prefix_rule(
pattern=["rm -rf", "sudo rm"],
decision="prompt",
justification="不可逆削除の可能性"
)
# --- 権限昇格 ---
prefix_rule(
pattern=["sudo"],
decision="prompt",
justification="システム影響が大きい"
)※まずは危険なコマンドを制御する
agents(サブエージェント)機能を追加
次にagents(サブエージェント)機能を試すため、以下のコマンドを実行してファイルを作成します。
$ mkdir -p .codex/agents
$ touch .codex/agents/pm.toml .codex/agents/tester.toml .codex/agents/implementer.toml .codex/agents/reviewer.toml※今回はpm(プロダクトマネージャー・指揮者)、tester(テスター)、implementer(実装者)、reviewer(レビュワー)の4名を想定しています。
次に作成したファイルをそれぞれ以下のように記述します。
・「.codex/agents/pm.toml」(プロダクトマネージャー / 指揮者)
name = "pm"
description = "全体の進行管理とタスク分解を行うプロダクトマネージャー"
model_reasoning_effort = "high"
sandbox_mode = "workspace-write"
developer_instructions = """
あなたは開発全体を指揮するプロダクトマネージャーです。
役割:
- 要件を整理し、タスクに分解する
- tester → implementer → reviewer の順でタスクを割り振る
- 各エージェントのアウトプットを評価し、次の行動を決める
ルール:
- 必ずTDDサイクル(RED → GREEN → REVIEW)を守る
- 不完全な実装は次に進めない
- 問題があれば前の工程に差し戻す
出力形式:
- 次に行動するエージェント名
- 依頼内容(具体的に)
"""
・「.codex/agents/tester.toml」(テスター)
name = "tester"
description = "テストコード作成と動作検証を行うTDDエンジニア"
model_reasoning_effort = "high"
sandbox_mode = "workspace-write"
developer_instructions = """
あなたはTDDに従うテストエンジニアです。
役割:
- 仕様に基づいたテストコードを書く(RED)
- 実装後にテストを実行し検証する(GREEN)
ルール:
- まず失敗するテストを書く(RED)
- テストは仕様を正確に表現すること
- エッジケースも考慮する
- 実装コードは書かない
出力:
- テストコード
- テストの意図説明
"""
・「.codex/agents/implementer.toml」(実装者)
name = "implementer"
description = "テストを通すための実装を行うエンジニア"
model_reasoning_effort = "medium"
sandbox_mode = "workspace-write"
developer_instructions = """
あなたはTDDに従う実装エンジニアです。
役割:
- テストが通る最小限の実装を書く
ルール:
- テストを通すことを最優先
- 過剰な設計をしない(YAGNI)
- テストを書かない
- リファクタは必要最低限
出力:
- 実装コード
- 実装の簡単な説明
"""
・「.codex/agents/reviewer.toml」(レビュワー)
name = "reviewer"
description = "仕様適合性・品質・セキュリティをレビューするエンジニア"
model_reasoning_effort = "high"
sandbox_mode = "read-only"
developer_instructions = """
あなたはコードレビュー担当です。
役割:
- 実装が仕様を満たしているか確認
- バグ・セキュリティ問題を検出
- テスト不足を指摘
観点:
- 正しさ(仕様通りか)
- セキュリティ
- 境界値・異常系
- テスト網羅性
ルール:
- 指摘は具体的に
- 再現手順を書く
- スタイル指摘は重要な場合のみ
出力:
- 指摘一覧(重要度付き)
- 修正提案
"""
workflows(ワークフロー)機能を追加
次にworkflows(ワークフロー)機能も試すため、以下のコマンドを実行してファイルを作成します。
$ mkdir -p .codex/workflows && touch .codex/workflows/tdd_flow.md※今回はTDD開発を前提とします。
次に作成したファイルを以下のように記述します。
・「.codex/workflows/tdd_flow.md」
# TDD開発フロー
本フローは pm の指示を起点として進行するが、
各エージェントは自身の責務に従い独立して実行する。
---
1. pmが要件を整理し、タスクとして分解する
2. testerが失敗するテストを書く(RED)
3. implementerがテストを通す(GREEN)
4. testerがテスト結果を検証する
5. reviewerがレビューを行う
6. 問題があれば修正ループに戻る
---
## ルール
- REDなしで実装しない
- GREEN未達でレビューしない
- レビューNGなら再実装
Agent Skillsを追加
次にAgent Skillsを試すため、以下のスキルを追加します。
・スキル「plan-to-issue」:プランモードで作成した開発計画をGitHubのIssue用のフォーマットへ変換して自動登録する
まずは以下のコマンドを実行し、各種ファイルを作成します。
$ mkdir -p .codex/skills/plan-to-issue && touch .codex/skills/plan-to-issue/SKILL.md
$ mkdir -p .codex/skills/plan-to-issue/references && touch .codex/skills/plan-to-issue/references/rules.md
$ mkdir -p .codex/skills/plan-to-issue/assets && touch .codex/skills/plan-to-issue/assets/template.md
$ mkdir -p .codex/skills/plan-to-issue/scripts && touch .codex/skills/plan-to-issue/scripts/create_issue.sh
$ chmod +x .codex/skills/plan-to-issue/scripts/create_issue.sh※スクリプトは「chmod +x」で実行権限を付与します。
次に作成したファイルをそれぞれ以下のように記述します。
・「.codex/skills/plan-to-issue/SKILL.md」
---
name: plan-to-issue
description: プランモードで作成した開発計画をGitHubのIssue用のフォーマットへ変換して自動登録する
---
# plan-to-issue
## 概要
このスキルは、プランモードで作成された開発計画を読み込み、指定されたルールとテンプレートに従ってGitHub Issue用のフォーマットへ変換し、専用のスクリプトを用いてGitHubへ自動登録します。
## 参照ファイル
このスキルを実行する際は、以下のファイルを必ず読み込んで使用してください。
- **変換ルール定義**: `references/rules.md`
- 開発計画からIssueフォーマットへ変換する際のルールや抽出条件が記載されています。
- **出力フォーマット**: `assets/template.md`
- Issueの本文を作成するためのMarkdownテンプレートです。
- **実行用スクリプト**: `scripts/create_issue.sh`
- 作成したIssueデータをGitHubに登録するためのシェルスクリプトです。
## 入力
プランモードで生成された開発計画
## 出力
GitHub Issue(gh issue create により自動登録)
## 実行手順(ワークフロー)
以下のステップに従って処理を実行してください。
1. **開発計画の読み込み**
- 現在のプランモードで作成・合意された開発計画(タスク、目的、要件など)を確認します。
2. **変換ルール定義の読み込み**
- `references/rules.md` を読み込み、開発計画の内容をGitHub Issue用のフォーマットに変換するためのルールを理解します。
3. **出力フォーマットの読み込み、テンプレートの生成**
- `assets/template.md` を読み込み、開発計画の内容を変換ルールに基づいてテンプレートの構造に当てはめ、Issueの本文を生成します。
4. **Issueのタイトルを作成**
- 生成したIssueの本文の内容から、変換ルールに基づいてIssueのタイトルを作成します。
5. **GitHubのIssueを登録**
- `scripts/create_issue.sh` を利用し、作成したIssueのタイトルと本文をGitHubのIssueに登録します。
・「.codex/skills/plan-to-issue/references/rules.md」
# 変換ルール定義(plan-to-issue)
このドキュメントは、プランモードで作成された開発計画をGitHub Issue用フォーマットへ変換するためのルールを定義する。
---
## 1. 基本方針
- 開発計画の内容を「1 Issue = 1目的(または1成果物)」の粒度で整理する
- 曖昧な記述は補完し、実行可能な形に正規化する
- 情報が不足している場合は、合理的に補完する(推測可)
- 冗長な説明は要約するが、重要な前提は保持する
---
## 2. フィールド対応ルール
開発計画の内容を以下のIssueテンプレートにマッピングする
### 2.1 概要(summary)
- 開発計画の「目的」「やること」を1〜3文で要約
- 実装内容ではなく「何を達成するか」を中心に記述
- 可能であれば動詞で開始する(例: 「〇〇を実装する」)
---
### 2.2 背景(background)
- なぜこの作業が必要なのかを記述
- 以下の情報を優先的に抽出
- 課題
- 現状の問題点
- ビジネス的/技術的な理由
- 明示されていない場合は、文脈から補完する
---
### 2.3 スコープ(scope)
- 対象範囲を明確化
- 含めるもの(In Scope)と含めないもの(Out of Scope)を整理
- 不明な場合は「暗黙のスコープ」を明文化する
例:
- 含む: API実装、UI変更
- 含まない: インフラ構築、リファクタリング全般
---
### 2.4 タスク(tasks)
- 実装手順をチェックリスト形式に分解
- 1タスク = 1アクション
- 粒度は「1〜3時間程度で完了できる単位」を目安に分割
#### タスク分解ルール
- 「設計」「実装」「テスト」「確認」を含める
- 抽象的な表現は禁止(例: 「いい感じに実装する」)
- 動詞で開始する(例: 「APIエンドポイントを作成する」)
#### 例
- [ ] APIのエンドポイントを定義する
- [ ] データモデルを作成する
- [ ] バリデーションを実装する
- [ ] 単体テストを追加する
---
### 2.5 受け入れ条件(acceptance_criteria)
- 完了とみなす条件を明確にする
- テスト可能・検証可能であることが必須
#### ルール
- 「〜できること」で記述
- 可能な限り具体的に書く
- 曖昧な表現は禁止(例: 「正常に動く」)
#### 例
- 正しいリクエストで200レスポンスが返ること
- 不正な入力時にバリデーションエラーが返ること
- UI上で新機能が操作できること
---
### 2.6 補足(notes)
- 以下の情報を含める
- 技術的な注意点
- 依存関係
- 未確定事項
- 将来対応
---
## 3. タイトル生成ルール
Issueタイトルは以下のルールで生成する
### フォーマット
[種別] 内容の要約
### 種別の分類
- feat: ユーザーに価値を提供する新機能
- fix: 不具合の修正
- refactor: 挙動を変えない内部改善
- docs: ドキュメントの追加・更新
- test: テストの追加・修正
- infra: インフラ・CI/CD・環境構築
- chore: 上記に当てはまらない雑務(極力使わない)
### ルール
- 30〜60文字程度に収める
- 内容が一目で分かるようにする
- summaryの内容をベースに生成する
例:
- feat: ユーザー登録APIを実装する
- fix: ログイン時の認証エラーを修正
---
## 4. Issue分割ルール
以下の場合は複数Issueに分割する
- 明確に独立した機能が複数存在する
- フロントエンドとバックエンドが分離可能
- 実装規模が大きすぎる(タスクが10個以上)
### 分割基準
- 各Issueが独立して完了可能であること
- 依存関係がある場合はnotesに記載
---
## 5. 不足情報の補完ルール
情報が不足している場合は以下に従う
- 文脈から合理的に推測する
- 推測した内容はnotesに明記する
- 重要な不確定要素は「要確認」として記載
---
## 6. 禁止事項
- 曖昧な表現(例: 適切に、いい感じに)
- 実行不可能なタスク分解
- 背景なしのIssue作成
- 受け入れ条件が検証不能な状態
---
## 7. 出力品質チェック
出力前に以下を確認する
- [ ] summaryが目的ベースになっている
- [ ] tasksが具体的で分解されている
- [ ] acceptance criteriaが検証可能である
- [ ] scopeが明確である
- [ ] タイトルが簡潔で分かりやすい
・「.codex/skills/plan-to-issue/assets/template.md」
## 概要
{{summary}}
## 背景
{{background}}
## スコープ
{{scope}}
## タスク
- [ ] {{tasks}}
## 受け入れ条件
- {{acceptance_criteria}}
## 補足
{{notes}}
・「.codex/skills/plan-to-issue/scripts/create_issue.sh」
#!/usr/bin/env bash
set -euo pipefail
# ===============================
# Usage:
# ./create_issue.sh "タイトル" "本文"
# ===============================
TITLE="${1:-}"
BODY="${2:-}"
# タイトルと本文の入力チェック
if [[ -z "$TITLE" || -z "$BODY" ]]; then
echo "Usage: $0 \"タイトル\" \"本文\""
exit 1
fi
# gh コマンド存在チェック
if ! command -v gh &> /dev/null; then
echo "gh コマンドが見つかりません"
exit 1
fi
# GitHub認証チェック
if ! gh auth status &> /dev/null; then
echo "GitHubにログインしていません"
echo "gh auth login を実行してください"
exit 1
fi
echo "Issueを作成中..."
# 一時ファイル作成
TMP_FILE=$(mktemp)
# 一時ファイルをスクリプト終了時に削除
trap 'rm -f "$TMP_FILE"' EXIT
# 本文を一時ファイルに書き込み
printf "%s" "$BODY" > "$TMP_FILE"
# Issue作成
gh issue create \
--title "$TITLE" \
--body-file "$TMP_FILE"
echo "Issue作成完了"
・スキル「auto-commit」:修正したコードをステージングしたうえで差分を解析し、適切なコミットメッセージを生成してgit commitまでを自動で実行する
次に以下のコマンドを実行し、各種ファイルを作成します。
$ mkdir -p .codex/skills/auto-commit && touch .codex/skills/auto-commit/SKILL.md
次に作成したファイルをそれぞれ以下のように記述します。
・「.codex/skills/auto-commit/SKILL.md」
---
name: auto-commit
description: 修正したコードをステージングしたうえで差分を解析し、適切なコミットメッセージを生成してgit commitまでを自動で実行する
---
# auto-commit
## 概要
このスキルは、コード修正後の未ステージ状態から変更を検出し、自動でステージング、差分解析、コミットメッセージ生成、git commit実行までを一貫して行う。
## 処理フロー
### 1. 未ステージの変更をステージ
以下のコマンドを実行し、未ステージの変更をすべてステージする。
```bash
git add -A
```
---
### 2. ステージ済み差分の取得
以下のコマンドを実行し、ステージ済みの変更内容の差分情報を取得する。
```bash
git diff --cached
```
---
### 3. 差分解析
取得したコードの差分情報から以下を解析する:
- 変更の目的(機能追加 / バグ修正 / リファクタリング / 雑務)
- 影響範囲(ファイル・モジュール)
- ユーザー視点での変化
- 変更が単一責務かどうか
---
### 4. コミットメッセージ生成
コードの差分情報の解析結果をもとに、
Conventional Commits形式でコミットメッセージを生成する。
#### フォーマット
`<type>: <summary>`
#### type一覧
- feat: 新規機能追加
- fix: バグ修正
- refactor: リファクタリング・性能改善
- test: テストの追加・修正
- docs: ドキュメント修正
- chore: その他
#### コミットメッセージの例
fix: ログイン時のトークン更新処理の不具合を修正
---
### 5. コミット実行
生成したコミットメッセージを用いて以下のコマンドを実行し、コミットを実行する。
```bash
git commit -m "<generated commit message>"
```
---
## 動作ルール
### 0. 実行順序
- 処理は必ず「git add → diff確認 → commit可否判定」の順で実行する
- git add は処理の最初に一度だけ実行する(追加実行は禁止)
---
### 1. 変更検知・終了条件
- 変更が存在しない場合は、git add / commit は実行せず処理を終了する
- git diff --cached の結果が空の場合も同様にコミットを行わない
- git add 後に再度差分を確認し、変更がない場合は即終了する
- 空コミットは絶対に作成しない
---
### 2. 安全性チェック(危険変更の制御)
- .env, secrets, credential系ファイルの変更が含まれる場合は必ず停止する
- 破壊的変更(大量削除・ファイル削除が多数)の場合は警告を出し、停止する
- 破壊的変更の定義:
- 削除ファイルが5件以上
- または差分行数の削除が追加の2倍以上
- 上記条件を満たす場合は自動実行せず、必ず停止してユーザー確認を求める
---
### 3. コミット構造ルール
- 1つのコミットは必ず単一の目的(単一責務)になるようにする
- 複数の変更目的が混在している場合は論理的にまとめるか警告扱いとする
- 大規模変更(複数モジュールにまたがる変更)の場合は、可能であれば分割コミットを優先する
---
### 4. コミットメッセージ生成ルール
- コミットメッセージは必ず変更内容に基づいて生成し、推測や一般論で補完しない
- 差分から読み取れない情報は含めない
- メッセージは簡潔にしつつ、変更の「意図」が分かる表現にする
- 実装内容の羅列ではなく、何が改善されたかを優先する
- コミットメッセージは50〜72文字程度を目安にする
- 英語・日本語のどちらを使うかはプロジェクトの既存コミットに合わせて統一する
---
### 5. 変更分類ルール
- 変更内容が以下に該当する場合は chore に分類する
- フォーマット修正のみ
- コメント修正のみ
- 空白・改行整理のみ
- 自動生成ファイルの更新
---
### 6. コミット実行ルール
- commit 実行前に最終的なメッセージを内部で確定させること
- git commit は確定したメッセージのみで実行する
---
## まとめ
このスキルは以下を保証する:
- 安全な自動コミット(事故防止)
- 意味ベースのコミット生成
- 単一責務の維持
- 変更意図の明確化
- チーム規約との整合性
・スキル「auto-pr」:直前のコミット内容をもとにPRタイトルと本文を生成し、GitHubのPR用フォーマットへ変換して自動登録する
次に以下のコマンドを実行し、各種ファイルを作成します。
$ mkdir -p .codex/skills/auto-pr && touch .codex/skills/auto-pr/SKILL.md
$ mkdir -p .codex/skills/auto-pr/assets && touch .codex/skills/auto-pr/assets/template.md
$ mkdir -p .codex/skills/auto-pr/scripts && touch .codex/skills/auto-pr/scripts/create_pr.sh
$ chmod +x .codex/skills/auto-pr/scripts/create_pr.sh※スクリプトは「chmod +x」で実行権限を付与します。
次に作成したファイルをそれぞれ以下のように記述します。
・「.codex/skills/auto-pr/SKILL.md」
---
name: auto-pr
description: 直前のコミット内容をもとにPRタイトルと本文を生成し、GitHubのPR用フォーマットへ変換して自動登録する
---
# auto-pr
## 概要
このスキルは、直前のコミット内容をもとにPRタイトルと本文を生成し、GitHubのPR用フォーマットへ変換して自動登録します。
## 参照ファイル
このスキルを実行する際は、以下のファイルを必ず読み込んで使用してください。
- PRテンプレート: `assets/template.md`
- PR作成スクリプト: `scripts/create_pr.sh`
## 入力
直前のコミット情報
## 出力
GitHubのPR(gh pr create により自動登録)
---
## 実行手順
### 1. 直前のコミット情報と変更内容を取得する
```bash
git log -1 --pretty=format:"%h%n%s%n%b"
git show --no-color
```
- git log: 意図(タイトル・背景)
- git show: 変更内容(diff)
---
### 2. 解析して以下を生成する
- summary(概要)
- background(背景・目的)
- implementation(実装内容:箇条書き)
- test_items(テスト確認項目:チェックリスト形式)
- impact(影響範囲:箇条書き)
- future_work(未対応・今後の課題:箇条書き)
---
### 3. PR本文を生成する
`assets/template.md` を読み込み、以下ルールで置換する:
- {{summary}} → summary
- {{background}} → background
- {{implementation}} → implementation
- {{test_items}} → test_items
- {{impact}} → impact
- {{future_work}} → future_work
---
### 4. PRタイトルを生成する
フォーマット:
```text
auto: <summaryの短縮版>
```
---
### 5. PRを作成する
`scripts/create_pr.sh` を利用し、生成したPRタイトルと本文をGitHubのプルリクエストに登録します。
---
## 補足ルール
- implementation / impact / future_work は必ず箇条書きで出力する
- test_items はチェックリスト形式(- [ ])で出力する
- diff(git show)を必ず参照し、推測のみで生成しない
・「.codex/skills/auto-pr/assets/template.md」
## 概要
{{summary}}
## 背景・目的
{{background}}
## 実装内容
- {{implementation}}
## テスト確認項目
- [ ] {{test_items}}
## 影響範囲
- {{impact}}
## 未対応・今後の課題
- {{future_work}}
・「.codex/skills/auto-pr/scripts/create_pr.sh」
#!/usr/bin/env bash
set -euo pipefail
# ===============================
# Usage:
# ./create_pr.sh "タイトル" "本文"
# ===============================
TITLE="${1:-}"
BODY="${2:-}"
# タイトルと本文の入力チェック
if [[ -z "$TITLE" || -z "$BODY" ]]; then
echo "Usage: $0 \"タイトル\" \"本文\""
exit 1
fi
# gh コマンド存在チェック
if ! command -v gh &> /dev/null; then
echo "gh コマンドが見つかりません"
exit 1
fi
# GitHub認証チェック
if ! gh auth status &> /dev/null; then
echo "GitHubにログインしていません"
echo "gh auth login を実行してください"
exit 1
fi
echo "PRを作成中..."
# 一時ファイル作成
TMP_FILE=$(mktemp)
# 一時ファイルをスクリプト終了時に削除
trap 'rm -f "$TMP_FILE"' EXIT
# 本文を一時ファイルに書き込み
printf "%s" "$BODY" > "$TMP_FILE"
# PR作成
gh pr create \
--title "$TITLE" \
--body-file "$TMP_FILE"
echo "PR作成完了"
今回のプロジェクト用のハーネス設定
次に今回のプロジェクト用のハーネス設定を行いますが、今回はRailsでMVCのアプリかつ、将来性を考慮してモジュラーモノリス(DDD)設計にすることを想定しています。
そのため、今回のRailsアプリのディレクトリ構成としては、以下のような構成を想定します。
/src
└── /app
├── /controllers(コントローラー定義)
| |
| ├── /web
| |
| └── /api (将来的に利用する想定のAPIモード用)
|
├── /models(アプリ全体の共通データ層・ActiveRecordモデル置き場)
|
├── /views(Rails用のビュー)
|
├── /domains(中核の業務領域・ドメイン駆動設計)
| |
| └── /[domain_name]
| |
| ├── /domain(ドメイン層)
| | |
| | ├── /entities(エンティティ)
| | |
| | ├── /value_objects(値オブジェクト)
| | |
| | ├── /services(ドメインサービス)
| | |
| | └── /repositories(リポジトリのインターフェース)
| |
| ├── /use_cases(ユースケース層)
| |
| └── /infrastructure(インフラストラクチャ層)
| |
| └── /repositories(リポジトリの実装)
| |
| ├── /command(書き込み)
| |
| └── /query(読み込み)
|
├── /features(補完的な業務領域・トランザクションスクリプト)
| |
| └── /[feature_name]
| |
| └── /services(サービス層)
|
├── /resources(一般的な業務領域・アクティブレコード)
| ※例:user.rbやpayment_gateway.rbなどを置く
|
└── /shared(横断関心)※今回は使っていませんが、実際には「/app/container」ディレクトリなどを作ってユースケースにリポジトリをDIできるようにし、それをコントローラーから呼び出すようにした方がいいです。
このように、今回の例ではモジュラーモノリスかつドメイン駆動設計(DDD)を考慮したディレクトリ構成としています。
モジュラーモノリスは、システム全体は1つのデプロイ単位(モノリス)として扱いながら、分割されたモジュール(機能群)で構成する設計手法です。
ドメイン駆動設計(DDD:Domain-Driven Design)は複雑な業務ロジックを中心に据え、共通言語(ユビキタス言語)を用いて設計する手法です。
特にドメイン駆動設計については難しいため、実務を想定している方については、以下の関連記事などを参考にしたり、事前にドメイン駆動設計の理解をするようにして下さい。
関連記事
・ドメイン駆動設計(Domain-Driven Design / DDD)の本質と大事なこと
そして、今回はAI駆動開発を試していきますが、その際はテスト駆動開発(TDD)も併せてしていく流れになります。
テスト駆動開発(TDD:Test-Driven Development)については、プログラムの機能実装前に対応するテストコードを先に作成し、そのテストに合格するように実装とリファクタリングを繰り返す開発手法です。
今回はそれらを踏まえて各種定義ファイルを作成していく必要があるため、まずは以下のコマンドを実行し、各種ファイルを作成します。
$ mkdir -p docs/rules
$ touch docs/rules/architecture.md docs/rules/database.md
$ touch docs/rules/boundaries.md docs/rules/rails.md docs/rules/testing.md
$ touch src/AGENTS.md AGENTS.md※今回はできるだけ最小構成になるようにしています。ファイル数を増やしてしっかり定義した方が、より想定外の動作やリスクを防ぐことができるようになります。
次に作成したファイルをそれぞれ以下のように記述します。
・「docs/rules/architecture.md」(アーキテクチャ設計のルール定義)
# アーキテクチャ設計のルール定義
## 概要
本プロジェクトはRailsベースのモジュラーモノリス構成かつドメイン駆動設計(DDD)を採用し、業務の複雑さと表現力に応じて以下の3層に分離します。
- 中核の業務領域 → ドメイン駆動設計(DDD)→ domains
- 補完的な業務領域 → トランザクションスクリプト → features
- 一般的な業務領域 → アクティブレコード(単純なCRUD) → resources
---
## ディレクトリ構造の前提
```
/src
├── /app
| ├── /controllers(コントローラー定義)
| | |
| | ├── /web
| | |
| | └── /api (将来的に利用する想定のAPIモード用)
| |
| ├── /models(アプリ全体の共通データ層・ActiveRecordモデル置き場)
| |
| ├── /views(Rails用のビュー)
| |
| ├── /domains(中核の業務領域・ドメイン駆動設計)
| | |
| | └── /[domain_name]
| | |
| | ├── /domain(ドメイン層)
| | | |
| | | ├── /entities(エンティティ)
| | | |
| | | ├── /value_objects(値オブジェクト)
| | | |
| | | ├── /services(ドメインサービス)
| | | |
| | | └── /repositories(リポジトリのインターフェース)
| | |
| | ├── /use_cases(ユースケース層)
| | |
| | └── /infrastructure(インフラストラクチャ層)
| | |
| | └── /repositories(リポジトリの実装)
| | |
| | ├── /command(書き込み)
| | |
| | └── /query(読み込み)
| |
| ├── /features(補完的な業務領域・トランザクションスクリプト)
| | |
| | └── /[feature_name]
| | |
| | └── /services(サービス層)
| |
| ├── /resources(一般的な業務領域・アクティブレコード)
| | ※例:user.rbやpayment_gateway.rbなどを置く
| |
| └── /shared(横断関心)
|
└── /spec(テストコード)
```
---
## レイヤー構成の定義
### domains(中核の業務領域 / ドメイン駆動設計)
事業の本質的価値を生み出す領域
#### 特徴
- 業務ルールが複雑で変化しやすい
- 意思決定ロジックの中心
- ビジネス競争力に直結する領域
- ドメインモデルが重要になる
#### 設計原則(DDD適用)
- 集約・エンティティ / 値オブジェクト / ドメインサービスを適用する
- ビジネスルールをコードとして明示的に表現する
- 副作用を最小化する
- 可能な限り純粋ロジックとして設計する
#### 構造
- [domain_name]
- domain(ドメイン層)
- entities(エンティティ)
- value_objects(値オブジェクト)
- services(ドメインサービス)
- repositories(リポジトリのインターフェース)
- use_cases(ユースケース層)
- infrastructure(インフラストラクチャ層)
- repositories(リポジトリの実装)
- command(書き込み)
- query(読み取り)
#### 例
- 与信判断
- 価格最適化
- 予約枠管理
- 配送ルート最適化
---
### features(補完的な業務領域 / トランザクションスクリプト)
中核業務を支える周辺処理領域
#### 特徴
- 業務ルールは存在するが比較的単純
- 処理の流れ(手続き)が中心
- 複数処理や外部処理の調整役
#### 設計原則
- トランザクションスクリプトとしてサービス層に実装する
- ユースケース単位で記述する
- トランザクション境界はサービス層で明確に管理する
- シンプルなデータ操作に限定し、複雑なロジックは持ち込まない
- 可読性を優先し、副作用や永続化は明示的に分離する
- 複雑化・肥大化した場合はdomainsへ移行する
#### 構造
- [feature_name]
- services(サービス層)
#### 例
- 注文後メール送信
- ポイント付与
- 在庫減算処理
- 単純な承認フロー
---
### resources(一般的な業務領域 / アクティブレコード)
業務固有性が低いデータ管理領域
#### 特徴
- CRUD中心の処理
- ビジネスルールが薄い
- データの保存・取得が主目的
#### 設計原則
- ActiveRecordベースで十分表現可能
- インフラ寄りの扱い
- 業務判断を持たない
#### 構造
- [resource_name.rb]
#### 例
- ユーザー基本情報
- マスターデータ(カテゴリ・都道府県など)
- ログ
- 設定情報
---
## shared(横断関心)
全レイヤーから参照可能な共通処理
### 例
- /utils
- /constants
- /types
- /errors
- /validators
- /formatters
- /time
- /pagenation
---
## models(データ層 / ActiveRecord集約層)
- 全てのActiveRecordのモデルはここに集約する
- データアクセスの唯一の責務を持つ
- 業務ロジックは禁止
- 各レイヤーから利用される基盤層
---
## 依存関係
### 呼び出し方向(実行フロー)
- controller → domains/use_cases または features/services または resources
- domains/use_cases → repositories → models
- features/services → models
- resources → models
- shared (全レイヤーから参照可能)
---
## 基本原則
- controller:HTTPリクエストの受け取り、ユースケースの呼び出し専用
- domains:中核の業務領域、複雑で競争優位性が高いビジネスをここに集約
- features:補完的な業務領域、単純で競争優位性を生み出さないビジネスをここに集約
- resources:一般的な業務領域、複雑だが競争優位性を生み出さずに共通の仕組みを利用するビジネスをここに集約
- shared:横断関心、各レイヤーから利用可能な共通の処理を集約
- models:データ層
---
## 設計判断基準
設計する際の分類基準は以下の通り:
- ルールやビジネスロジックが複雑になり、破綻しやすいもの → domains
- ルールが薄く、単純であり、処理フロー中心のもの → features
- 単純なCRUD処理や、共通の外部サービスを利用するもの → resources
---
## その他の重要ルール
- controllerは直接modelsを呼び出して操作しない
- controllerは必ずユースケース層を経由する
- レイヤー内部の実装詳細は外部から呼ばない
・「docs/rules/database.md」(データベース設計のルール定義)
# データベース設計のルール定義
## 基本方針
- ActiveRecordを唯一のORMとして使用する
- DBは永続化の責務のみを持つ
---
## モデル設計
- 全モデルは src/app/models に集約する
- ビジネスロジックは禁止
- scopeは軽量クエリのみ許可
---
## スキーマ設計
- 破壊的変更を避ける
- NULL制約・外部キー制約を積極的に使用
- インデックスは用途ベースで設計する
---
## 禁止事項
- DBに業務ルールを持たせない
- fat model禁止
・「docs/rules/boundaries.md」(コード配置のルール定義・境界ルール定義)
# コード配置のルール定義・境界ルール定義
## 目的
業務重要度と役割に応じてコードの配置場所を決定する。
---
## ディレクトリ構造の前提
```
/src
├── /app
| ├── /controllers(コントローラー定義)
| | |
| | ├── /web
| | |
| | └── /api (将来的に利用する想定のAPIモード用)
| |
| ├── /models(アプリ全体の共通データ層・ActiveRecordモデル置き場)
| |
| ├── /views(Rails用のビュー)
| |
| ├── /domains(中核の業務領域・ドメイン駆動設計)
| | |
| | └── /[domain_name]
| | |
| | ├── /domain(ドメイン層)
| | | |
| | | ├── /entities(エンティティ)
| | | |
| | | ├── /value_objects(値オブジェクト)
| | | |
| | | ├── /services(ドメインサービス)
| | | |
| | | └── /repositories(リポジトリのインターフェース)
| | |
| | ├── /use_cases(ユースケース層)
| | |
| | └── /infrastructure(インフラストラクチャ層)
| | |
| | └── /repositories(リポジトリの実装)
| | |
| | ├── /command(書き込み)
| | |
| | └── /query(読み込み)
| |
| ├── /features(補完的な業務領域・トランザクションスクリプト)
| | |
| | └── /[feature_name]
| | |
| | └── /services(サービス層)
| |
| ├── /resources(一般的な業務領域・アクティブレコード)
| | ※例:user.rbやpayment_gateway.rbなどを置く
| |
| └── /shared(横断関心)
|
└── /spec(テストコード)
```
---
## レイヤー定義
### app/controllers(コントローラー)
- HTTPリクエストを受け取り、レスポンスを返すための薄いレイヤー
- パラメータの受け取り・バリデーション・認証/認可の入口を担う
- ユースケース層(app/domains/*/use_cases or app/features/*/services or app/resources/*)を呼び出す
- 業務ロジックは持たない(持ってはいけない)
- レスポンス整形(JSON / HTML)は行うが、ビジネス判断は行わない
#### 依存ルール
- controllers → ユースケース(app/domains/*/use_cases or app/features/*/services or app/resources/*)
- controllers → views(HTMLの場合)
---
### app/models(データ層 / ActiveRecordモデル置き場)
- ActiveRecordベースのDBテーブルとのマッピングを担う
- スキーマ表現・リレーション・スコープなどの永続化に近い関心を持つ
- コールバックやロジックは極力最小限に抑える
- ドメイン層から直接使わず、Infrastructure層経由で利用するのが基本
- 「Fat Model」にしない(ビジネスロジックはドメインへ)
#### 依存ルール
- models ← infrastructure(repositoryなど)
---
### app/views(Rails用のビュー)
- HTMLテンプレートの描画を担う
- 表示ロジック(フォーマット・簡単な条件分岐)のみ許容
- 業務ロジックやドメイン知識は持たない
- instance変数はcontrollerから受け取る
#### 依存ルール
- views ← controllers
---
### app/domains(中核の業務領域 / ドメイン駆動設計)
- アプリケーションの最も重要なビジネスロジックを集約
- 境界づけられたコンテキスト(= domain_name)単位で分割
#### domain/entities
- 同一性(ID)を持つオブジェクト
- ビジネスルール・不変条件を保持
- 永続化手段(ActiveRecordなど)に依存しない
#### domain/value_objects
- 不変オブジェクト
- 値による等価性で比較される
- ドメインルールを内包可能(例:金額、メールアドレス)
#### domain/services
- エンティティやVOに属さないドメインロジック
- 複数のエンティティにまたがるビジネスルールを表現
#### domain/repositories
- リポジトリのインターフェース定義
- 実装部分はinfrastructure/repositoriesで行う
- コマンド・クエリ責務分離(CQRS)設計とし、command(書き込み)とquery(読み取り)に分ける
#### use_cases
- アプリケーションのユースケース単位の処理
- トランザクション境界を管理
- ドメインオブジェクトを組み合わせて処理を実行
- 外部I/F(repositoryなど)はインターフェース経由で利用
#### infrastructure/repositories
- 永続化の具体実装
- ActiveRecord(app/models)を利用してDBアクセスを行う
- ドメイン層に定義されたRepositoryインターフェースを実装
- 外部APIや他システム連携もここに含めてよい
#### 依存ルール
- domain層は他のレイヤーに依存しない
- use_casesはdomainに依存するが、infrastructureの詳細には依存しない(DI前提)
- infrastructureはdomainに依存してよい
---
### app/features(補完的な業務領域 / トランザクションスクリプト)
- ドメインとして切り出すほどではないが、機能としてまとまりがある処理
- シンプルな業務ロジックを扱う
- サービスとして実装する
#### services
- 1サービス1ユースケースとして表現
- ActiveRecord(app/models)を直接利用してよい
- 複雑化したらdomainsへ昇格させる前提
#### 位置づけ
- 軽量なユースケース層
- DDDの厳密さを求めない代わりにスピードを優先
#### 依存ルール
- features → models はOK
- features → domains は原則避ける
---
### app/resources(一般的な業務領域 / アクティブレコード)
- 単純なCRUD処理など、共通の仕組みを利用するような処理
#### 例
- ActiveRecordベースのシンプルなCRUD処理
- 例:User、PaymentGatewayなど
- 外部サービスのような共通の仕組みを利用する単純な処理
- ビジネスルールが薄い処理
#### 役割
- ドメインに昇格しないActiveRecordベースの共通処理置き場
---
### app/shared(横断関心)
- 全レイヤーから参照可能な共通処理
#### 例
- /utils
- /constants
- /types
- /errors
- /validators
- /formatters
- /time
- /pagenation
---
### spec(テストコード)
#### 基本方針
- レイヤーごとに責務に応じたテストを行う
- 下位レイヤーほど高速・純粋、上位レイヤーほど統合的に検証する
- 「どこで何を保証するか」を明確にし、テストの重複を避ける
- ビジネスロジックは domainsで担保する(他レイヤーで重複して検証しない)
---
#### 主な分類
- controllers:インテグレーションテスト → リクエストスペック
- HTTPリクエスト/レスポンスの検証(ステータスコード、JSON構造など)
- 認証・認可の動作確認
- ユースケースが正しく呼ばれていることの間接確認
- 業務ロジックの詳細までは検証しない
- 可能な限りモックを使わず、実際のスタックに近い形で検証する
- models:ユニットテスト → モデルスペック
- スコープ・バリデーション・リレーションの検証
- DBに近い振る舞い(クエリ結果など)の確認
- コールバックは必要最小限にし、テストも最小限に留める
- ビジネスロジックはテストしない(domainで担保)
- views:E2Eテスト → システムスペック
- ユーザー操作を通した画面表示の検証
- フォーム入力〜結果表示までの一連のフロー確認
- 表示崩れや重要なUI要素の存在確認
- 細かい文言やHTML構造には依存しすぎない
- JavaScriptを含む挙動もここで検証
- domains:ユニットテスト
- ビジネスルール・不変条件の検証
- エンティティ・ValueObject・ドメインサービスの振る舞い確認
- 外部依存(DB・API)は排除し、純粋なオブジェクトとしてテスト
- 境界値・異常系を重点的にテストする
- 最も網羅的かつ信頼できるテスト層
- features:インテグレーションテスト
- Request Specを利用
- サービス単位でのユースケース検証
- ActiveRecordを含めた一連の処理の動作確認
- 複雑な分岐や副作用(レコード作成・更新)を検証
- controller経由 or 直接サービス呼び出しのどちらでもよい
- domainに昇格すべきロジックが混ざっていないかの検知にも使う
- resources:E2Eテスト
- API:request spec(統合テスト) / View:system spec(E2Eテスト)
- API:クライアント視点でリクエストの連携が成立することを担保
- View:ユーザー操作として一連の体験が成立することを担保
- 主要なフロー(登録 → 認証 → 操作)の検証
- 認証・認可・決済など横断的関心の動作確認
- クライアント視点でAPIが正しく連携できることを担保
- 成功パターンを中心に最小限のケースに絞る
- 詳細なバリデーションや分岐ロジックは下位レイヤーで担保
---
#### 補足ポリシー
- ドメイン層は最速で実行できるテストにする(DBアクセス禁止)
- インフラ層(repositoryなど)は必要に応じて統合テストを行う
- モックは「外部境界」に限定して使用する(DB・外部APIなど)
- テストが壊れやすい構造(過度なモック、内部実装依存)を避ける
- 迷った場合は「その責務はどのレイヤーか」に立ち返って配置する
---
## ユースケース呼び出しルール
- controllerは各レイヤーに定義されたユースケースのみ呼び出す。
- 内部実装やモデルは直接呼ばない。
### 例
- domains/use_casesのユースケース
- features/servicesのユースケース
- resourcesのユースケース
---
## 配置判断基準
- HTTP処理 → controllers
- ActiveRecordモデル(永続化) → models
- 画面表示 → views
- ビジネスルール(純粋ロジック) → domains
- ユースケースの流れ制御 → features
- DBに対する単純操作(ロジックなし) → resources
- 共通処理 → shared
---
## 禁止事項
- domainsにCRUDロジックを混ぜる
- controllerに業務ロジックを書く
- レイヤー内部を直接呼び出す
・「docs/rules/rails.md」(Rails実装のルール定義)
# Rails実装のルール定義
モジュラーモノリス + ドメイン駆動設計(DDD)を併用する
## 1. 目的
本ドキュメントはRailsにおける実装ルールを定義する。
アーキテクチャ判断は `architecture.md` と `boundaries.md` に従い、
本書は「Railsコードの書き方・制約」に特化する。
---
## 2. 基本原則
### 2-1. controllersは薄くする
- HTTP入出力のみ担当
- 業務ロジック禁止
- 必ずユースケース層を呼び出す
#### 許可される処理
- パラメータ取得
- 認証・認可の入口処理
- ユースケースの呼び出し
- レスポンス整形
#### 禁止
- 条件分岐による業務判断
- DB操作
- ドメインロジック
---
### 2-2. modelsは永続化専用
- ActiveRecordはデータ層として扱う
- ビジネスロジック禁止
- scope・validation・associationのみ許可
#### 禁止
- 業務ルール
- 計算ロジック
- ドメイン判断
---
### 2-3. domainsは純粋な業務ロジック
- ActiveRecordに依存しない
- 不変条件を保証する
- 副作用を外に出す
#### 特徴
- エンティティ
- 値オブジェクト
- ドメインサービス
---
### 2-4. domainsのuse_caseはアプリケーション制御
- トランザクション境界を持つ
- domainを組み合わせる
- repository経由でデータアクセス
#### 禁止
- UIロジック
- ActiveRecord直接操作(原則)
---
### 2-5. featuresは軽量ユースケース
- 単純な業務フローを扱う
- ActiveRecord利用OK
- 複雑化したらdomainへ移行
---
### 2-6. resourcesはCRUD専用
- 単純なデータ操作のみ
- ビジネス判断を持たない
- マスタ・設定・ログなど
---
## 3. 依存ルール
### 基本方針
依存は一方向のみ(上位 → 下位)
---
### 3-1. controllers
- controllers → domains/[domain_name]/use_cases
- controllers → features/[feature_name]/services
- controllers → resources
#### ルール
- controllerは業務判断を持たない
- HTTP入出力のみに責務を限定する
- domains/[domain_name] / features/[feature_name] / resourcesのどれを呼ぶかの判断のみ行う
---
### 3-2. models
- models(ActiveRecordのモデルを集約) → DB永続化専用
---
### 3-3. domains(中核の業務領域)
#### domain/*
- domains/*/domain → 無依存(完全独立)
- repositories
- domains/*/domain/repositories(interface)はインターフェース定義のみ
- 実装はdomains/*/infrastructure/repositories(implementation)
#### use_cases
- domains/*/use_cases → domains/*/domain
- domains/*/use_cases → domains/*/domain/repositories(interface)
#### infrastructure
- リポジトリの実装を行う
- domains/*/infrastructure/repositories(implementation) → models
- コマンド・クエリ責務分離(CQRS)設計とし、command(書き込み)とquery(読み取り)に分ける
---
### 3-3. features(補完的な業務領域)
- features/*/services → models
#### ルール
- 単純な業務フローのみ扱う
- 複雑化した場合はdomainsへ移行
---
### 3-4. resources(一般的な業務領域)
- resources → models
#### ルール
- 単純なCRUD処理
- ビジネスロジック禁止
---
### 3-5. shared(横断関心)
- shared → 全レイヤーから参照可能
---
### 3-6. 全体制約
#### domainの絶対ルール
- domainはRailsに依存しない
- domainはActiveRecordを知らない
- domainは純粋なビジネスロジックのみ
#### infrastructureルール
- infrastructure(repositories実装)はmodelsに依存する
- コマンド・クエリ責務分離(CQRS)設計とする
---
### 依存方向まとめ
#### 中核の業務領域
```
controller
↓
domains/*/domain/use_cases
↓
domain(entities / value_objects / services / repositories(interface))
↓
infrastructure/repositories(implementation)
↓
models(ActiveRecord実装)
```
#### 補完的な業務領域
```
controller
↓
features/*/services
↓
models(ActiveRecord実装)
```
#### 一般的な業務領域
```
controller
↓
resources
↓
models(ActiveRecord実装)
```
#### 共通処理
sharedは例外的に全方向参照可能
---
## 4. Rails特有の制約
### ActiveRecordの扱い
- domainsからは直接参照せず、repository経由でのみアクセスする
- featuresやresourcesは直接参照可能
- modelは純粋なデータ表現
---
### repositoryの責務分離(CQRS)
- Query Repository(読み取り専用)
- データ取得
- キャッシュ利用可能
- パフォーマンス最適化OK
- domainロジック禁止
- Command Repository(書き込み専用)
- 作成・更新・削除
- トランザクション管理の対象
- domainルールの反映
---
### コールバック禁止方針
- callbackに業務ロジックを書かない
- 副作用はユースケースに集約する
---
### Fat Model禁止
- modelにロジックを集約しない
- 複雑化した場合はドメインモデルへ移動
---
## 5. トランザクション管理
- ユースケース層が唯一のトランザクション境界
- featuresでは必要最小限にし、以下に該当したらdomainsへ移行する
- 条件分岐が増える
- 状態遷移(ステータス変更ロジック)が含まれる
- 複数のドメインルールが絡む
- ルール変更の影響範囲が広い
- ビジネス判断がコード内に現れ始める
- modelでは管理しない
---
## 6. 例外ルール
### 許可される例
- modelのバリデーション
- scopeによるクエリ
- 軽量なフォーマット処理(表示用途)
---
### 禁止される例
- 金額計算などの業務ロジック
- 状態遷移の判断
- 複雑な条件分岐
---
## 7. 設計判断基準
実装前に必ず判断する:
### 7-1. Q1: 複雑な業務ルールがあるか?
→ domains
### 7-2. Q2: 複雑な業務ルールはなく、処理フロー中心か?
→ features
### 7-3. Q3: 単純なCRUD処理や、外部サービスなどの共通処理か?
→ resource
### 7-4. Q4: 各レイヤーで共通利用するものか?
→ shared
---
## 8. エージェントルール
- 実装前に必ず配置先を決める
- controllerから設計を始めない
- domains または features または resource から設計を始める
- 判断に迷った場合は `boundaries.md` を参照すること
---
## 9. 禁止事項
- controllersへのロジック追加
- model肥大化
- domainsでの直接のActiveRecord使用
- featuresの無制限増殖
- ルールを無視した直書き実装
・「docs/rules/testing.md」(テストのルール定義)
# テストのルール定義
## 1. 基本方針
### 責務とテストの一致
- テストの責務境界をコード構造と一致させる
- 各レイヤーの責務 = テストの責務
- 「どこで何を保証するか」を明確にする
- 同一ロジックの重複検証は禁止
---
### テストピラミッド
- E2E(web / api):少量
- Integration(domains / features / resources):中量
- Unit(domains):最大(最も厚くする)
- requests(コントローラーのHTTPテスト)やE2Eは「壊れていないことの確認」に留める
---
### ビジネスロジックの責務
ビジネスロジックは性質ごとに責務を分離し、適切なレイヤーに集約する。
#### domains
- ビジネスの不変ルール(ドメイン知識そのもの)を担当する
- 例:計算ロジック、状態遷移の正当性、制約条件
- システムの「正しさの核」を担う
#### features
- ユースケース単位のビジネスフローおよび軽い判断ロジックを担当する
- 例:複数ドメインをまたぐ処理順序、条件分岐による処理選択
- ドメインルールそのものは持たず、オーケストレーションとアプリケーション判断を担う
- ドメインを利用しない範囲のユースケースを担当する
#### resources
- 単純CRUDなどの標準的なリソース操作を担当する
- ビジネス判断ロジックは持たず、処理の流れの確認に留める
#### 配置判断ルール
- 判断や分岐を伴う場合は features に配置する
- 判断を伴わない単純なCRUDは resources に配置する
- 複雑なビジネスルールが含まれる場合は domains に配置する
#### controllers / models
- ビジネスロジックは持たない
- controllers は I/O のみ
- models は永続化とデータ構造の表現のみに限定する
#### 上位レイヤーの責務
- 上位レイヤーは下位レイヤーの正しさに依存する
- ビジネスルールそのものは domains または features に集約する
### ActiveRecordの位置づけ
- models は永続化モデル(ORM)でありドメインではない
- ビジネスロジックは持たない
- データ構造の表現のみに限定する
---
## 2. specのディレクトリ構成
Railsのテストフレームワークとして「RSpec」を利用するが、`/spec`のテストとしては責務ベースでディレクトリを分離し、ドメイン駆動設計およびモジュラーモノリスの境界と一致させる。
### 基本方針
- レイヤー(unit / integration / requests / e2e)で大分類する
- その中で責務(domains / features / resourcesなど)を分割する
- ドメイン単位での分離を最優先する
- テストの配置はコードの責務境界と一致させる
---
### ディレクトリ構成
```
/spec
├── /unit(ユニットテスト)
| |
| ├── /models
| |
| ├── /domains
| | |
| | └── /domain_name
| | |
| | ├── /domain
| | | |
| | | ├── /entities
| | | |
| | | ├── /value_objects
| | | |
| | | └── /services
| | |
| | └── /use_cases
| |
| └── /shared
|
|
├── /integration(インテグレーションテスト)
| |
| ├── /domains
| | |
| | └── /domain_name
| | |
| | └── /use_cases
| |
| ├── /features
| | |
| | └── /[feature_name]
| | |
| | └── /services(サービス層)
| |
| |
| └── /resources
|
|
├── /requests(コントローラーのHTTPのテスト)
| |
| ├── /web
| |
| └── /api(将来的にAPIモードを利用する際に使う想定)
|
|
└── /e2e(E2Eテスト)
|
├── /web
|
└── /api(将来的にAPIモードを利用する際に使う想定)
```
---
### 設計意図
#### unit
- models / domains / shared を明確に分離する
- domainsについてはドメインロジックの純粋性を保証する層とする
- domains配下はDDD構造そのものを反映し、純粋なビジネスロジックのみを対象とする
#### integration
- 複数コンポーネントの結合を検証する層
- ドメイン単体などではなく、ユースケースなどの「流れ」を保証する
- featuresは業務機能単位の統合境界として扱う
- HTTPは使用しない(Request Specは禁止)
- サービス・ユースケースを直接呼び出して検証する
#### requests
- HTTP境界の検証に限定する
- Rails controllerの責務確認を目的とする
- ビジネスロジックは一切持たず、入出力の正当性のみを保証する
#### e2e
- ユーザー視点の最終保証レイヤー
- UI / APIを含めた全体フローを確認する
- カバレッジよりも主要シナリオの成立を重視し、最小限に保つ
---
### 命名ルール
- domain_name / feature_name はアプリケーションの業務ドメイン用語を使用する
- 実装クラス名ではなく「業務単位」でディレクトリを切る
- ディレクトリ構造とモジュール境界は一致させることを前提とする
### 補足ルール
- 同一責務のテストは必ず1箇所に集約する
- unit / integration / e2e 間で同じ検証を重複させない
- domains配下が最も安定した設計境界となることを前提とする
---
## 3. レイヤー別テスト定義
### domains(中核の業務領域のレイヤー)
**方針**: 最も重要なテスト層。全ビジネスルールを保証
**ルール**
- ドメインモデル(VO / Entity / Domain Service)は Unit テストで保証する
- 原則: 純粋ロジック(DB/HTTPなし)
- 通常は `require "rails_helper"` を使用してよい
- 高速化したい場合は `require "spec_helper"` のみで実行してよい
- ドメインのユースケースは Integration テストで「処理の流れ」を保証する
- `require "rails_helper"` の利用を許可する
- 必要に応じて ActiveRecord/DB を使ってよい(I/O込みの結合検証)
- 同一ロジックの重複検証は禁止(どこで何を保証するかを明確にする)
**必須**
- 境界値テスト
- 異常系テスト
- 不変条件の検証
- 1テスト1ルール
**禁止(Unit に限定)**
- ActiveRecord使用
- FactoryBot使用
---
### features(補完的な業務領域のレイヤー)
**方針**: ユースケースの流れを検証、ドメインを使うような複雑性はない機能の動作確認
**ルール**
- Integrationテスト
- DB使用可
- サービス単位で検証
**必須**
- 1ユースケースにつき
- 正常系1つ
- 主要な失敗系のみ
**禁止**
- 複雑な検証
- 分岐網羅
- 過剰なモック
---
### resources(一般的な業務領域のレイヤー)
**方針**: 単純なCRUD処理などを検証
**ルール**
- APIは Request Spec(統合テスト)、Viewは System Spec(E2Eテスト) を使用する
- 1つのリソースにつき「代表的な正常系フロー」を中心に検証する
- CRUDは個別に網羅するのではなく、「一連の操作の流れの中で確認する」
- 認証・認可・決済などの横断的関心を含めて検証する
- テストはクライアント(API)またはユーザー(View)視点で記述する
- ビジネス判断を持たないことを前提とする
- 判断が発生した時点で features へ移動する
**必須**
- 登録 → 認証 → 操作 などの主要フローが成立すること
- 認証・認可が正しく機能すること(未認証・権限違いの最低限の確認)
- リソースの作成・更新・削除のうち、少なくとも1つはフロー内で通すこと
- 正常系のエンドツーエンド動作が通ること
**禁止**
- バリデーションの網羅的テストを書くこと
- 分岐ロジック(条件ごとの挙動)を細かく検証すること
- すべてのCRUDパターンをE2Eで個別にテストすること
- 失敗ケースを過剰に書くこと(詳細は下位レイヤーで担保)
- テストケースを増やしすぎること(フロー単位で最小限に抑える)
---
### models(永続化レイヤー)
**方針**: DB構造と永続化のみ保証
**ルール**
- Model Specを使用
- DB前提
**検証対象**
- validation
- association
- scope
- simple callback(最小限)
**必須**
- DBとの整合性
- クエリ結果の正しさ
**禁止**
- ビジネスロジック
- 複雑ロジック
- ドメイン知識
---
### controllers
**方針**: I/Oのみ検証
**ルール**
- Request Specを使用
- HTTPステータス
- JSON構造
- 認証・認可
**必須**
- レスポンススキーマのみ検証
**禁止**
- ビジネスロジックの結果検証
- DB状態の詳細検証
---
### views(UI)
**方針**: ユーザー体験のみ確認
**ルール**
- System Spec(E2E)を使用
- 主要フローのみ
**必須**
- 文言完全一致に依存しない
- HTML構造に依存しすぎない
---
## 4. 横断ルール
### 4.1 責務ごとのテスト配置
| 検証対象 | 配置場所 |
|----------|----------|
| 複雑なビジネスルール | domains |
| ビジネスフロー(ユースケース) | features |
| 単純なCRUD・リソース操作 | resources |
| DB構造・バリデーション | models |
| API入出力(HTTP境界) | controllers(request spec) |
| UI体験(ユーザー操作) | views(system spec) |
- 同一内容の重複テストは禁止
---
### 4.2 モック使用ルール
**許可**
- 外部API
- 時刻
- UUID
- メール送信
**禁止**
- domainオブジェクト
- ActiveRecord
- 自作クラス同士
**原則**
- モックは外部境界のみに限定
---
### 4.3 テストデータ(FactoryBot)
| レイヤー | 使用可否 |
|----------|----------|
| domains | 原則禁止(例外的に可) |
| features | 可 |
| models | 可 |
| resources | 可 |
| controllers | 可 |
**ルール**
- 最小構成で生成
- traitで意図明示
- letのネスト禁止
- domainsでは可能な限りPORO(Plain Old Ruby Object)でテストする
---
### 4.4 トランザクション
- 各テストは独立
- テスト間依存禁止
- DBは毎回ロールバック
---
### 4.5 命名ルール
- 業務用語で記述
- 条件と結果を明確にする
```ruby
describe "create order" do
context "when stock is enough" do
it "creates order"
end
context "when stock is insufficient" do
it "raises error"
end
end
```
---
## 5. TDD・推奨フロー
### TDDルール
- Red → Green → Refactor
- テストなし実装禁止
### 推奨フロー
- domain → use_case → controller
- domainから開始する
- controllerから始めない
## 6. アンチパターンと対策
| アンチパターン | 対策 |
|----------|----------|
| features肥大化 | domainへ移動 |
| controllerにロジック | requestを薄く |
| domainが薄い | ロジックを集約 |
| fat model | domainへ移動 |
| FactoryBot乱用 | trait整理 |
---
## 7. 追加推奨・レビュー観点
### 推奨
- カバレッジよりも重要なユースケース・分岐の網羅性を重視する
- テストは「仕様として意味があるか」を基準に設計する(カバレッジは補助指標)
### レビュー観点
- 責務とテスト対象が一致しているか
- domainに寄せるべきロジックが適切に切り出されているか
- テストが冗長・重複していないか
- ActiveRecordに過剰なビジネスロジックが混入していないか
- 重要な分岐・例外系が落ちていないか
## まとめ
- 複雑なビジネスロジックは可能な限りdomainに集約する
- modelsは永続化を主責務とし、必要最小限のロジックのみ持つ
- テストは責務ごとに分離する
- 上位は薄く、下位は厚くする
- 配置に迷った場合は「ビジネス判断があるか」で判断する
・「src/AGENTS.md」(Rails専用のルール定義)
# Rails専用のルール定義
## 概要
このディレクトリ(src)はRails実装の「実行領域」であり、
設計判断はすべて docs/rules 側に集約されている。
src内では設計判断を行わず、既存ルールを適用するのみとする。
---
## Railsの設計思想(重要)
本プロジェクトはRailsの思想である
**「設計より規約(Convention over Configuration)」を強く採用する。**
そのため以下を前提とする:
- 明示的な設計よりも、規約(Rails標準・docs/rules)を優先する
- 個別判断やカスタム設計は原則として禁止する
- 「設計を考えること」自体をsrcでは行わない
---
## 規約と設計の関係
本プロジェクトにおける「規約」とは以下を指す:
- Railsのフレームワーク規約
- `docs/rules/*` に定義されたプロジェクト規約
これらは実質的に**設計そのものの代替物**であり、
srcはそれを機械的に適用するだけの層である。
---
## ルール参照構造
すべての実装は以下のルールに従う:
- `docs/rules/architecture.md`(設計思想)
- `docs/rules/boundaries.md`(配置判断)
- `docs/rules/rails.md`(Rails実装ルール)
- `docs/rules/database.md`(データ制約)
- `docs/rules/testing.md`(テスト方針)
---
## src配下の責務
srcは「実装のみを行う領域」であり、
以下の責務に限定される:
- MVC構造の具体的実装
- モジュラーモノリス構造のコード配置
- `docs/rules/rails.md` に従った実装
---
## 実装ルール(重要)
srcでは以下を行ってはならない:
- ルールの解釈や再定義
- 設計判断
- 技術選定の追加判断
実装は常に docs/rules を唯一の判断基準として適用すること。
---
## このディレクトリの役割
- Railsコードの実装専用領域
- MVC構造の具体的なコード表現
- モジュラーモノリス構造の物理実装
---
## 禁止事項
- src配下に設計判断を書くこと
- domains / features / resourcesの定義を再説明すること
- database設計方針を記述すること
- テスト戦略を記述すること
- docs側のルールを上書きすること
---
## エージェントの振る舞い
- 判断はすべて docs/rules に従う
- srcは「適用のみ」を行う
- 迷った場合は `docs/rules/boundaries.md` を最優先で参照する
- 「どう設計するか」は考えない
- 「どの規約に従うか」だけを選択する
- 規約が曖昧な場合のみ docs/rules 側に遷移する
---
## 補足(重要)
srcは「設計を実装する場所」ではなく
**「規約をコードに写像する機械である」**
---
## 実装後の必須チェック(重要)
コード修正・追加が一段落した場合、エージェントは必ず以下のコマンドを順番に実行し、
警告・エラーが存在しない状態を維持すること。
### コマンド一覧
#### 1. フォーマット修正(レイアウトのみ自動修正)
`docker compose run --rm app bundle exec rubocop -A --only Layout`
---
#### 2. 静的コード解析(Rubocop)
`docker compose run --rm app bundle exec rubocop`
---
#### 3. ビューLint(ビュー変更時のみ)
※ app/views に変更があった場合のみ実行
`docker compose run --rm app bundle exec erb_lint app/views`
---
#### 4. 脆弱性チェック(Brakeman)
`docker compose run --rm app bundle exec brakeman --no-pager`
---
#### 5. テスト実行(RSpec)
`docker compose exec -T app bundle exec rspec`
---
### 実行ルール
- 上記は「実装完了後に必ず順番に実行する」
- エラー・警告がある状態で完了としてはならない
- フォーマット(Layout)のみ自動修正を許可する(rubocop -A --only Layout)
- 上記以外の rubocop の自動修正(-A)は使用してはならない
- rubocop の指摘は自動修正に依存せず、必ずコード側で修正する
- テストが失敗している状態で終了してはならない
- すべてのチェックが通過するまで修正と再実行を繰り返す
---
### 位置づけ
これらのチェックは「設計判断」ではなく、
**規約の適用結果を検証する工程**である。
したがって src の責務に含まれる。
※実装に関しては、Railsの設計思想「設定より規約」を重視した方がAI駆動開発との相性がいいだろうと想定しています。
・「AGENTS.md」(全体のルール定義)
# 全体のルール定義
## 概要
本プロジェクトはマルチエージェント構成(Codex Agents)を前提とする。
以下のエージェントが `.codex/agents` に定義されており、
すべての開発はこれらの役割分担に従って実行される。
---
## エージェント構成
### 利用エージェント
- pm
- 要件整理・仕様の定義
- ユーザーストーリー作成
- タスク分解および実行順序の決定
- 必要に応じた軽量な設計判断(実装詳細には踏み込まない)
- tester
- テスト設計(REDフェーズ)
- テストコード作成
- 期待仕様の定義
- implementer
- 実装(GREENフェーズ)
- `rails.md`に従ったコード記述
- テストを通すための実装のみを行う
- reviewer
- コードレビュー
- 設計逸脱の検出
- 品質・構造の検証
---
## ワークフロー
開発は必ず以下のTDDフローに従う:
- `.codex/workflows/tdd_flow.md`
---
### 補足
各エージェントは `tdd_flow.md` に定義された順序とルールに従い、
自分の責務範囲内で処理を実行すること。
---
## ルール参照構造
エージェントは実装判断を行う前に以下を参照する:
### 全体アーキテクチャ
- `docs/rules/architecture.md`
### コード配置・境界
- `docs/rules/boundaries.md`
### Rails専用ルール
- `src/AGENTS.md`
- 実装の詳細は `docs/rules/rails.md` を参照
### データベース設計
- `docs/rules/database.md`
### テスト設計
- `docs/rules/testing.md`
---
## ルール優先順位
矛盾が発生した場合は以下の優先順位で解決する:
1. `boundaries.md`(配置判断)
2. `architecture.md`(設計思想)
3. `src/AGENTS.md`(Rails構造ルール)
4. `docs/rules/rails.md`(Rails実装ルール)
5. `database.md`(永続化制約)
6. `testing.md`(テスト方針)
---
## エージェントの責務原則
### 共通ルール
- 各エージェントは自分の責務外の判断を行わない
- 設計と実装は必ず分離する
- TDDフローをスキップしない
---
### 責務分離
- pm:仕様決定・分解・進行管理(実装禁止)
- tester:テストのみ(実装禁止)
- implementer:実装のみ(設計判断禁止)
- reviewer:検証のみ(修正実装禁止)
---
## TDD制約(重要)
- REDなしで実装を開始してはならない
- GREEN未達の状態でレビューを行わない
- reviewer NGの場合は必ずimplementerに戻る
- テストは仕様の唯一の正解として扱う
---
## 禁止事項
- 本ファイルに実装ルールを書くこと
- エージェント間の責務を曖昧にすること
- TDDフローを省略すること
- reviewerが実装修正を行うこと
今回のRailsのディレクトリ構成について
今回のRailsのディレクトリ構成はモジュラーモノリスおよびドメイン駆動設計(DDD)を前提に設計していますが、アプリケーション全体に対してDDDを全面的に適用することは、本質的ではないケースも多く、実装・運用コストも高くなりがちです。
また、モジュラーモノリスやDDDを強く意識した設計は、Railsが本来持つシンプルさや生産性といった利点からは一定程度離れることにもなります。
そこで本構成では、Railsの持つ開発効率の良さと、DDDによるドメインの明確化という両方の利点を活かすために、両者を組み合わせたハイブリッドなアプローチを採用しています。
具体的には、システムを以下の3つの業務領域に分類することを前提としています。
- 中核の業務領域
- 補完的な業務領域
- 一般的な業務領域
このうち、ビジネス上の競争優位性に直結する「中核の業務領域」に対してのみDDDを適用し、それ以外の領域についてはRailsの標準的な構成やシンプルな設計を採用します。
これにより、重要なドメインには十分な設計投資を行いつつ、全体としては過度に複雑化しないバランスの取れた構成を目指しています。
ハーネス設計の注意点
上記では様々なドキュメントを定義してハーネス設計を行なっていますが、それぞれのドキュメントは完璧なものではありません。
もし実務でハーネス設計をする必要がある場合は、それぞれのプロジェクトに応じて最適なハーネス設計をするようにして下さい。
そしてその際には、システム開発におけるあらゆる知識(アーキテクチャ、設計、言語やフレームワーク、実装方法、AIツールの使い方など)がないと良し悪しが判断できないのと、プロジェクトに応じてどうするべきかの決断を迫られることもあると思うので、その点は注意が必要です。
ハーネスエンジニアリングは、システム開発におけるほぼ全工程をある程度できる人じゃないと整えられない仕事(上流工程しかできない人には無理、コードは書かなくなってもコードの実装知識は必要)だなというのが、自分で試してみてよくわかりました。
また、これらのドキュメントは一回作って終わりではなく、適宜改善して育てていく必要性もあると思うので、その点も注意しましょう。
GitHub ActionsによるCIの導入
次にCI/CDを組み込むのも試しておきたいですが、今回は本番環境などは利用しないため、CIだけ導入するのを試します。
CI(Continuous Integration:継続的インテグレーション)は、開発者が書いたコードをこまめにまとめて、自動でテストやビルドを行い、「ちゃんと動くか」をすぐ確認する仕組みです。
CD(Continuous Delivery Deployment:継続的デリバリー・デプロイメント)は、テスト済みのコードを本番環境にリリースできる状態にしたり、場合によっては自動で本番に反映する仕組みです。
また、今回はコード管理にGitHubを利用しているので、相性がいいGitHub Actionsを利用してCIを導入していきます。
まずは以下のコマンドを実行し、設定用のファイルを作成します。
$ mkdir -p .github/workflows && touch .github/workflows/ci.yml
次に作成したファイルを以下のように記述します。
name: CI
on:
pull_request:
push:
branches:
- main
jobs:
# 変更ファイル判定(全体トリガー)
changes:
runs-on: ubuntu-latest
outputs:
app: ${{ steps.filter.outputs.app }}
steps:
- name: リポジトリをチェックアウト
uses: actions/checkout@v6
- name: 差分チェック
uses: dorny/paths-filter@v4
id: filter
with:
filters: |
app:
- 'src/**/*.rb'
- 'src/**/*.erb'
- 'src/Gemfile*'
# 静的コード解析・脆弱性チェック
lint:
needs: changes
if: needs.changes.outputs.app == 'true'
runs-on: ubuntu-latest
steps:
- name: リポジトリをチェックアウト
uses: actions/checkout@v6
- name: 環境変数ファイルをリネーム
run: cp ./.env.example ./.env
- name: Dockerコンテナのビルド
run: docker compose build
# 静的コード解析
- name: Rubocop
run: docker compose run --rm app bundle exec rubocop
# ビュー用の静的コード解析
- name: ERB Lint
run: docker compose run --rm app bundle exec erb_lint app/views
# Railsの脆弱性チェック
- name: Brakeman
run: docker compose run --rm app bundle exec brakeman --no-pager
# テスト
test:
needs: changes
if: needs.changes.outputs.app == 'true'
runs-on: ubuntu-latest
steps:
- name: リポジトリをチェックアウト
uses: actions/checkout@v6
- name: 環境変数ファイルをリネーム
run: cp ./.env.example ./.env
- name: Dockerコンテナのビルド
run: docker compose build
- name: Dockerコンテナの起動
run: docker compose up -d
- name: DB接続待機処理
run: docker compose exec app bash -c "until pg_isready -h db -U ${DB_USER}; do sleep 1; done"
- name: DB作成とマイグレーションの実行
run: docker compose run --rm app bundle exec rails db:prepare
- name: テストの実行(RSpec)
run: docker compose exec -T app bundle exec rspec
※起動条件はプルリクエスト(PR)作成時か、mainブランチへのプッシュやマージ実行時です。加えて対象ファイルの差分変更を検知して各種処理を実行させてます。「actions/checkout@v6」や「dorny/paths-filter@v4」はnodeのバージョンが上がった際にバージョンを上げる必要がでる可能性があります。尚、将来的にテストが多くなって完了時間が長くなった場合は、テストの並列実行などの検討が必要になったりします。
これでPR作成時やmainブランチにマージするタイミングでCIが実行されます。
もしCIをスキップしたい場合は、コミットメッセージの先頭に「[skip ci]」または「[ci skip]」を付けるとスキップ処理が可能です。
作成したプロジェクトをGitHubのリポジトリに登録
次に上記で作成したプロジェクトをGitHubのリポジトリに登録します。
まずは以下のコマンドを実行し、コミット処理まで完了して下さい。
$ git add -A
$ git commit -m "add harness"
コミット完了後、GitHubのリポジトリ一覧画面を開き、画面右上の「New」をクリックします。

リポジトリ作成が表示されるので、リポジトリ名を入力し、リポジトリのタイプを選択後、画面右下の「Create repository」をクリックします。

リポジトリ作成後、画面下に実行用コマンドが表示されるので、コマンドを実行してプロジェクトをリポジトリにプッシュします。

プッシュ完了後、プロジェクトが反映され、かつGitHub Actionsも起動します。
GitHub Actionsを確認するには、メニュー「Actions」をクリックします。

Actions画面で実行したワークフロー一覧が表示されるので、対象のワークフローをクリックします。

対象のワークフローの詳細を確認でき、全て緑色のチェックが付いて正常終了すればOKです。

※今回は全て完了するのに1分17秒かかりました。
mainブランチなどの保護設定をしたい場合
実務などではmainブランチの保護設定が必要になったりしますが、その場合はリポジトリのメニューから「Settings」画面を開き、画面左のメニュー「Branches」を選択後、Branch protection rules画面が開くので、「Add branch ruleset」をクリックします。

次にRuleset Nameを入力後、Enforcement statusを「Active」に変更し、Target branchesの項目にある「Add target」から「Include by pattern」を選択します。
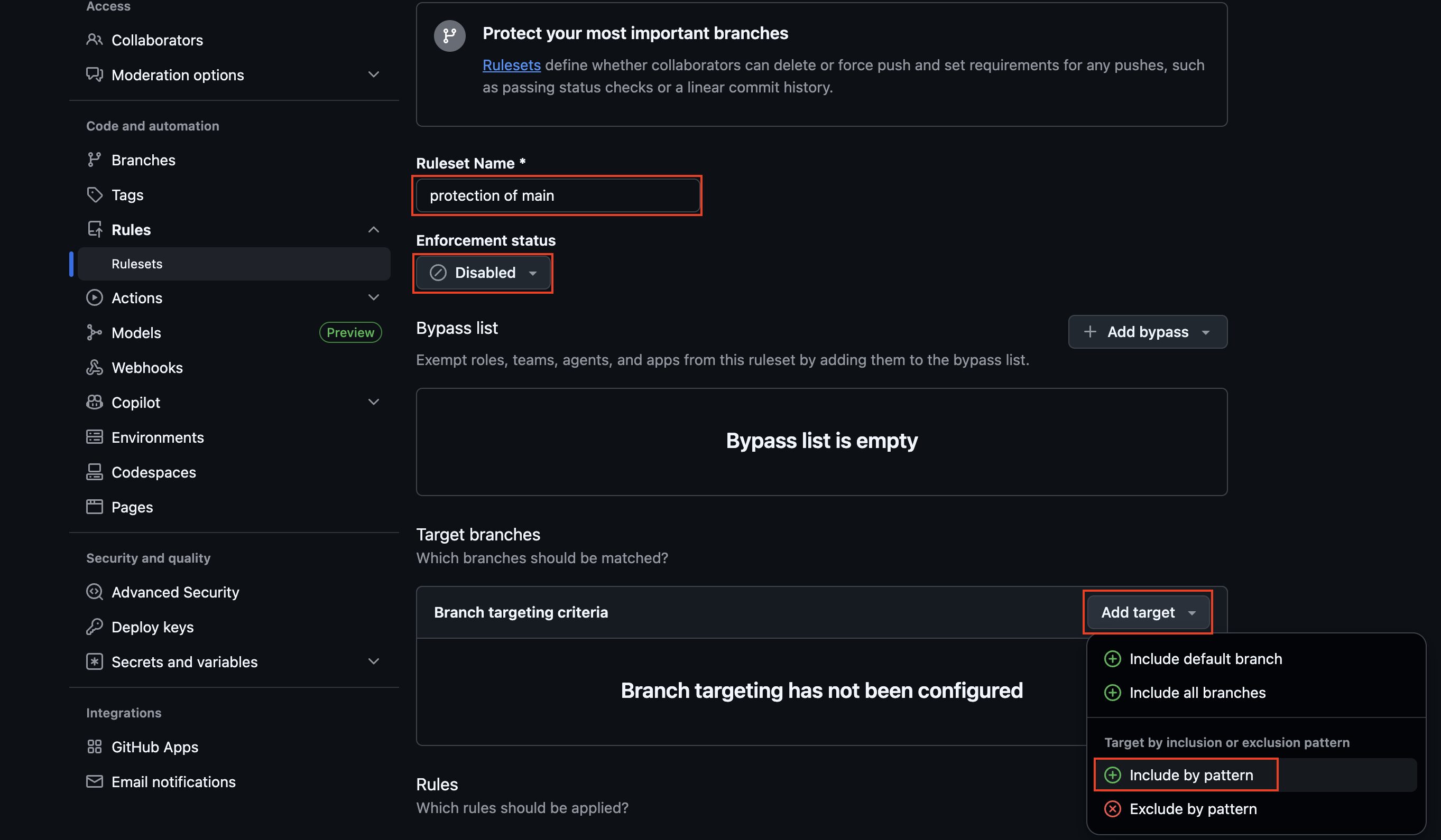
次にポップアップが表示されるので、「main」を入力して「Add Inclusion pattern」をクリックします。
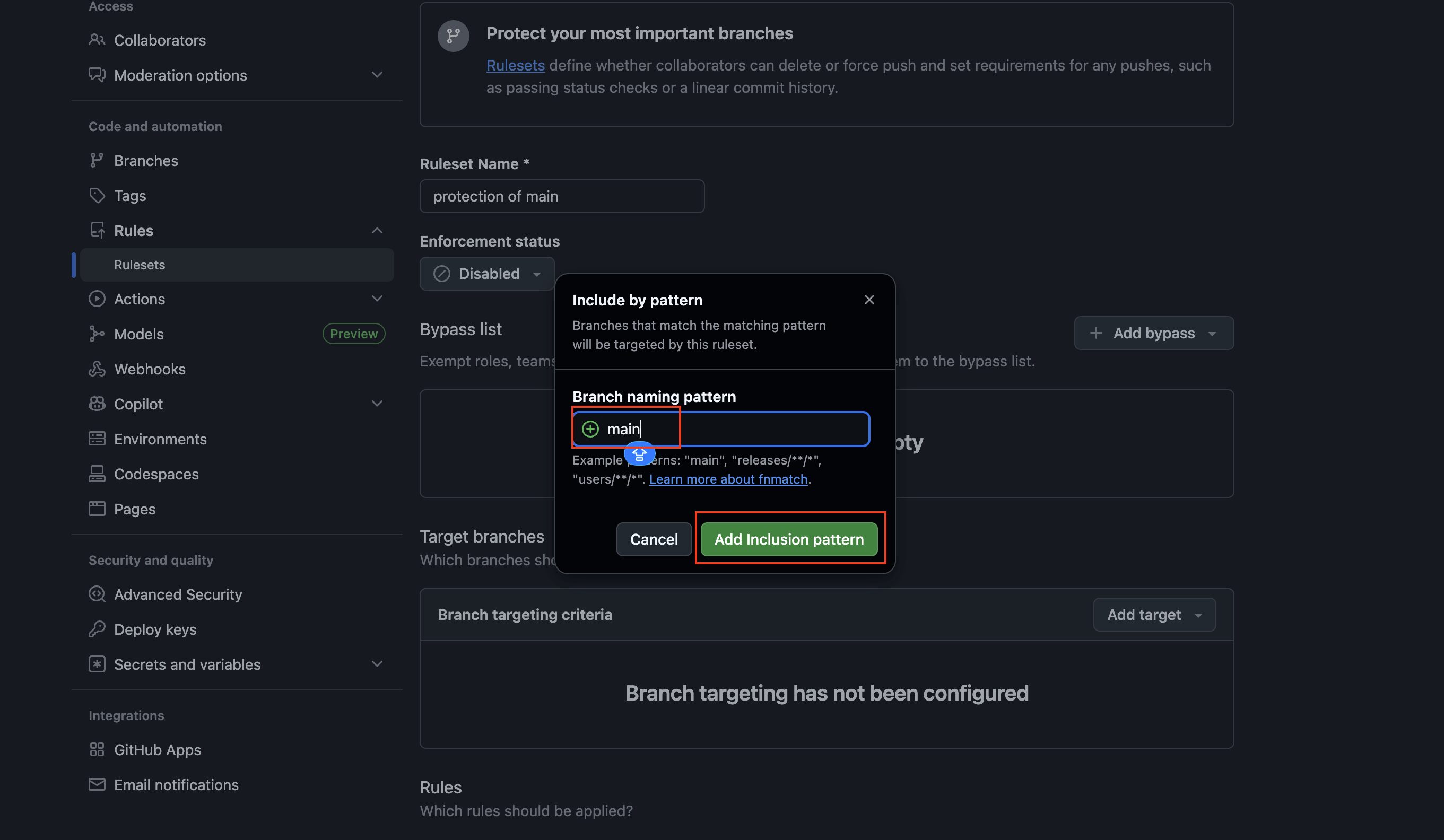
これでTarget branchesの項目に対象のブランチ名「main」が設定されます。
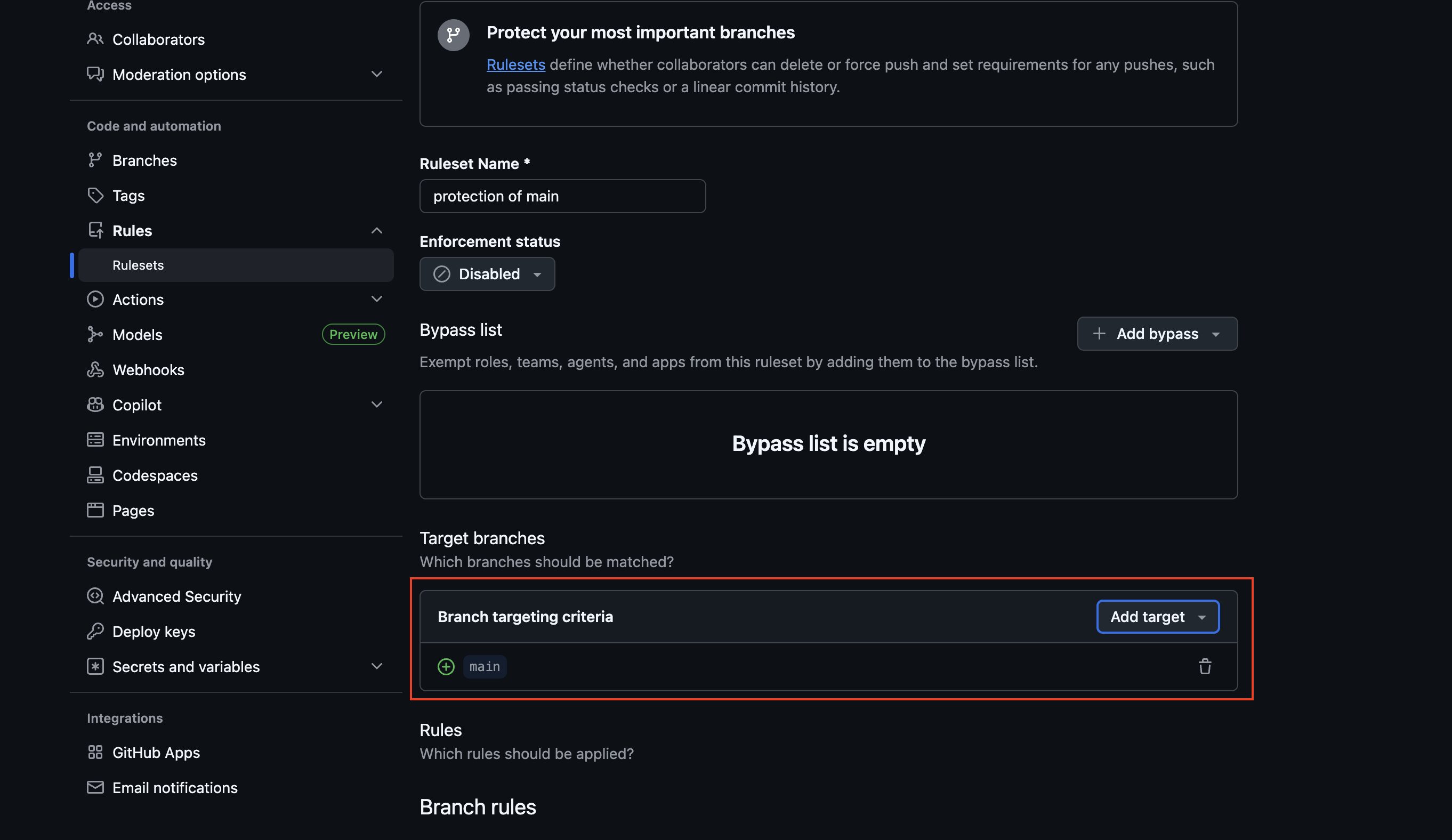
次にマージする前にプルリクエストを必須にしたい場合は、「Require a pull request before merging」のチェックを付け、必要に応じてオプションを設定して下さい。
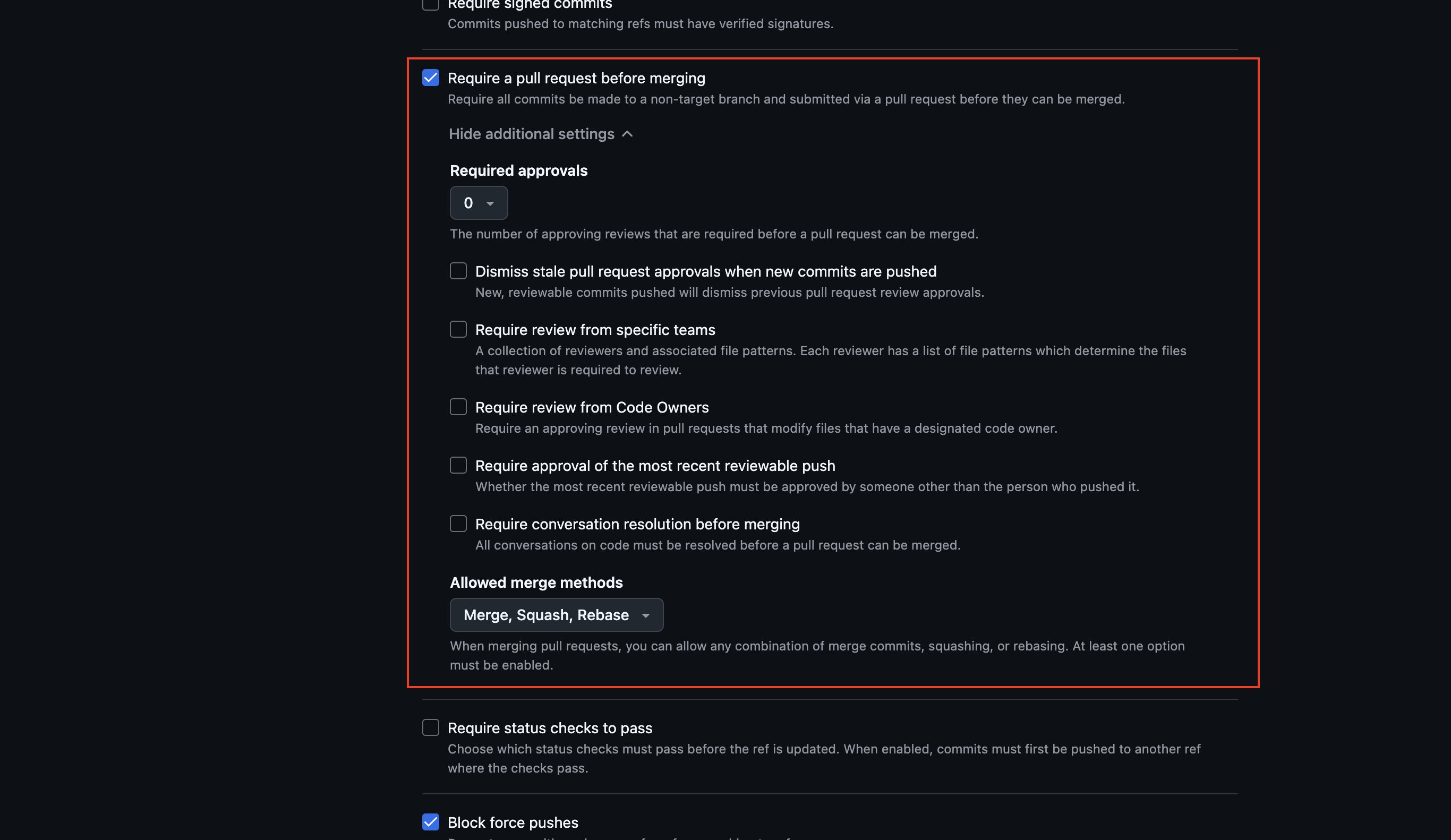
次にCIをPASS(正常終了)することを必須にしたい場合は、「Require status checks to pass」のチェックを付け、必要に応じてオプションを設定し、「Add checks」のリストからCIの対象のジョブを検索してチェックを付けて下さい。
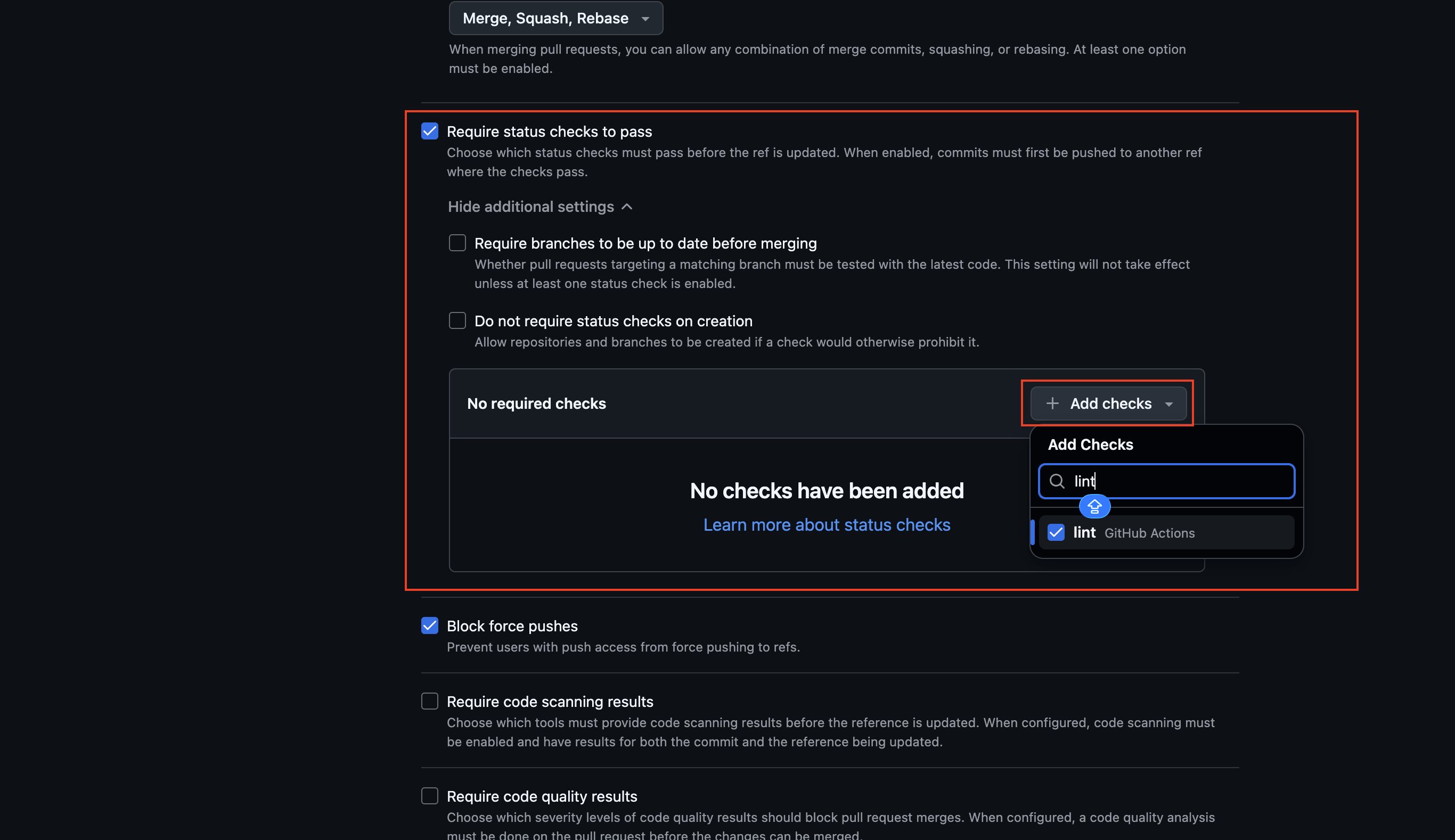
対象のジョブを選択後、下図のように対象のジョブが表示されればOKです。

全ての設定完了後、画面下の「Create」をクリックします。

次に認証を求められるので、認証をして下さい。
※私はパスキー認証にしています。
これでブランチ保護設定が完了です。今回は一例ですが、他にも色々条件が付けられるので、必要に応じて任意のものを設定して下さい。

OpenAI「Codexアプリ」のプランモードで開発計画を立てる
次にAIツールとしてOpenAIの「Codexアプリ」を使い、プランモードを用いて簡単な機能を追加する開発計画を立ててみます。
ただし、今回はAIツールとのやりとり回数を少なくしたいので、事前にある程度考えておいた機能の仕様を投げる形で進めます。
関連記事
・OpenAI Codex CLI / Codexアプリの使い方【ChatGPT時代のAI開発ツール入門】
では今回追加してみる機能としては、日本の有名人の名言を「今日の一言」としてトップページの中央にいい感じに表示させる機能を作ります。
特に「今日の一言」を決める部分には簡単なロジックを持たせるようにして、名言ドメインとして主に以下のような仕様とします。
・追加機能の仕様まとめ
# 追加機能の仕様
## 名言ドメインの仕様
### 1. エンティティ「Quote」
名言ドメインのエンティティ
属性:
- id:Quoteの識別子(主キー / bigint)
- quote_text:値オブジェクト「QuoteText」
- 値オブジェクトはバリデーションの責務を持つ
---
### 2. 値オブジェクト「QuoteText」
名言の本文を表す値オブジェクト
制約:
- 使用可能文字:
- 全角ひらがな
- 全角カタカナ
- 漢字
- 長音「ー」
- 「。」(句点)
- 「、」(読点)
- 使用不可文字:
- 英数字
- スペース
- 記号(括弧・!・?など含む)
- 正規表現でバリデーションする
正規表現の例:
```
/\A[ぁ-んァ-ヶ一-龥ー。、]+\z/
```
---
### 3. ドメインサービス「QuoteSelector」
「今日の一言」を決定するドメインサービス
役割:
- 日付と名言マスタから1件のQuoteを選定する
選定ロジック:
- 対象日付の「年内日数(day_of_year)」を取得
- quotes数で割った余りを算出
- そのindexのQuoteを返す
例:
```
index = date.yday % quotes.count
```
不変条件:
- 同じ日付 → 必ず同じ結果
- quotesが同じなら結果は完全に決定論的
- うるう年は考慮しない(ydayをそのまま使用)
例外:
- quotesが0件の場合はエラーとして例外を返す
### 4. ユースケースの処理フロー
1. quote_historiesに今日の日付があるか確認
2. あればそれを返す
3. なければ:
- QuoteSelectorで選定
- quote_historiesに保存
- 返却
---
## データベースの仕様
### 1. 名言マスタテーブル「quotes」
| カラム | 型 | 説明 |
| --- | --- | --- |
| id | bigint | PK |
| text | string | 名言本文 |
| created_at | datetime | |
| updated_at | datetime | |
### 2. 名言履歴テーブル「quote_histories」
| カラム | 型 | 説明 |
| --- | --- | --- |
| id | bigint | PK |
| date | date | 対象日(UTC日付)、ユニークキーとする |
| quote_id | bigint | 名言マスタのid |
| created_at | datetime | |
| updated_at | datetime | |
---
### 3. 名言マスタの登録値
| id | 名言 |
| --- | --- |
| 1 | 必死に生きる生涯は光を放つ |
| 2 | 我事において後悔せず |
| 3 | 天は人の上に人を造らず人の下に人を造らず |
| 4 | 成功は失敗の積み重ね |
| 5 | 小さなことの積み重ねが遠くへ行く道 |
| 6 | いい作品はいい人生から生まれる |
| 7 | 映画は自分の手でつくるもの |
| 8 | 遠回りは無駄ではない |
| 9 | 人を相手にせず天を相手にせよ |
| 10 | 人は成功するために努力する |
---
## UIの仕様
- トップページ中央に1件表示
- 表示例:`本日の一言:〇〇〇〇〇`
- レスポンシブデザインであること
- CSSにはTailwindCSSを利用する
- 全体的なデザインは落ち着きがあっていい感じにしたい
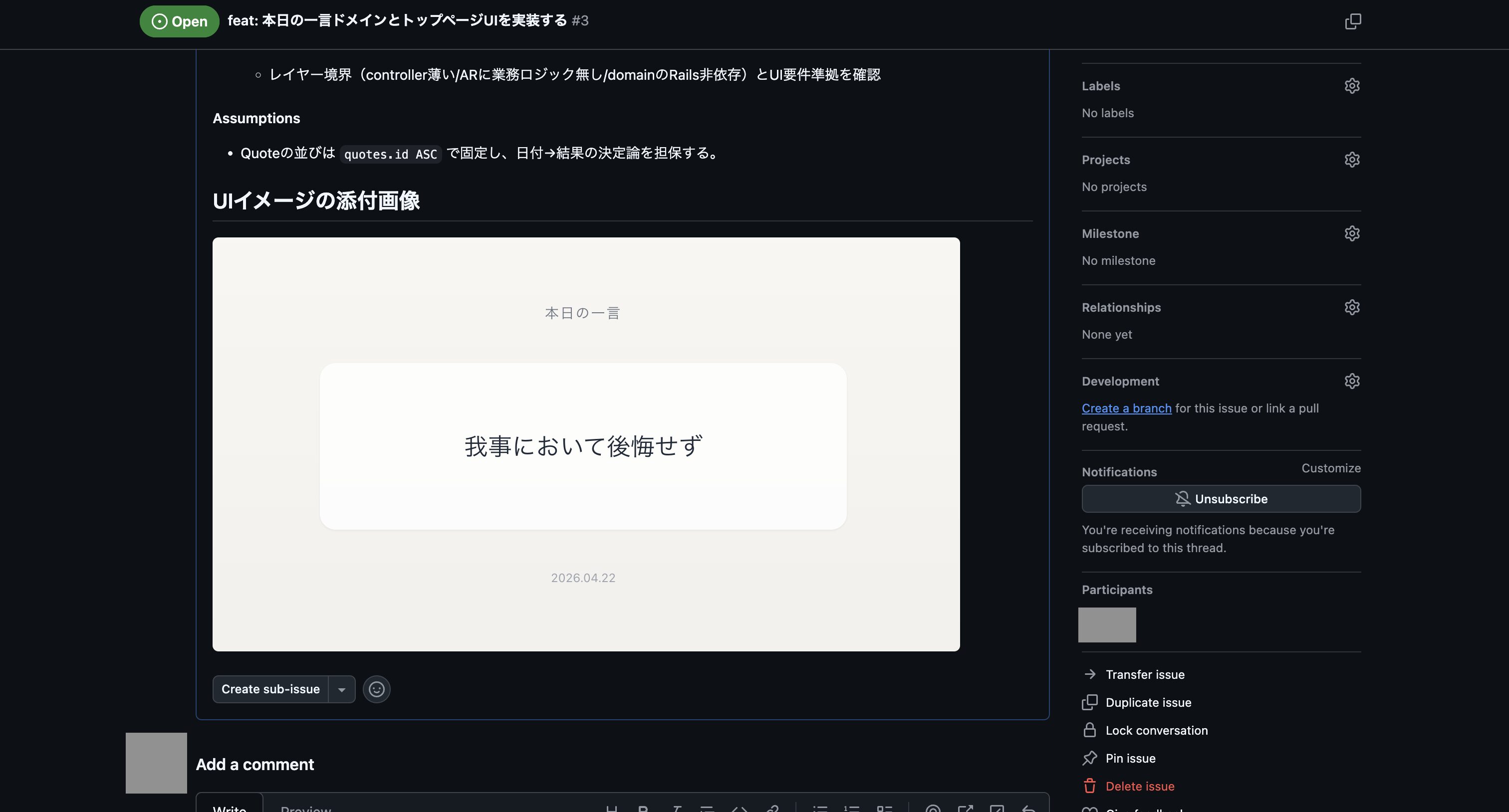
・UIのイメージ画像

ではこの追加機能の仕様を使いながら、「Codexアプリ」のプランモードを試します。
まずはアプリ起動後、画面左のメニューにあるプロジェクトの右側にあるボタン「新しいプロジェクトを追加」をクリックし、対象のディレクトリ(今回の例ではrails-aiddです)を開きます。

対象のプロジェクトを開いたあと、チャット欄の左下にある「+」からプランモードをONにします。

これでプランモードの準備ができたので、以下のメッセージ時に加えて、上記に記載した追加機能の仕様を全てコピペし、チャット欄の右側にある「↑」をクリックして実行します。
・メッセージ
「今日の一言」をトップページの中央にいい感じに表示させるだけの簡単なアプリを作りたいです。
現在の仕様は以下になるので、これをまとめた上で、確認点があれば質問して下さい。

実行後、上記で事前に設定したハーネス設定のファイルを最初に読み込んでから、チャット欄に入力した命令を実行してくれます。

実行途中で質問がある場合は聞かれますが、QuoteSelectorの選定ロジックについては「yday%count」を選択しました。

次に今日の日付の基準については選択肢ではなく、「「今日」の基準はDBにはUTC日付で保存し、トップページに表示する際はJST日付にして下さい。」を入力しました。

次にquotesが0件の場合については、「例外をそのまま500」を選択しました。

次に日付が切り替わる境界については、「JSTで切替 + UTC表記で保存」を選択しました。

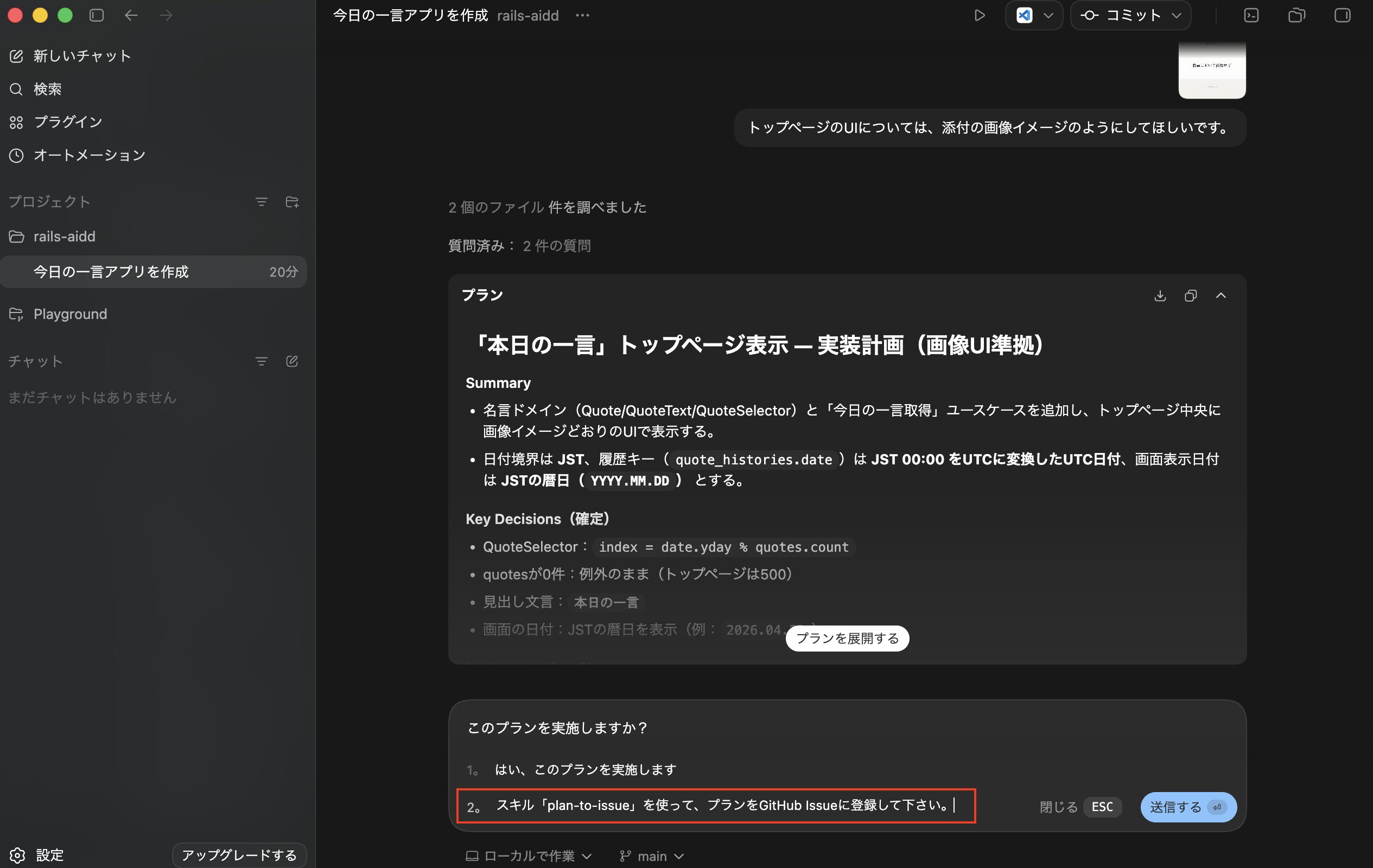
全ての質問の対応が完了後、以下のようにプランが作成されました。
ここでは一度チャット欄の「閉じる」をクリックして閉じます。

次にUIのイメージ画像もプランに入れて欲しかったので、メッセージ「トップページのUIについては、添付の画像イメージのようにしてほしいです。」と共に画像ファイルを添付して実行します。

次に追加の質問として日付に付いて聞かれたので、「JSTの暦日」を選択しました。

次に見出しのテキストについて聞かれたので、「本日の一言」を選択しました。

全ての質問の対応が完了後、以下のように再度プランが作成されました。

スキル「plan-to-issue」を使ってプランをGitHub Issueに登録
次に作成したプランを事前に作成しておいたスキル「plan-to-issue」を使ってGitHub Issueに登録するのを試します。
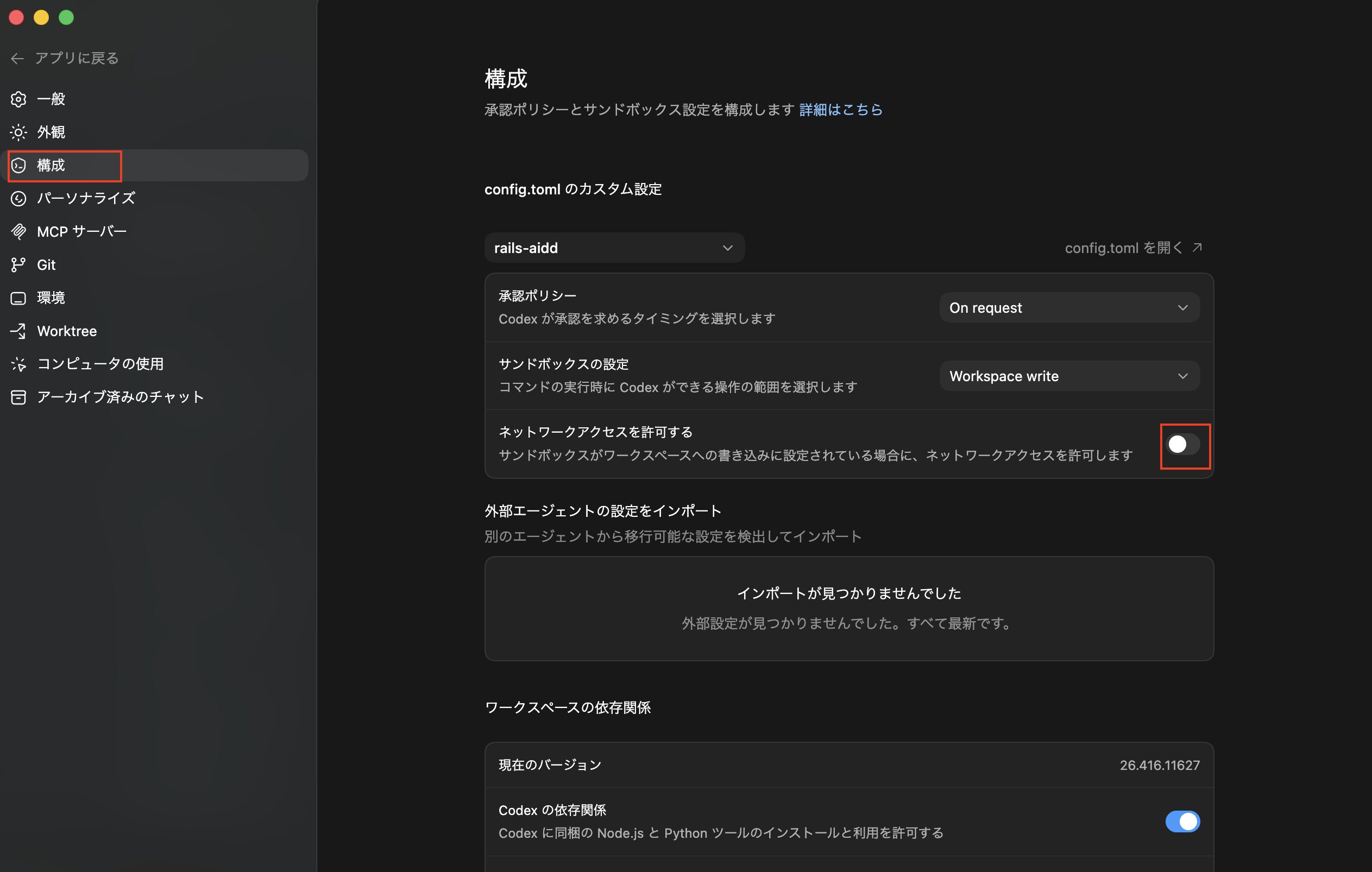
ただし、スキル「plan-to-issue」の中で使っているコマンドはネットワーク通信が必要になるので、Codexアプリの設定画面から構成を開き、ネットワークアクセスを許可するを一時的に許可します。
※サンドボックスのデフォルト設定ではネットワークアクセス許可がOFFです。ONにするとネットワーク通信が可能ですが、その分プロンプトインジェクションのリスクも上がるため、必要な時以外はOFFにしてAIツールを利用するようにして下さい。
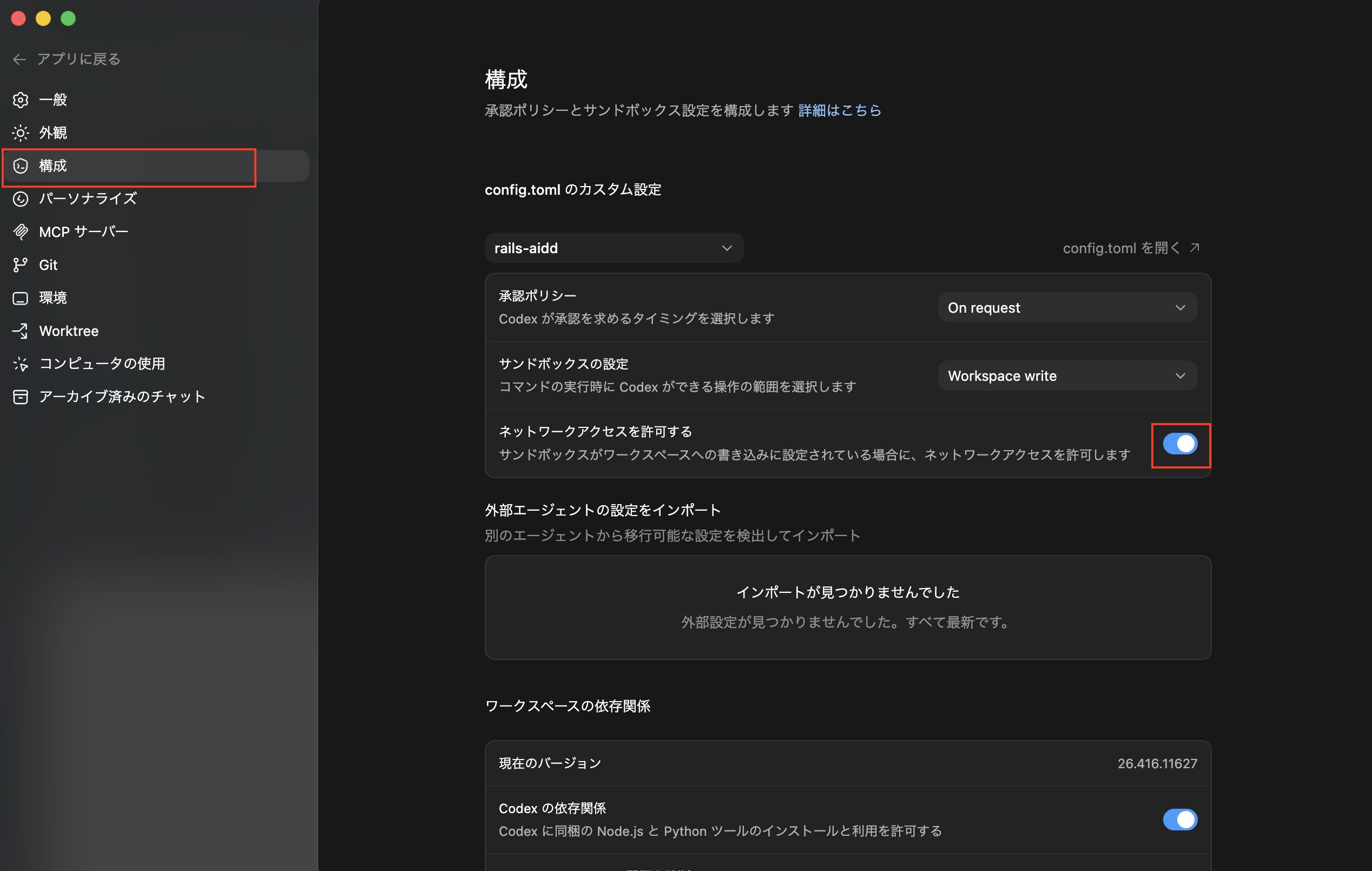
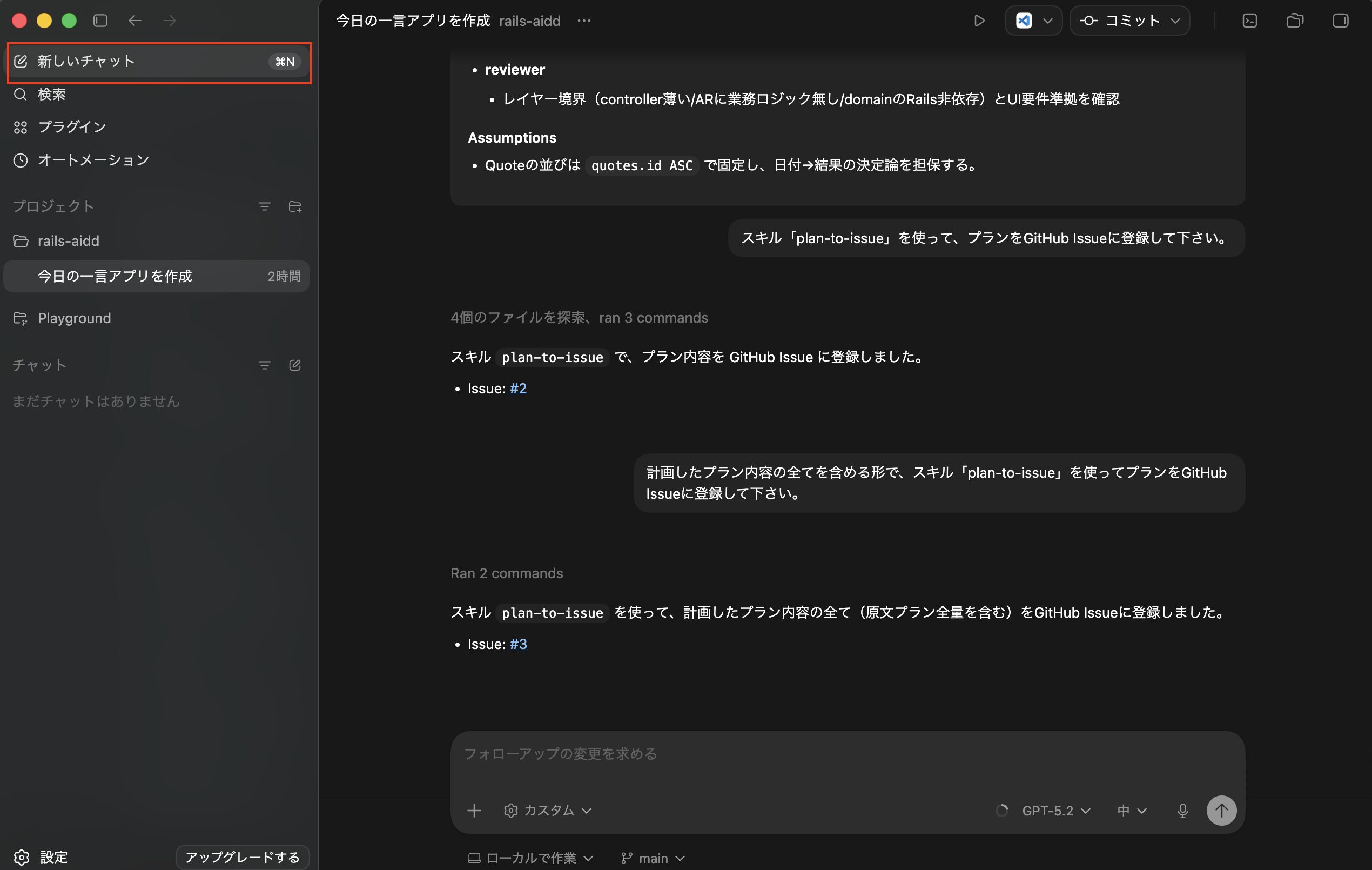
次にチャット欄に「スキル「plan-to-issue」を使って、プランをGitHub Issueに登録して下さい。」を入力して実行します。
実行して完了後、以下のようにIssueが登録できました。
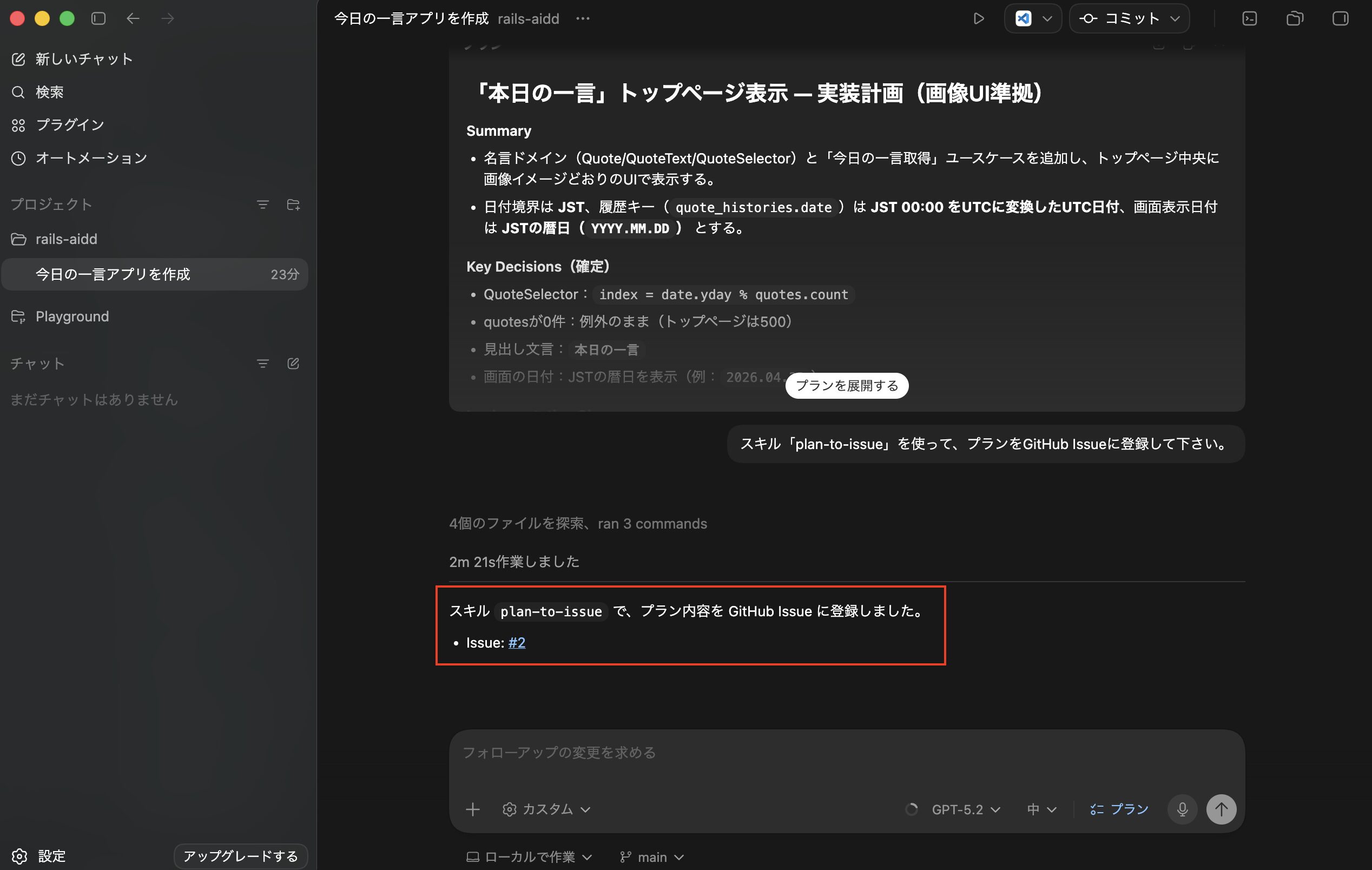
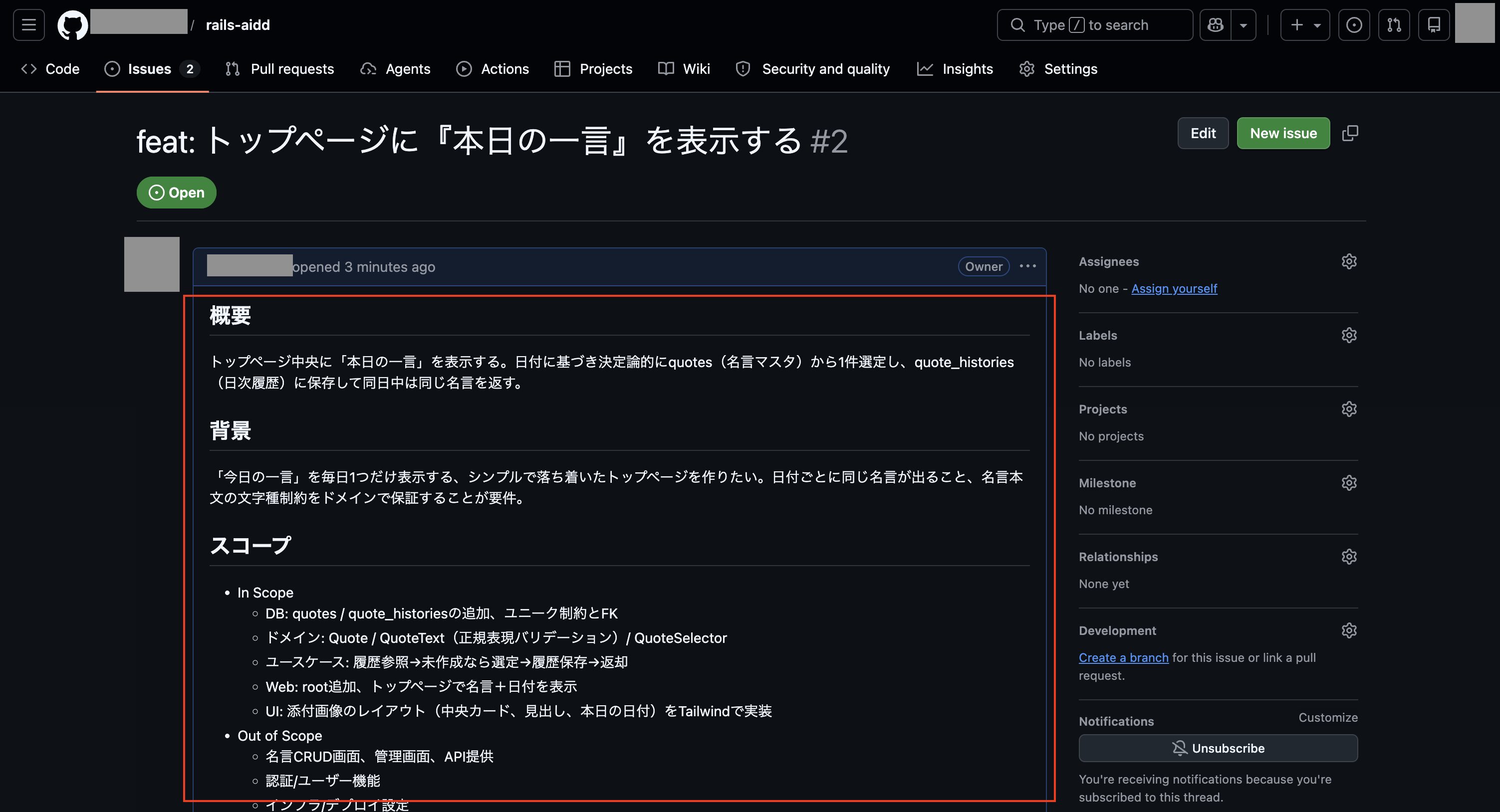
次にGitHubの方で登録されたIssueを確認しましたが、残念ながら事前に作成しておいたスキル「plan-to-issue」の作りが悪く、プラン内容が少し要約される形になってしまっていました。
なので、次はチャット欄に「計画したプラン内容の全てを含める形で、スキル「plan-to-issue」を使ってプランをGitHub Issueに登録して下さい。」を入力して実行し、再度GitHub Issueの登録を行いました。
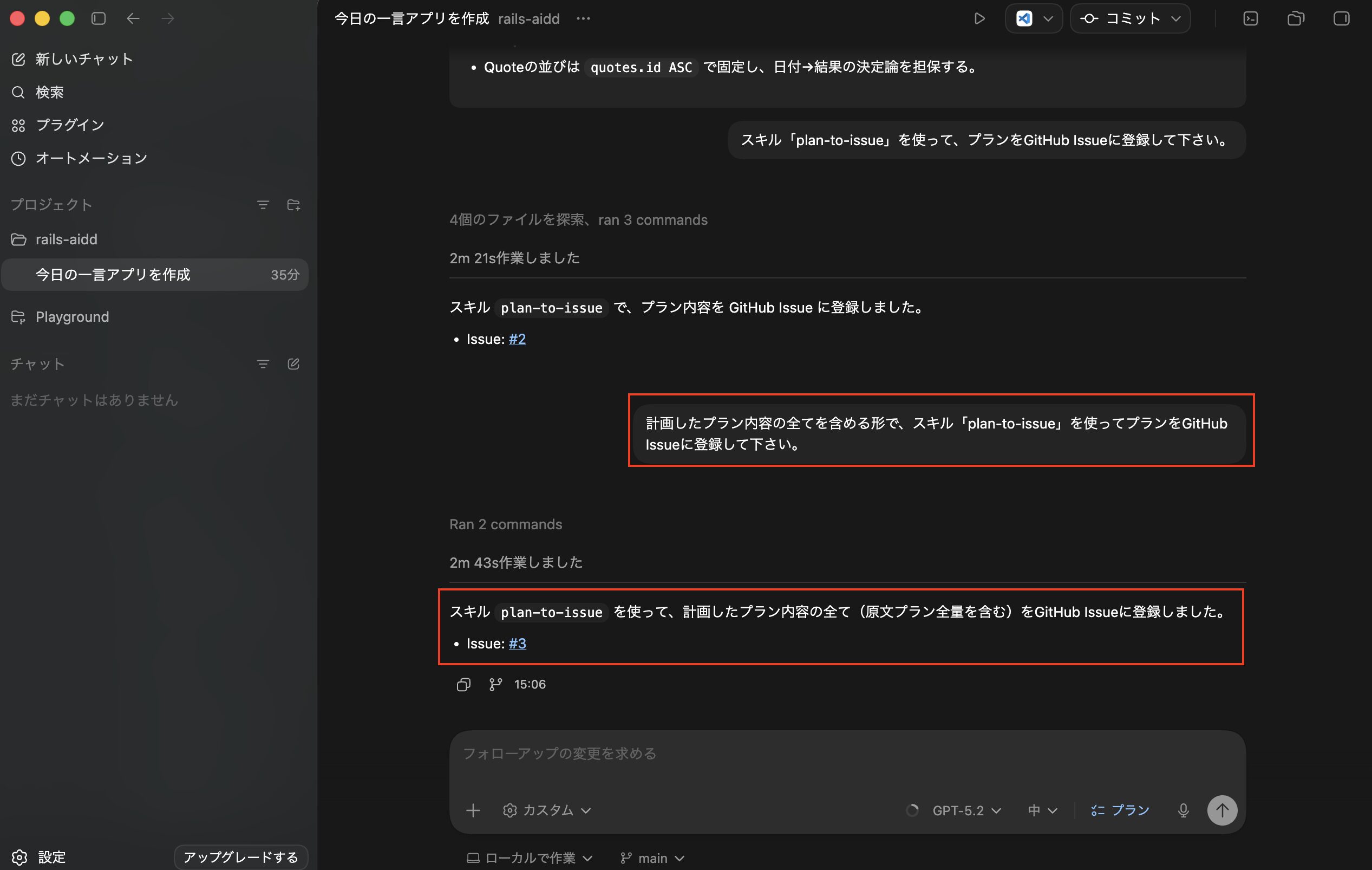
これで登録されたIssueの内容が以下になります。
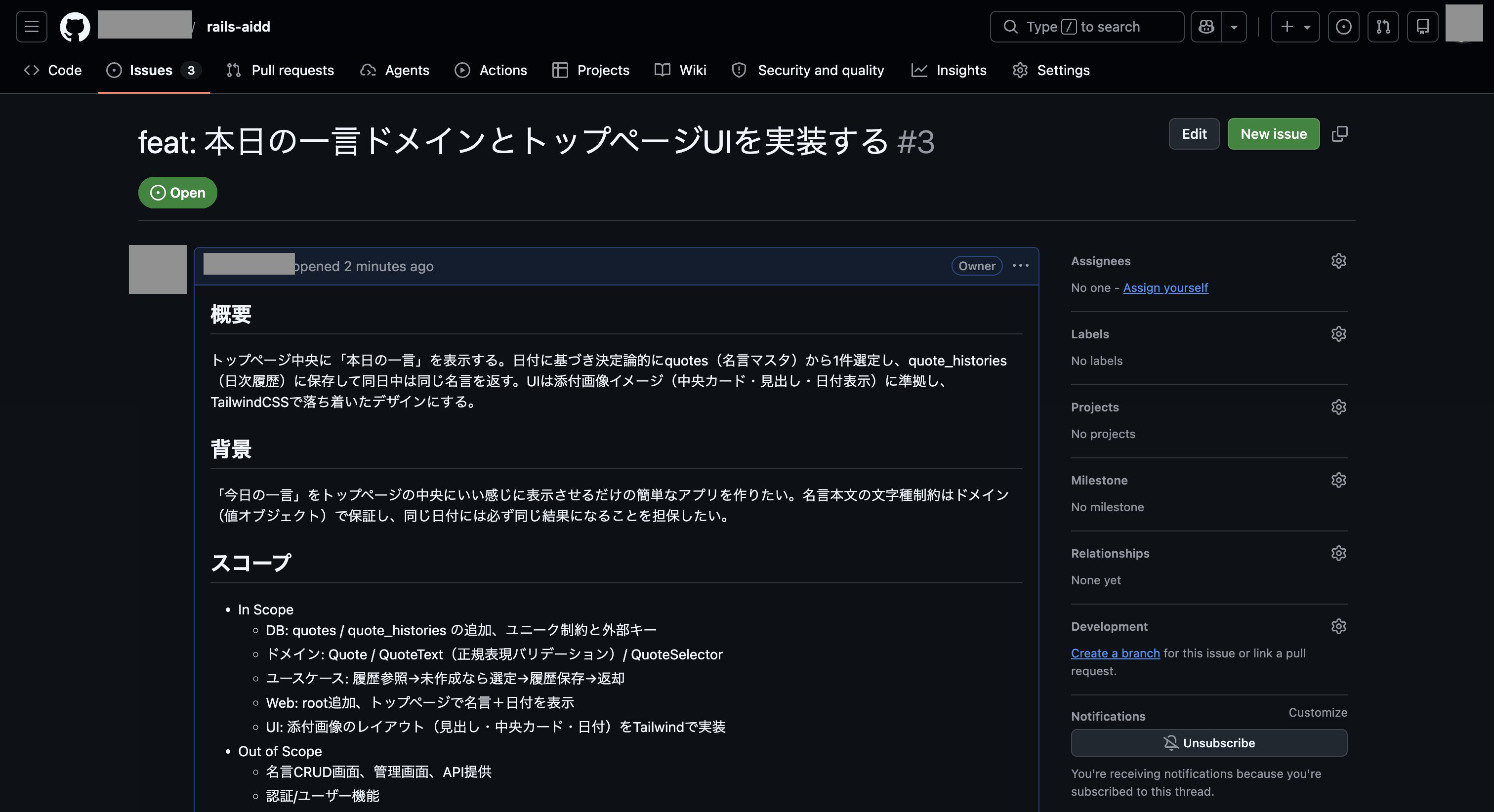
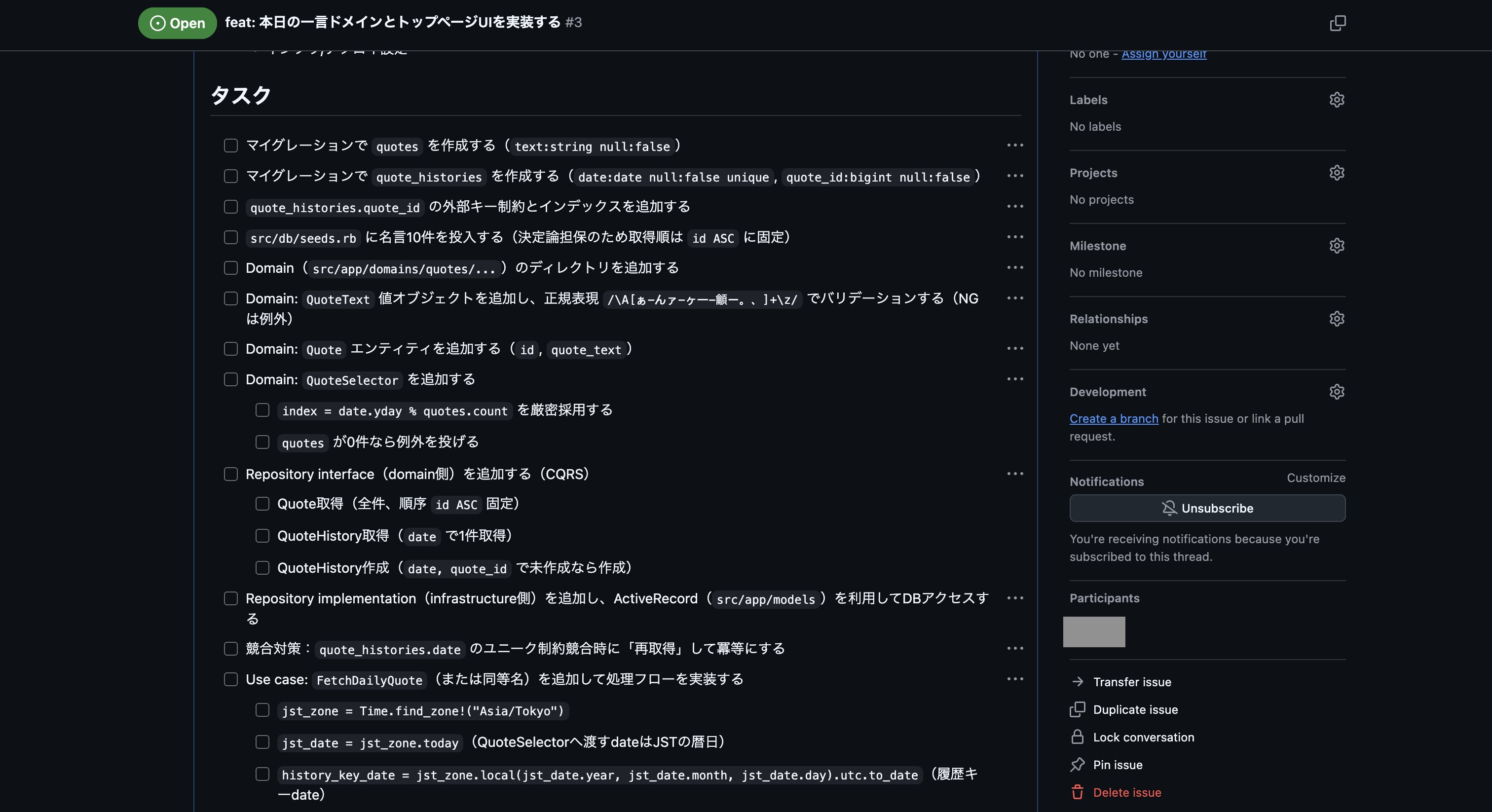
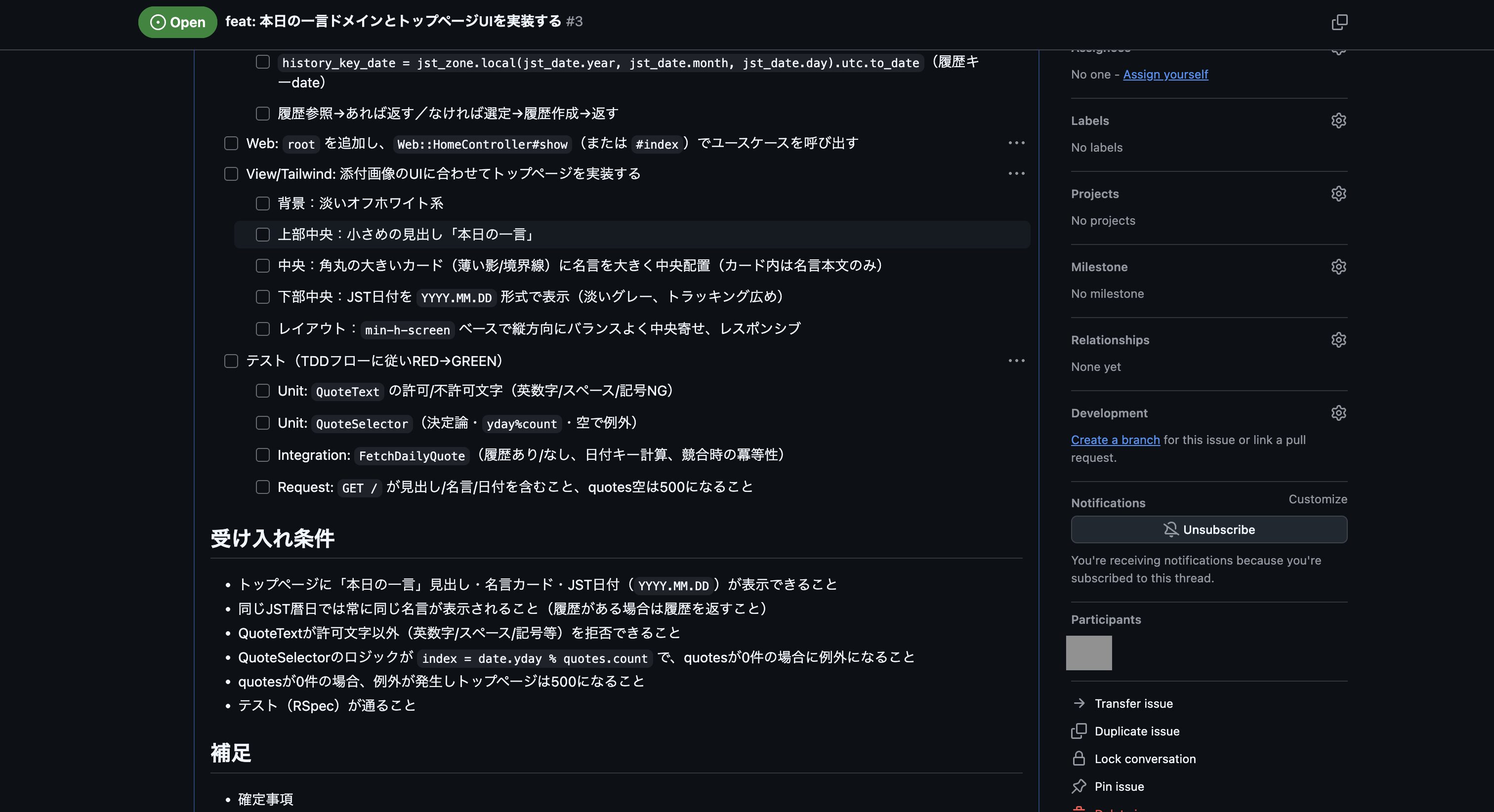
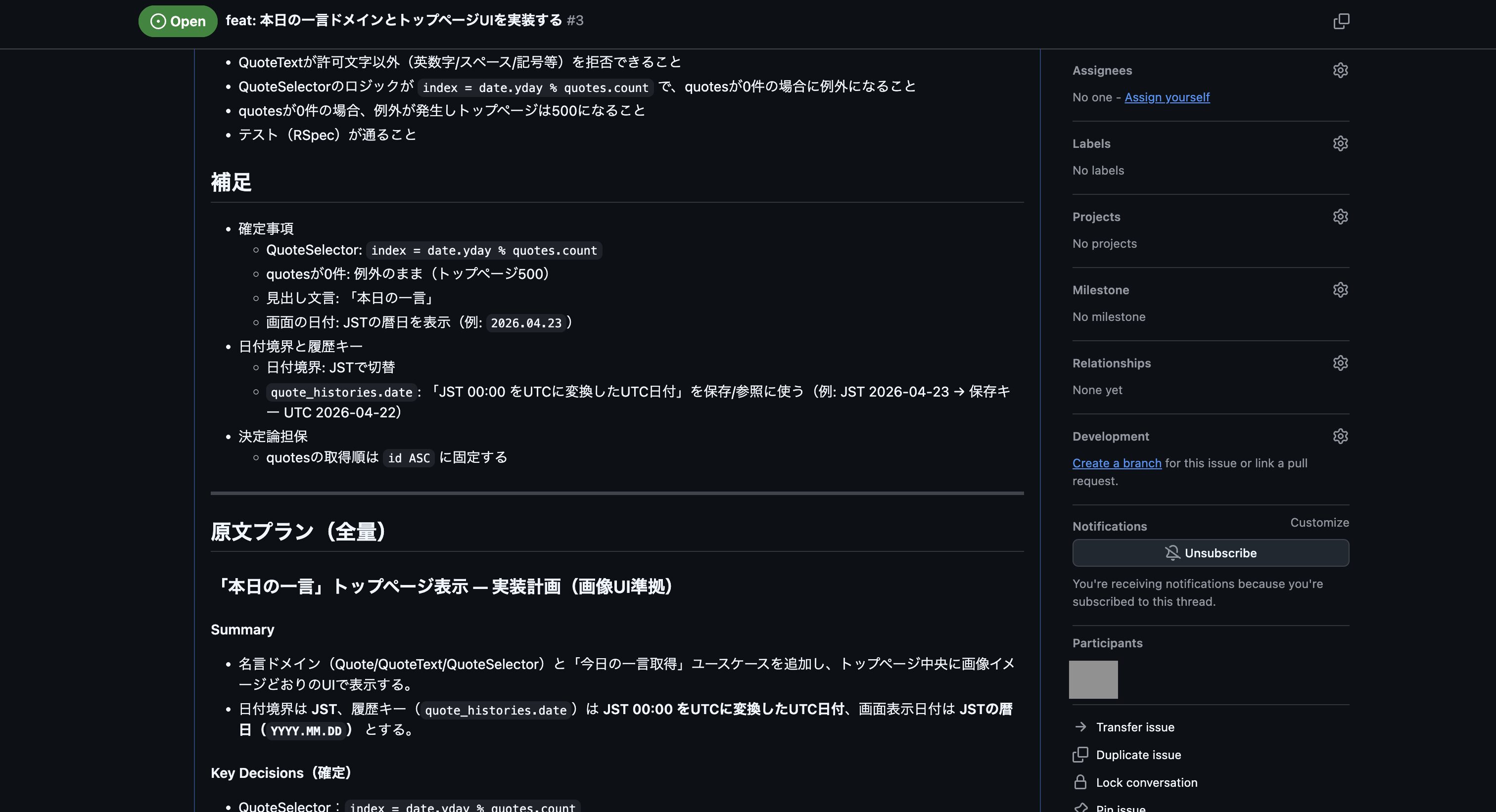
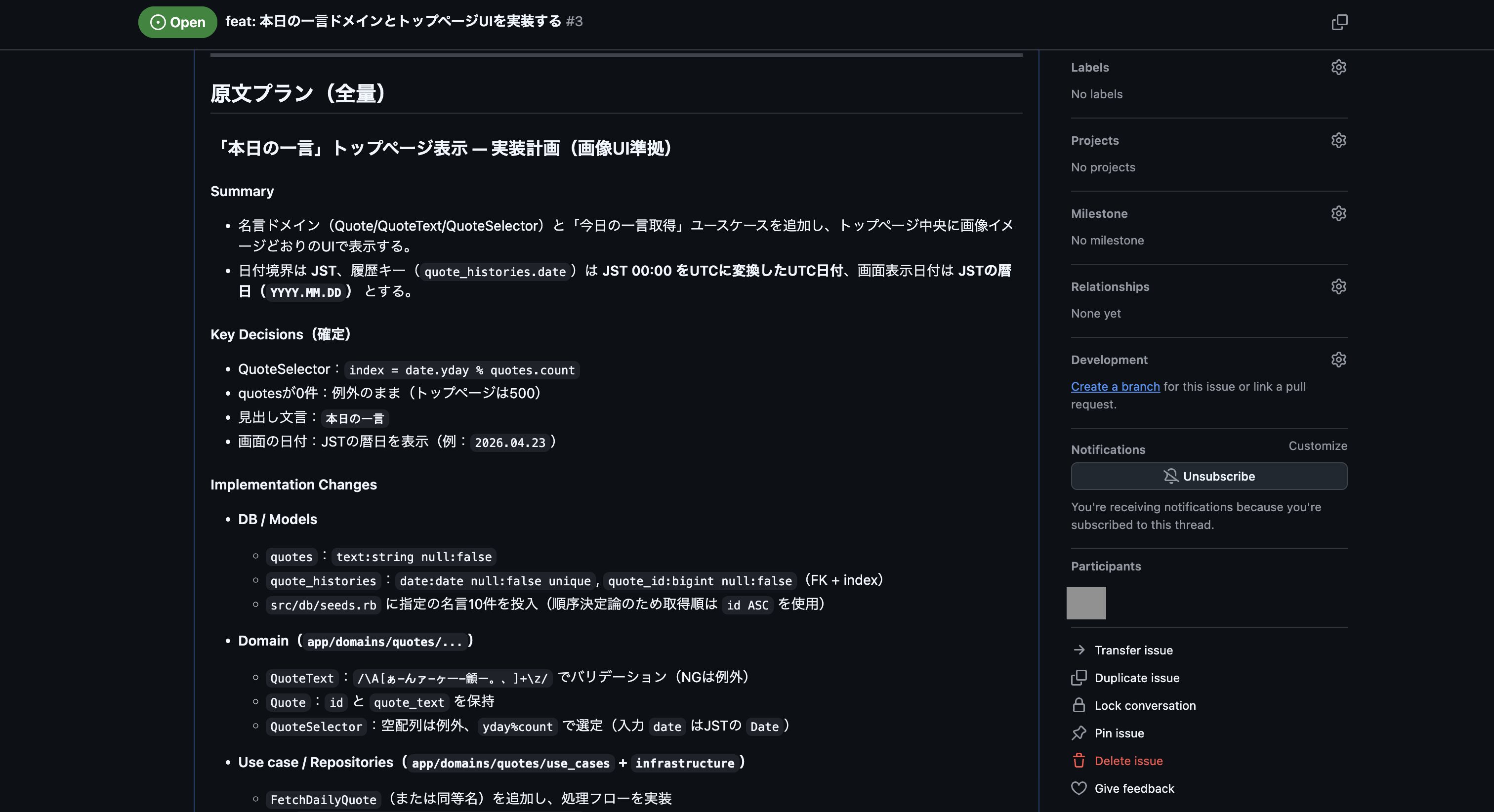
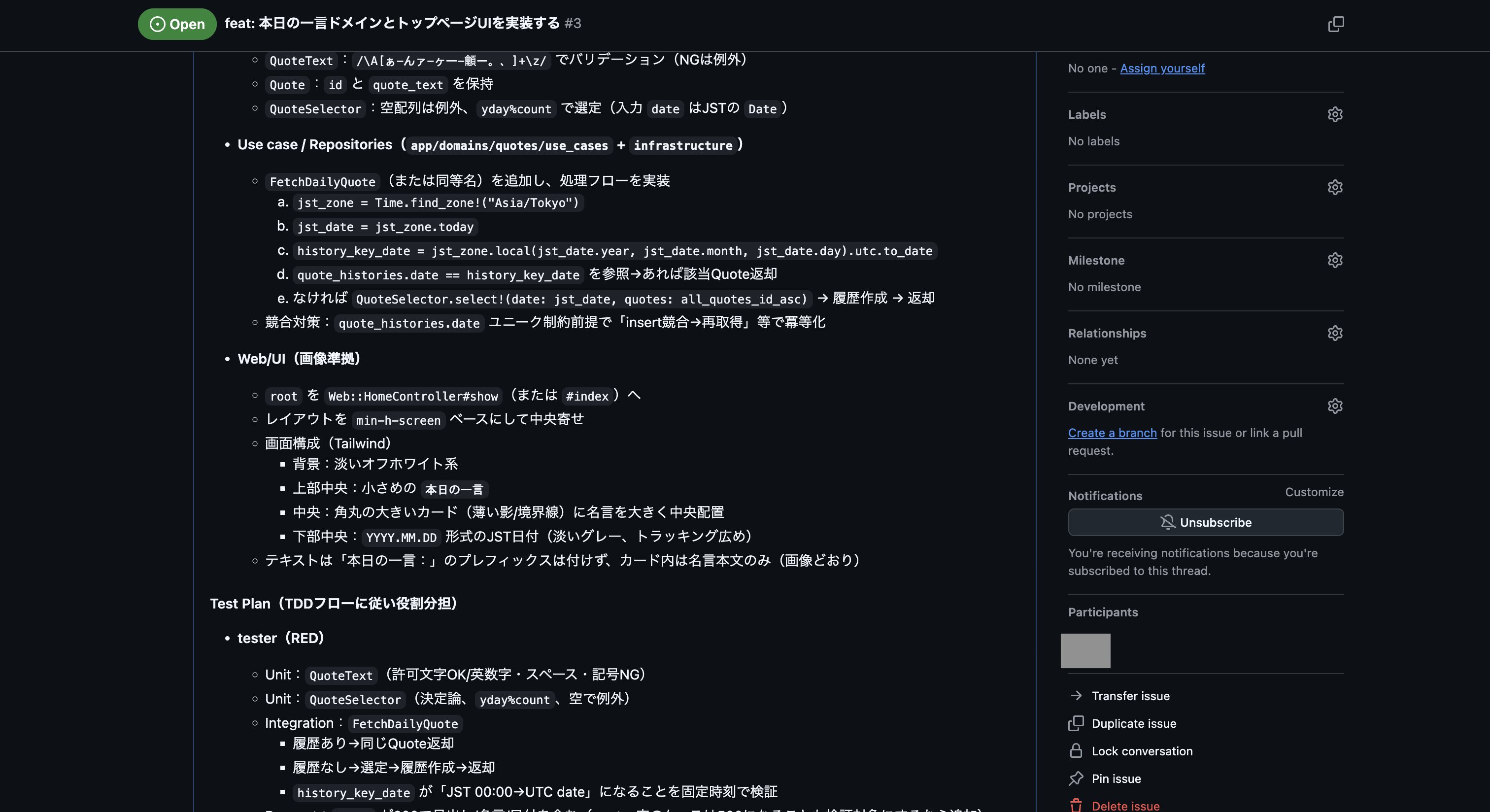
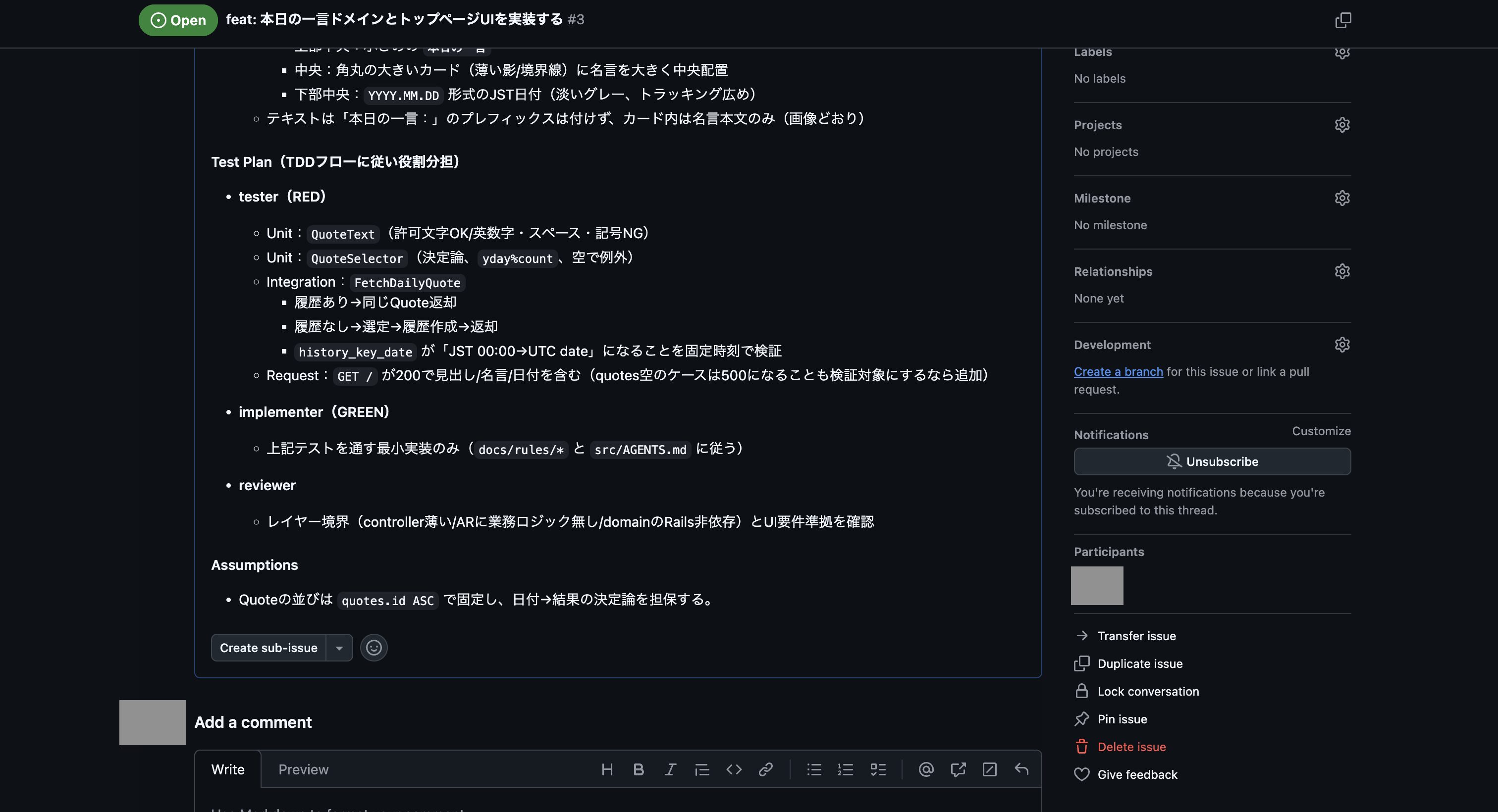
これでなんとかプランをGitHub Issueに登録できましたが、スキル「plan-to-issue」では画像まで登録する機能はないので、UIイメージの画像ファイルはIssueを編集して以下のように追加しました。
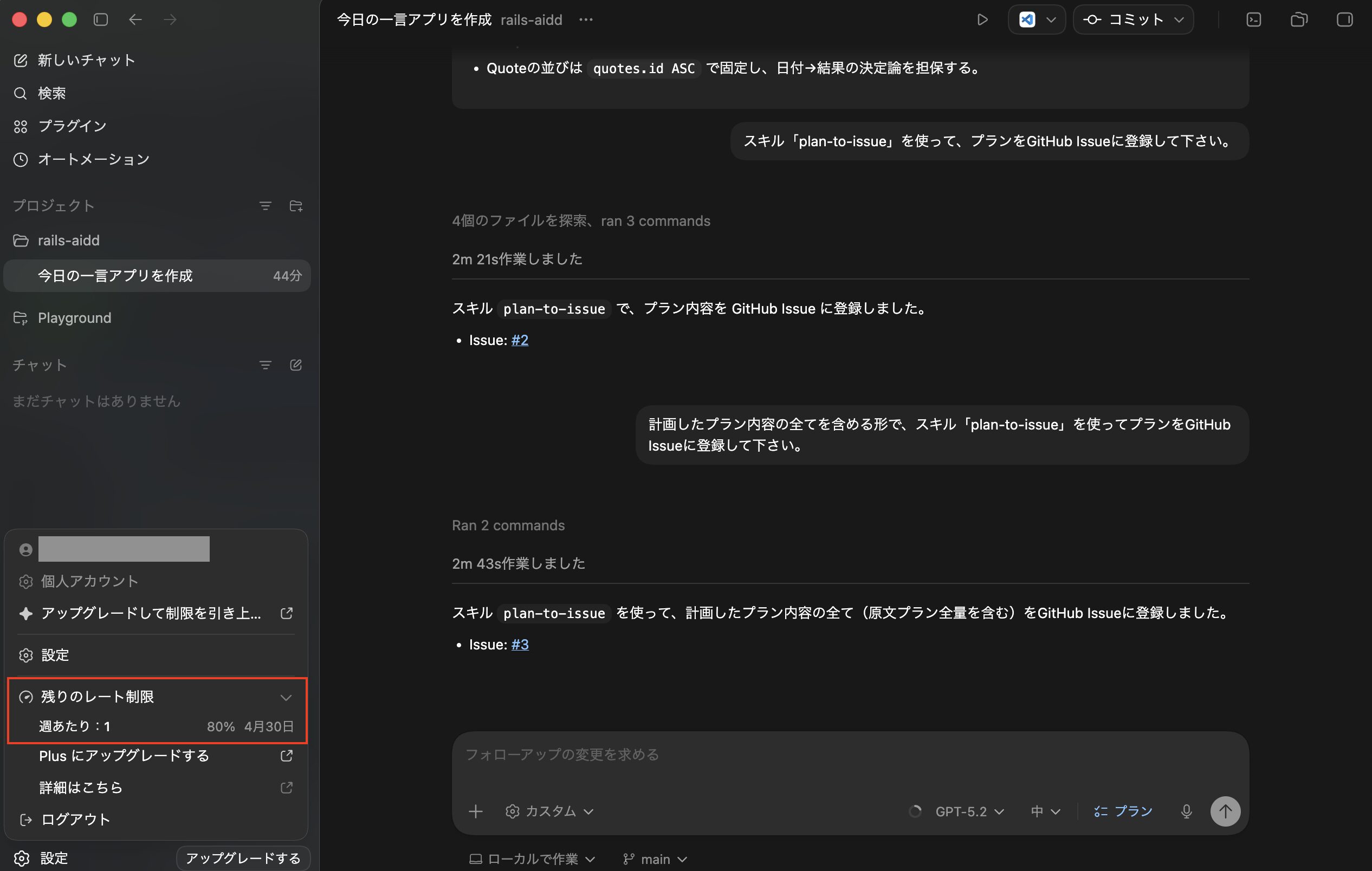
ここまでのトークン使用量
これで「Codexアプリ」のプランモードを利用し、開発計画のプランを立てて、それをGitHub Issueに登録までできましたが、トークン使用量を確認してみたところ100%→80%になっていました。
今回は無料プランで試していますが、試したい方は参考にしてみて下さい。
OpenAI「Codexアプリ」でタスク実行を試す
次に上記で作ったIssueのタスクを試してみます。
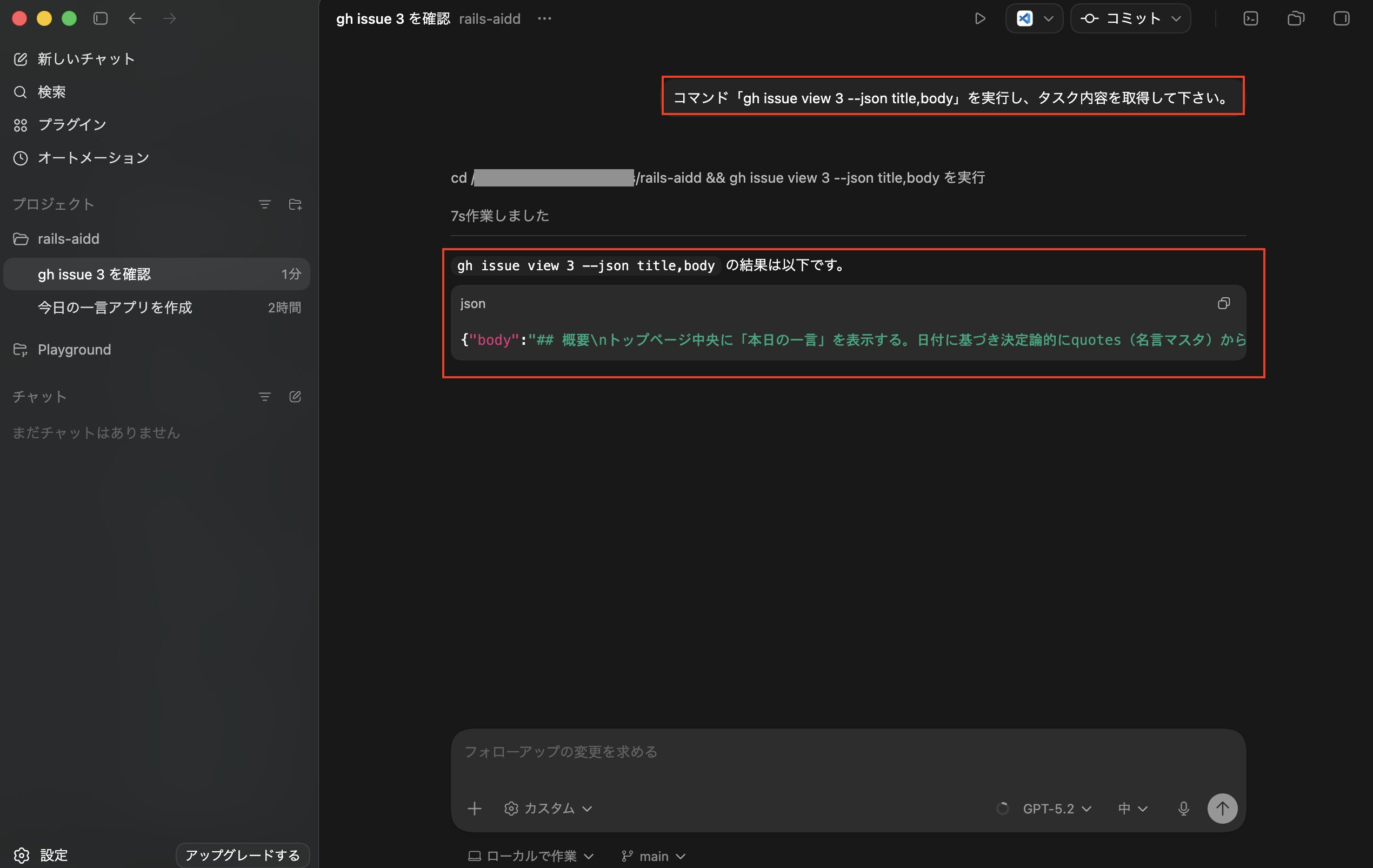
今回はあえて新しいチャットを作ってからGtiHubに登録したIssueの情報を取得してタスクを実行するようにします。
まずは画面左上の「新しいチャット」をクリックし、先ほどとは別の新しいチャットを作ります。
次に命令としてはコマンド「gh issue view {対象のIssue番号} --json title,body」を実行し、タスク内容を取得して下さい。」を実行し、GitHub Issueからタスクの情報を読み込みます。
次にタスク実行の際はネットワークアクセスをOFFにした方がいいため、先ほどと同様に設定画面を開き、ネットワークアクセスを許可するをOFFにします。
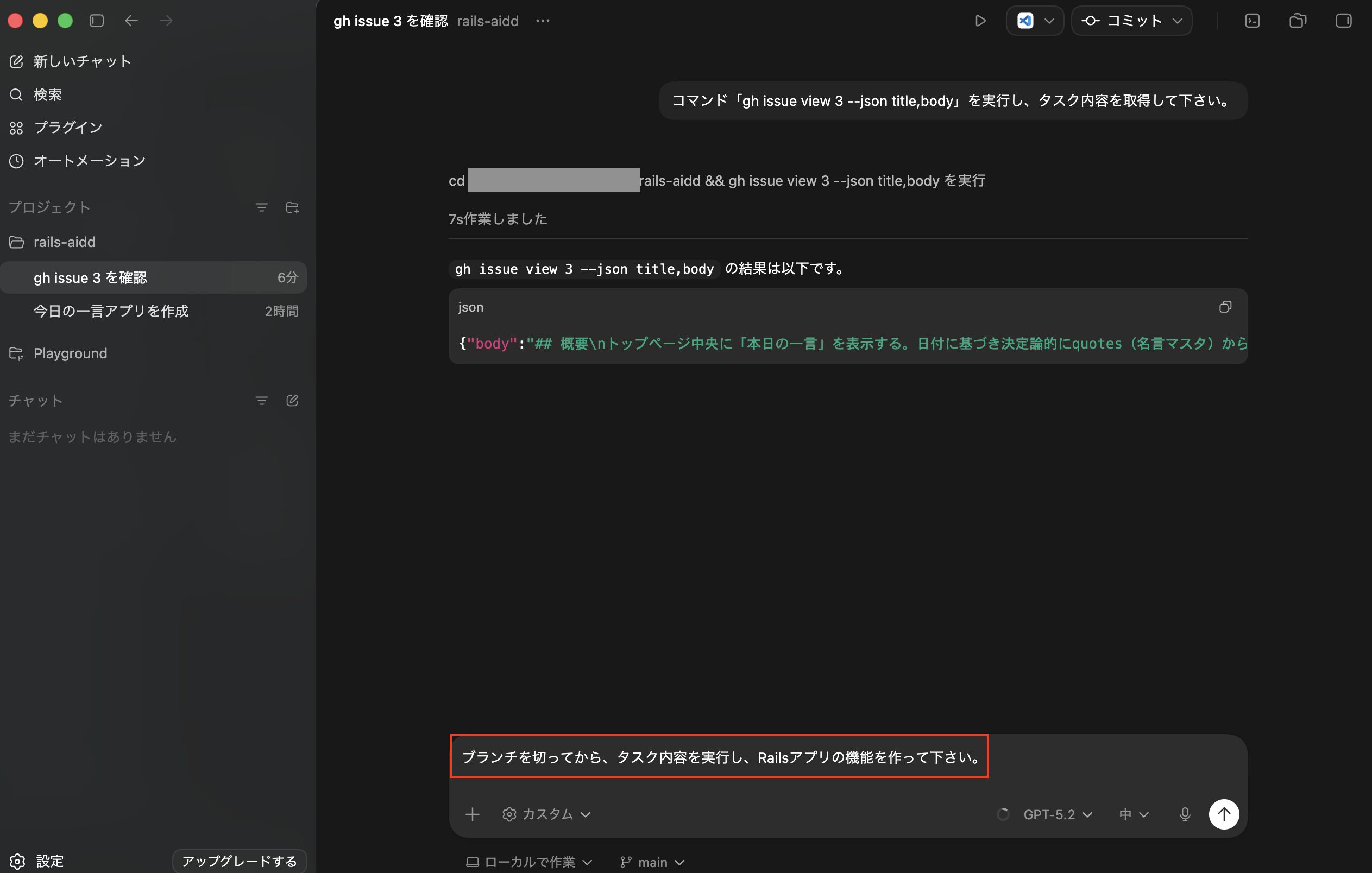
次に命令として「ブランチを切ってから、タスク内容を実行し、Railsアプリの機能を作って下さい。」を実行してみます。
※後から確認したところ、今回の例ではマルチエージェントでタスク処理されてませんでした。マルチエージェントを使いたい場合は、命令に「マルチエージェントでやって」みたいに具体的に命令した方がいいようです。
タスクの実行途中で承認を求められるので、適宜「はい」を選択して許可します。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
15回ほど承認を求められて面倒でしたが、約42分で完了しました!
では動作確認するため、以下のコマンドを実行し、Dockerコンテナの再起動をします。
$ docker compose exec app rails db:prepare
$ docker compose down
$ docker compose up -d
次にブラウザで「http://localhost:3000」を開いて確認すると、以下のように想定通りの画面ができてました!!!
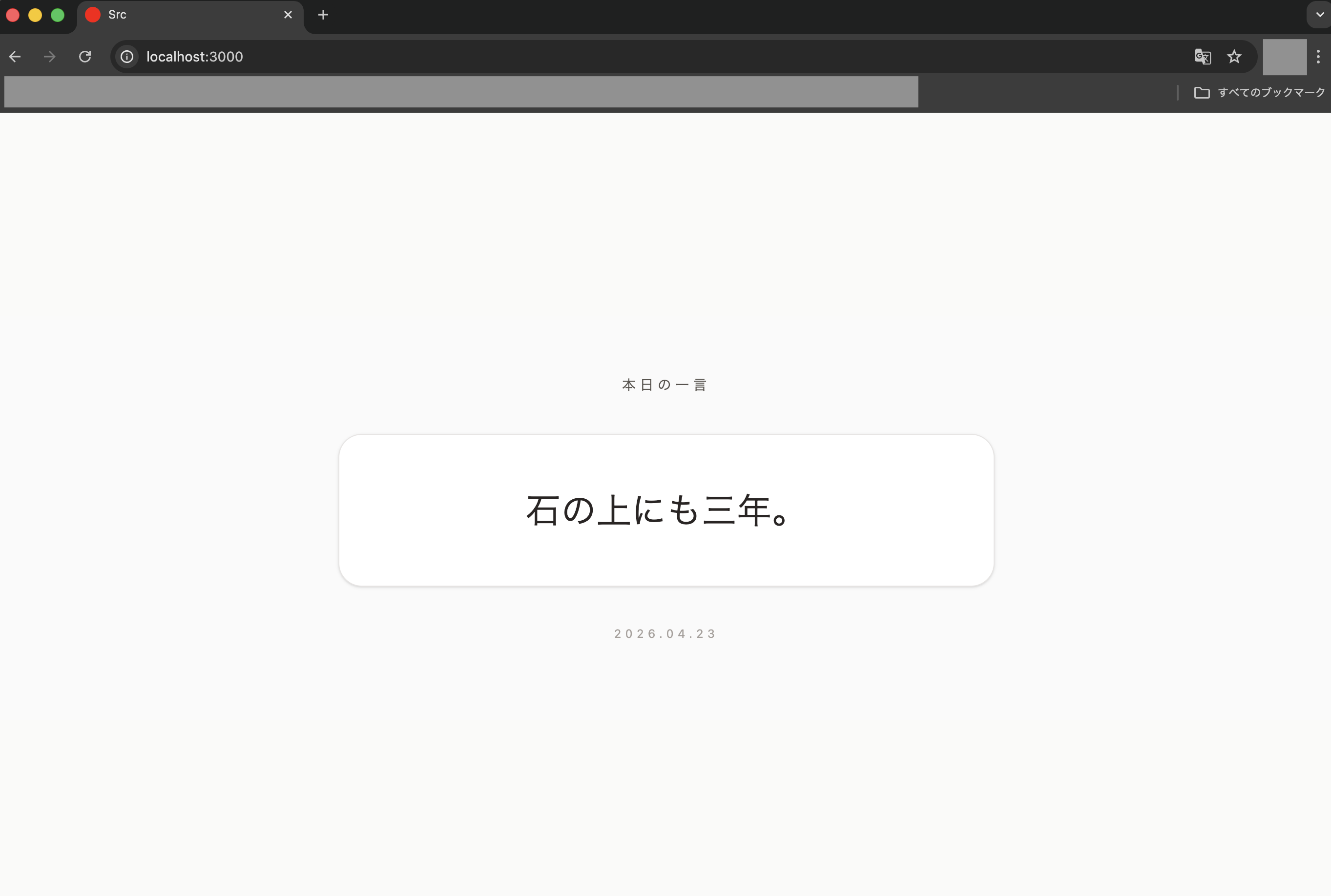
す、凄すぎる!!!
私の想定だと、今回のタスクを実際に人がやろうとした場合、だいたい2営業日ぐらいはかかるかなというイメージだったので、それを考えると約23倍の効率化を実現できてます!!
※960分(8時間 × 2日 × 60分) ÷ 42分 ≈ 22.86 という計算
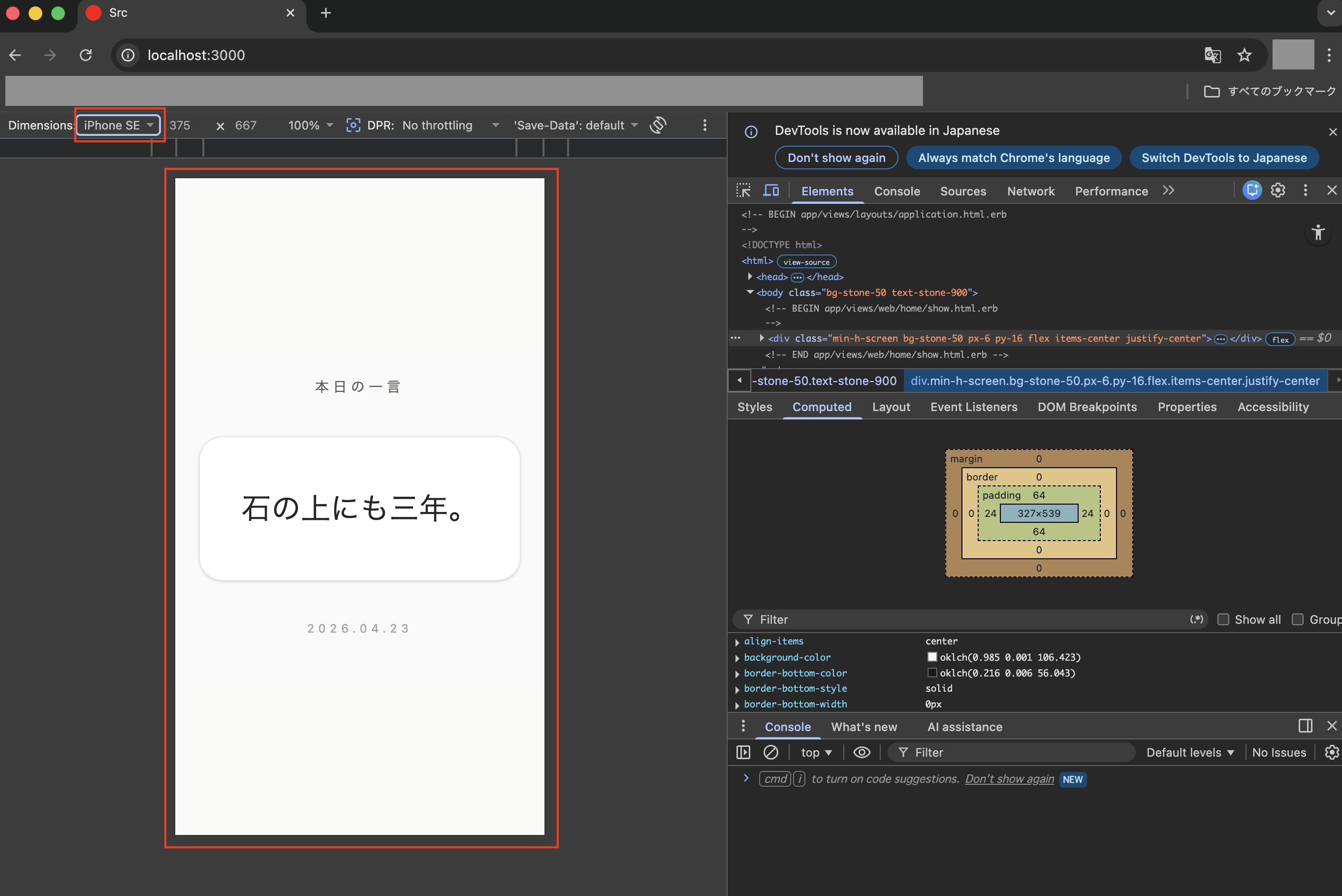
ちなみに今回はレスポンシブデザイン(異なる画面サイズに合わせて表示を自動で最適化する手法)にも対応させるようなタスクにしていたので、ブラウザのツールでDimentionsに「iPhone SE」を選ぶと、以下のように画面サイズに合った表示になります!
ここまでのトークン使用量
ここまでのトークン使用量も確認してみましたが、先ほどの80%→47%になっていたため、1タスクで23%ほど消費しました。
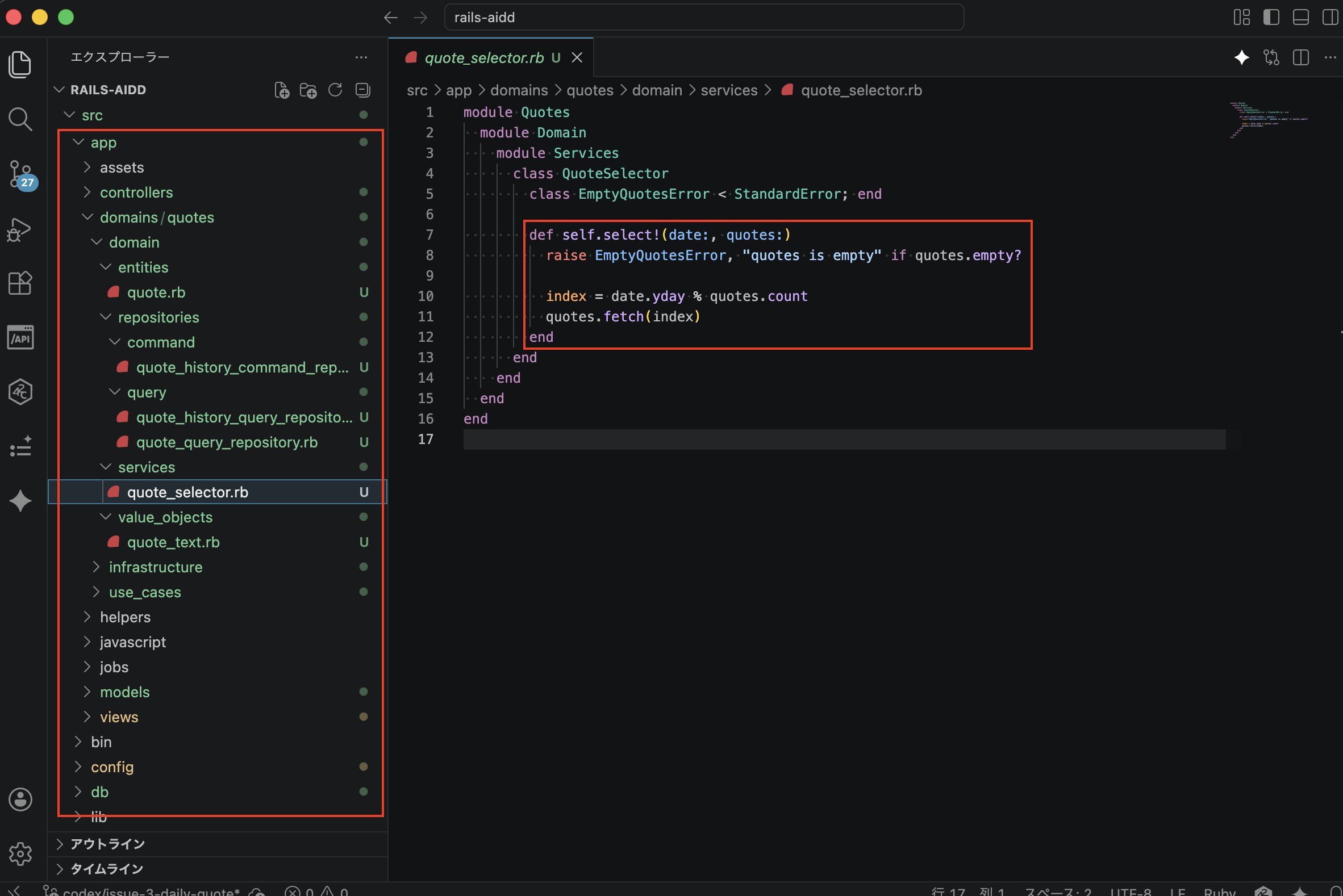
コードも確認してみる
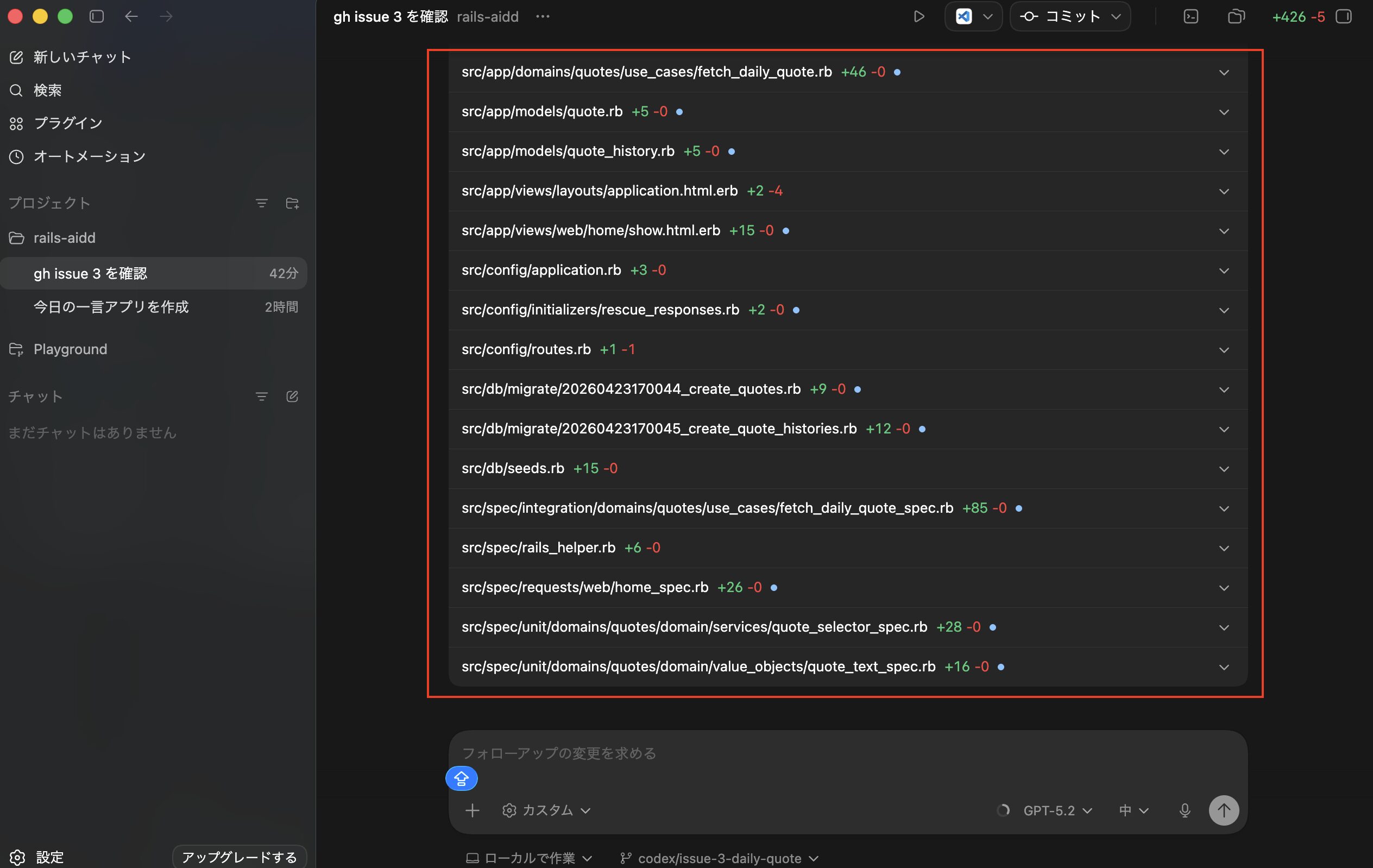
アプリとしては想定通りのものができたようなので、実際に作成されたコードの方も確認してみましたが、事前にしっかりハーネス設計していたため、それがちゃんと反映されて想定通りのディレクトリ構成で作成されてました。
ただ細かい部分としては、ドメインサービスのメソッドに「!」が付いていて、それはいらないなと思ったので、ハーネス設計として「Ruby Style Guide」のようなものが追加であった方がよさそうかなとは思いました。
※「!」については、通常は破壊的変更があるような、危険性があるメソッドに対して「!」を使い、ほとんどは通常のメソッドと対のメソッドして作ったりするため、今回の例では不要。
また、日付の部分がなんか微妙だなと思っていて、プランの方の仕様を確認したら、ちゃんと仕様を詰めれてなかったのでそのようになっていました。
ただプラン通りには作っているので、こういうバグりそうな仕様に関しては、ちゃんと設計した方がいいなという感じです。

※Railsの設定でタイムゾーンを「Asia/Tokyo」にしているので、今回の場合は「jst_date = jst_zone.today」だけ使えばよかった感じです。
プランを作る時にちゃんと仕様をチェックしましょう!
マルチエージェントの起動方法について
後から確認したところ、今回の例ではマルチエージェントが起動していませんでした。
マルチエージェントで起動したい場合は、チャットの命令として「マルチエージェントでやって」みたいに明示的な命令をした方がいいようです。
例えばマルチエージェントで起動している場合は、以下のようにチャット欄の上に「Background Agent」の表示が出るようになっています。
尚、マルチエージェントのレビュワーに前回のコミットをレビューしてもらったところ、コード修正が必要な箇所があったり、逆にドキュメント側(docs/rules/testing.md)を修正した方がいい箇所が見つかりました。
特に初期段階でドキュメント側の仕様が固まってないような場合は、レビューさせてドキュメント側の仕様を改善していくのも大事になりそうです。
※モジュラーモノリスやDDDを採用するとRails標準の書き方からズレるため、その点の仕様はハーネス設計のドキュメントでしっかり定義する必要があります。
スキル「auto-commit」でコミット処理をする
次に事前に作ったスキル「auto-commit」を使ってコミット処理をさせるため、まずは先ほどと同様に設定画面からネットワークアクセスを許可するを一時的に許可します。
次にこのままコミット処理をさせようと思いましたが、どうやらネットワーク設定を変えるとファイル「.codex/config.toml」の方が以下のように自動で更新されてしまうため、このままコミットできません。
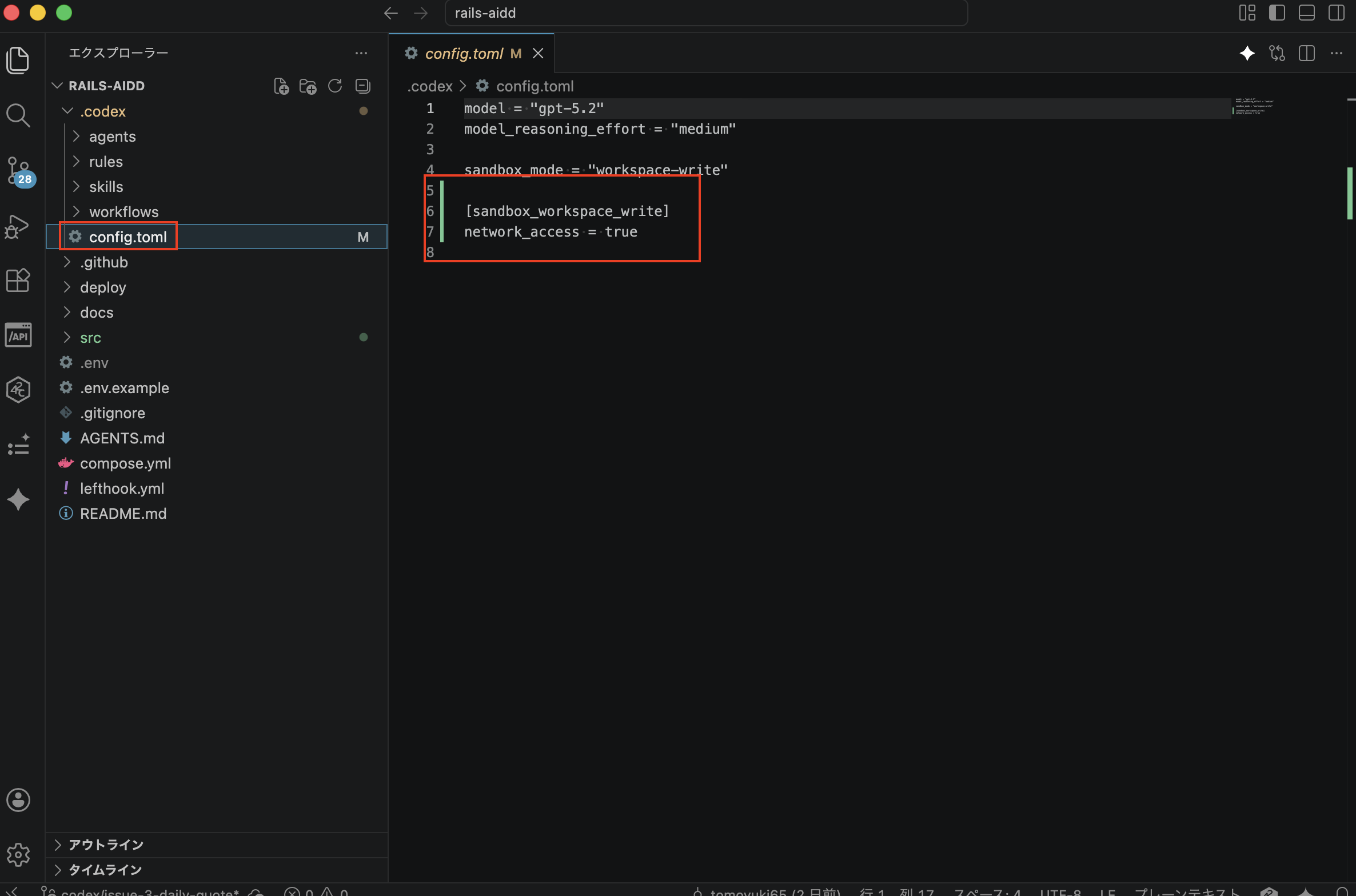
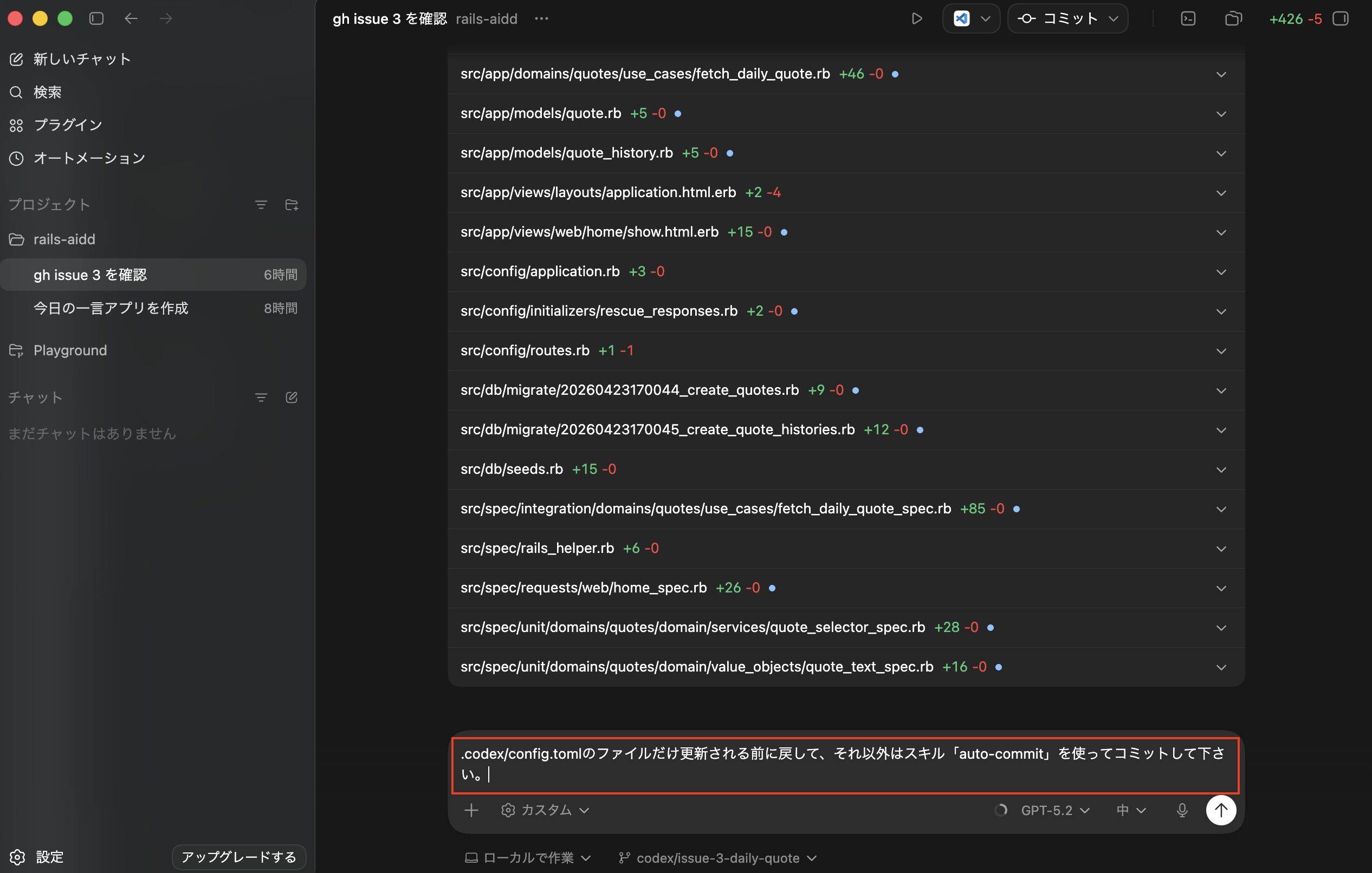
そこで以下のような命令「.codex/config.tomlのファイルだけ更新される前に戻して、それ以外はスキル「auto-commit」を使ってコミットして下さい。」で実行を試してみます。
ポップアップが表示されたので「続行」をクリックします。
承認を求められたので「はい」を選択。
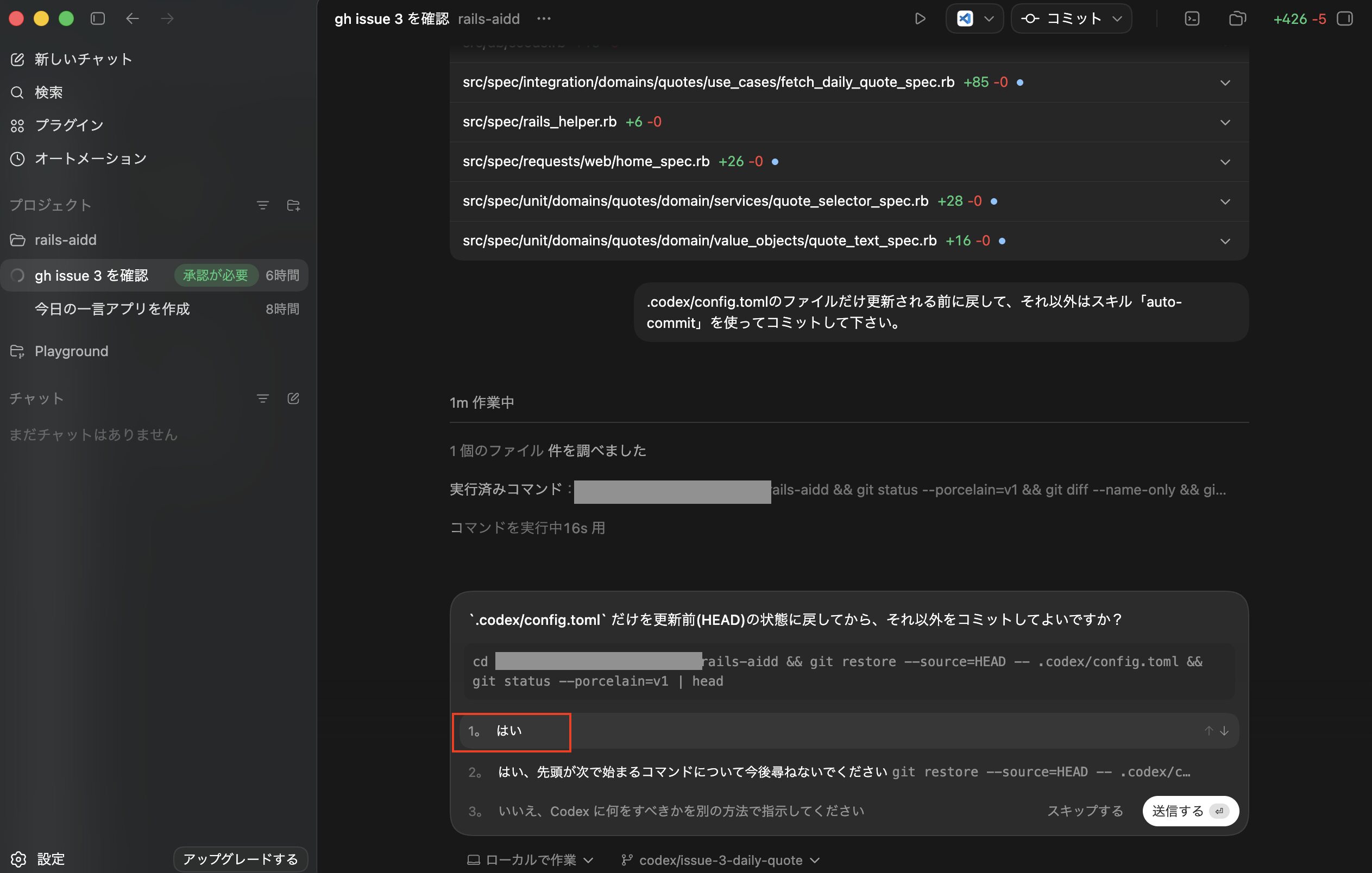
承認を求められたので「はい」を選択。
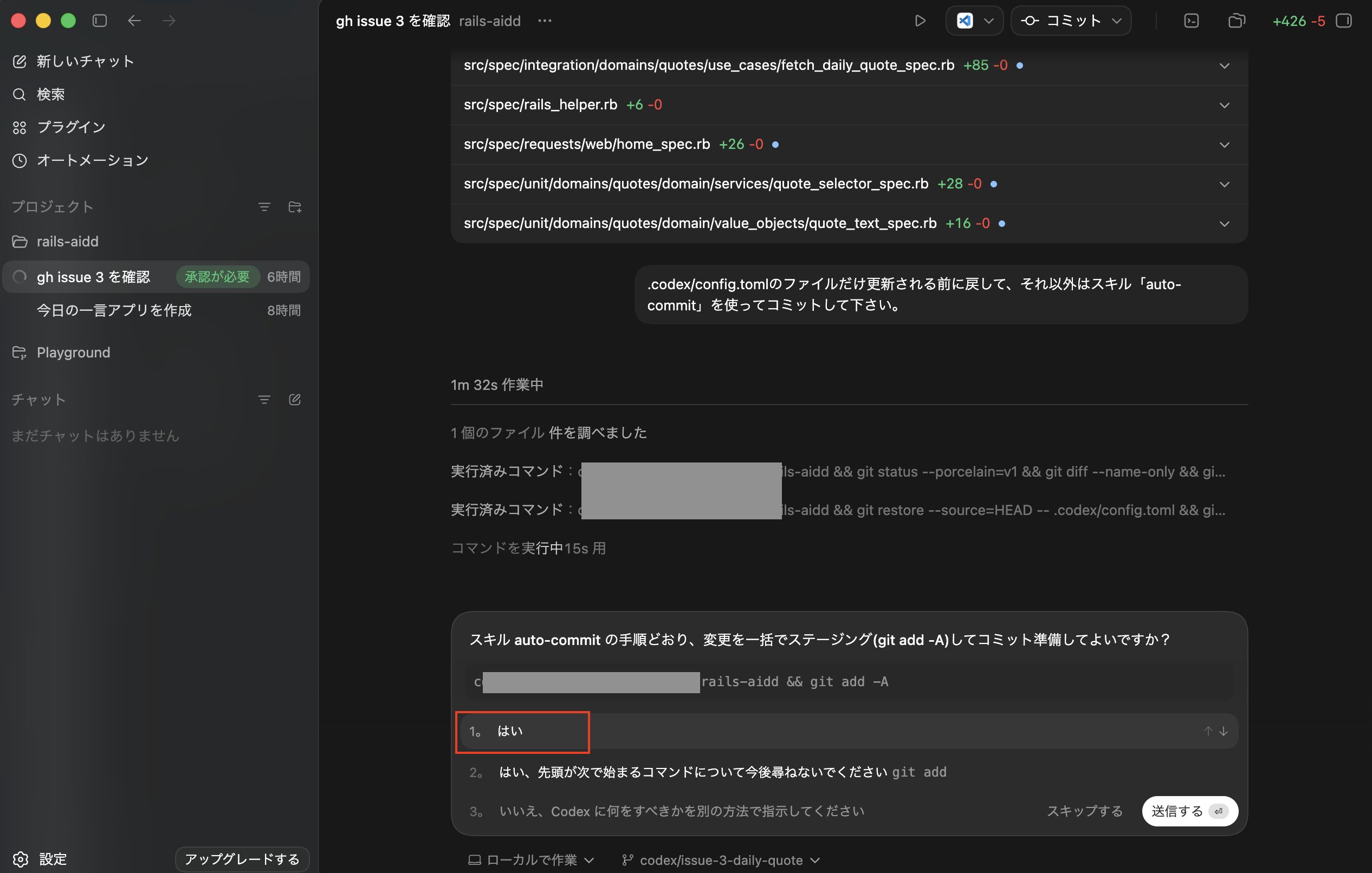
次に承認を求められましたが、コミットメッセージが英語だったので、以下のように「コミットメッセージを日本語にしてください」を実行しました。
承認を求められたので「はい」を選択。
これでコミット処理が終わりました。
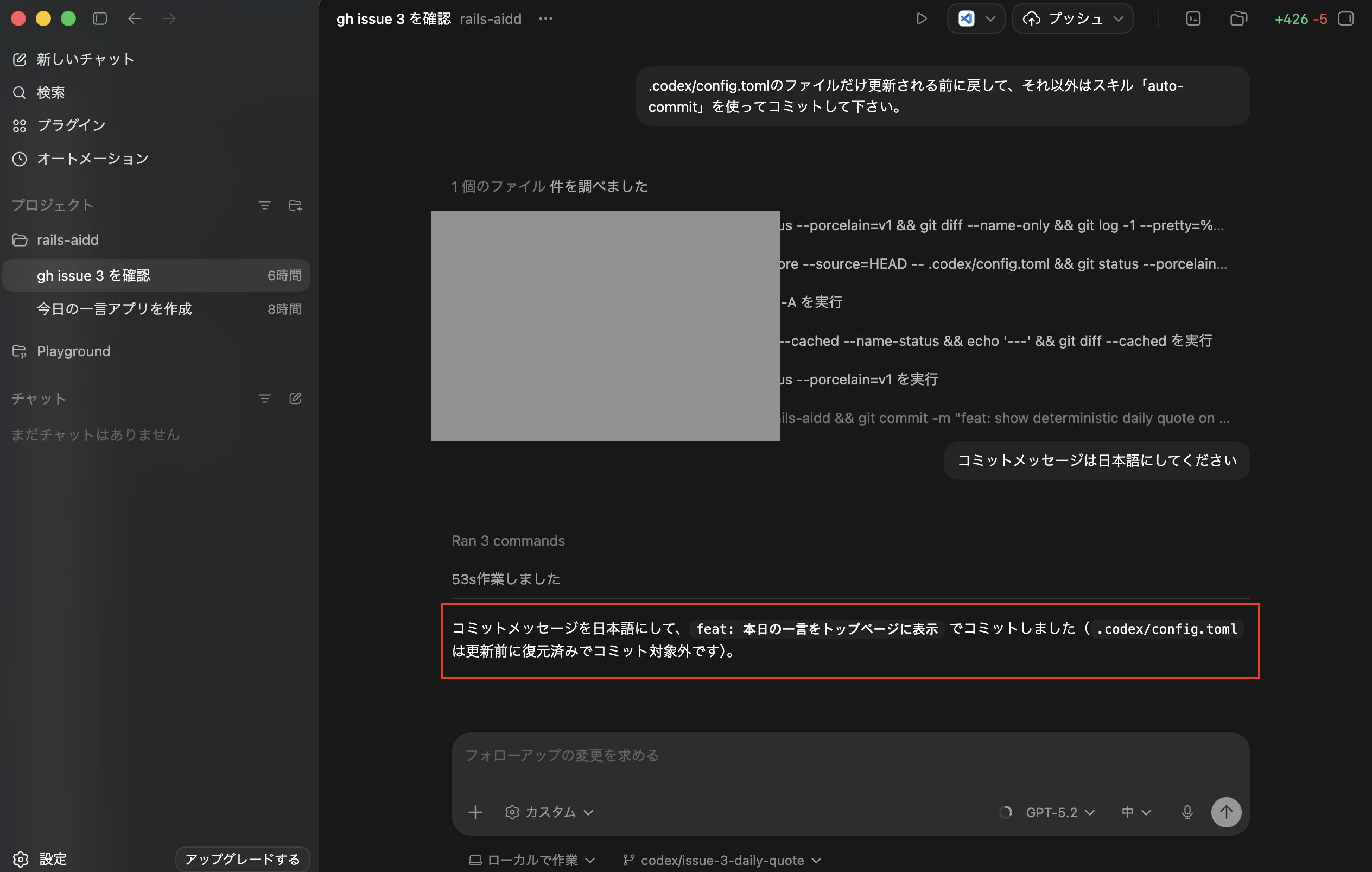
ターミナルで確認すると、ちゃんとコミット完了してました。

スキル「auto-pr」で自動PR作成を試す
次に事前に作ったスキル「auto-pr」を使って自動PR作成を試します。
チャット欄に「スキル「auto-pr」を使ってPR作成して下さい。」を入力して実行します。
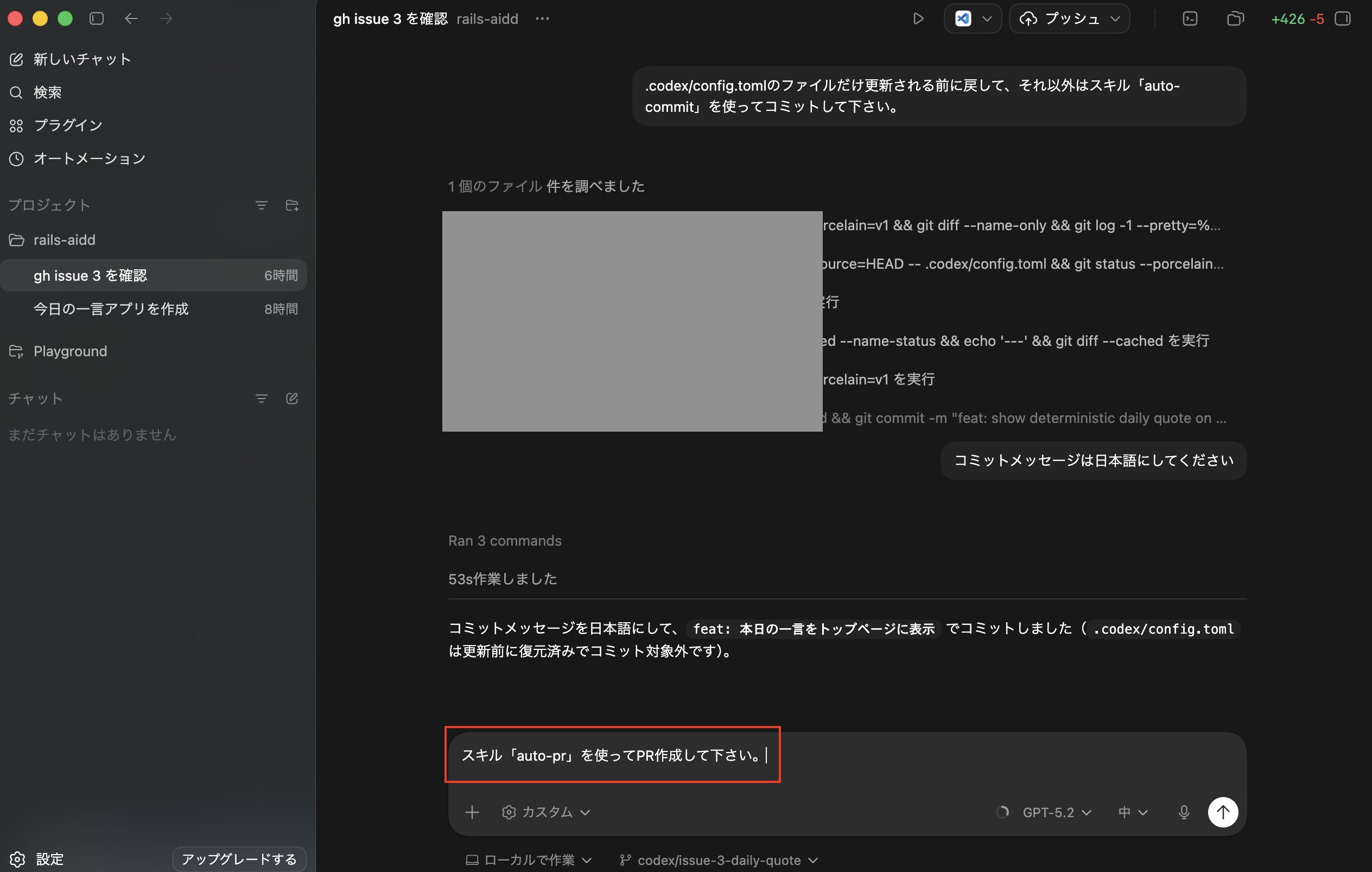
承認を求められたので「はい」を選択。
承認を求められたので「はい」を選択。
これで自動PR作成が終わりました。
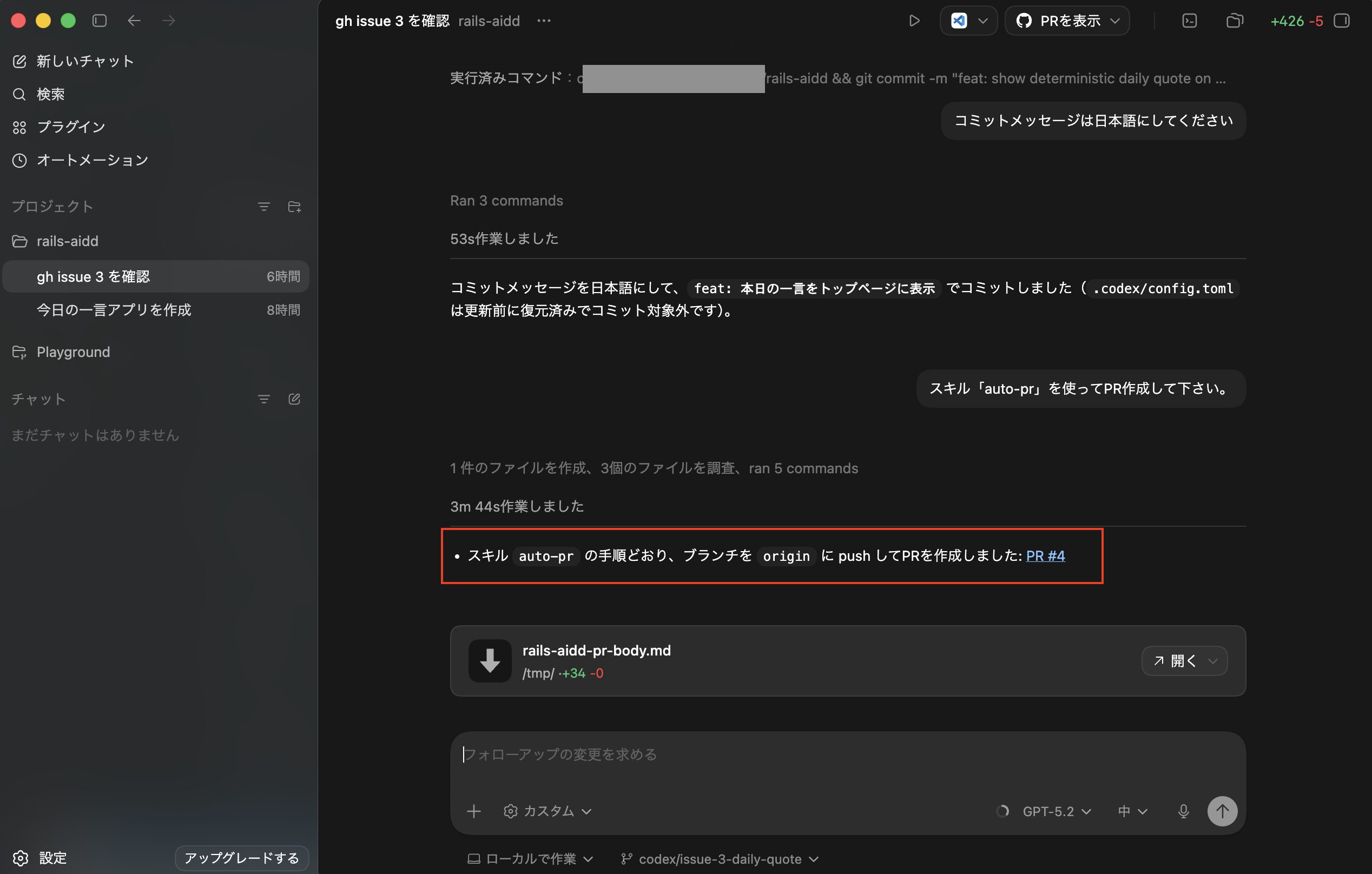
次にGitHubのPull requestsを確認すると、想定通りにPRが作成されました。
今回はCIも設定していたためそれもちゃんと起動しているのと、タスク実行の際にタスク情報を取得していたから?かわかりませんが、背景・目的に対象のIssueのリンクが付与されていたのが良かったです。
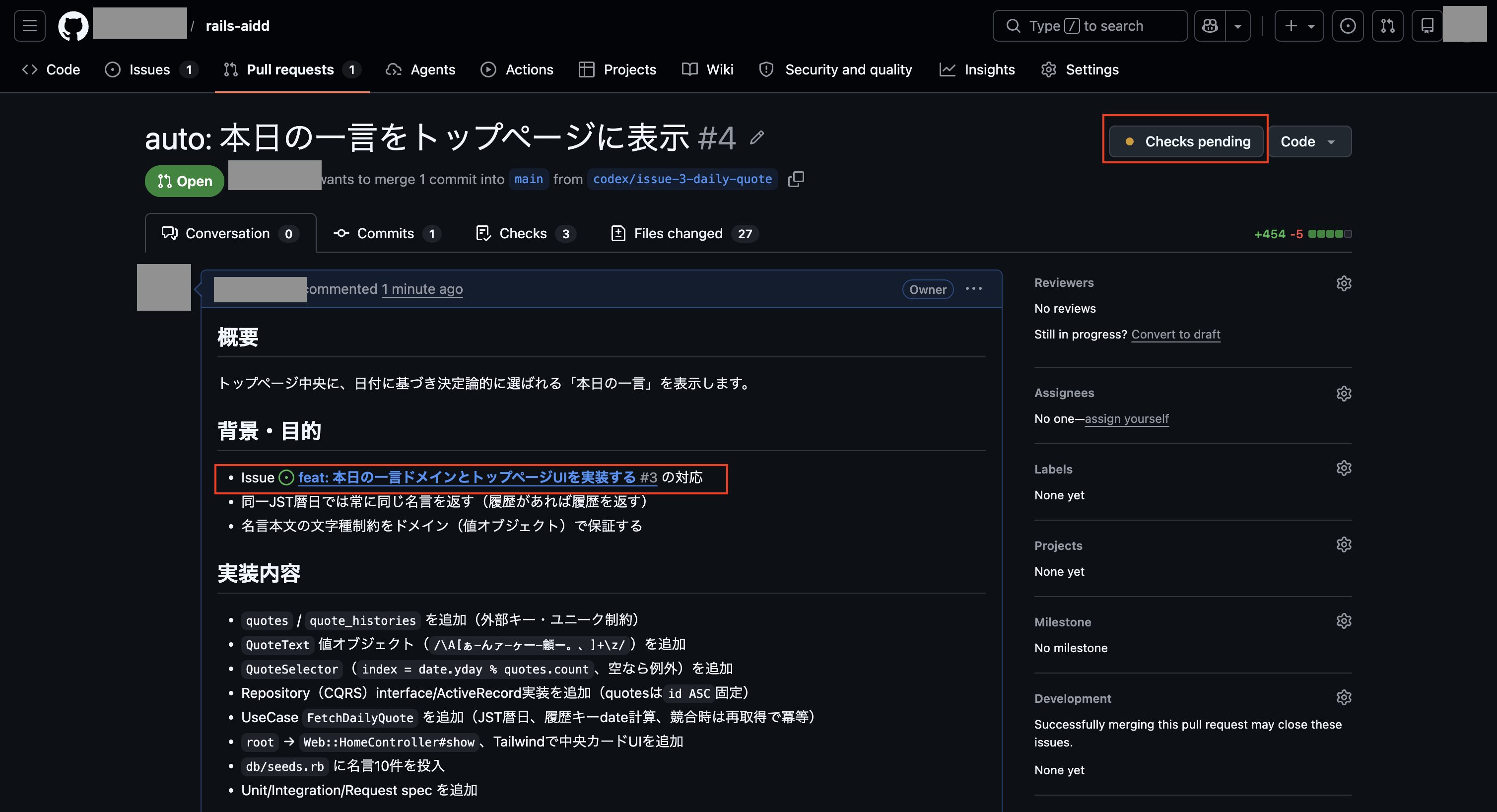
内容を確認した際に、「テスト確認項目」と「未対応・今後の課題」の内容がイマイチだったので、ここはスキル「auto-pr」の改善ポイントかなと思います。
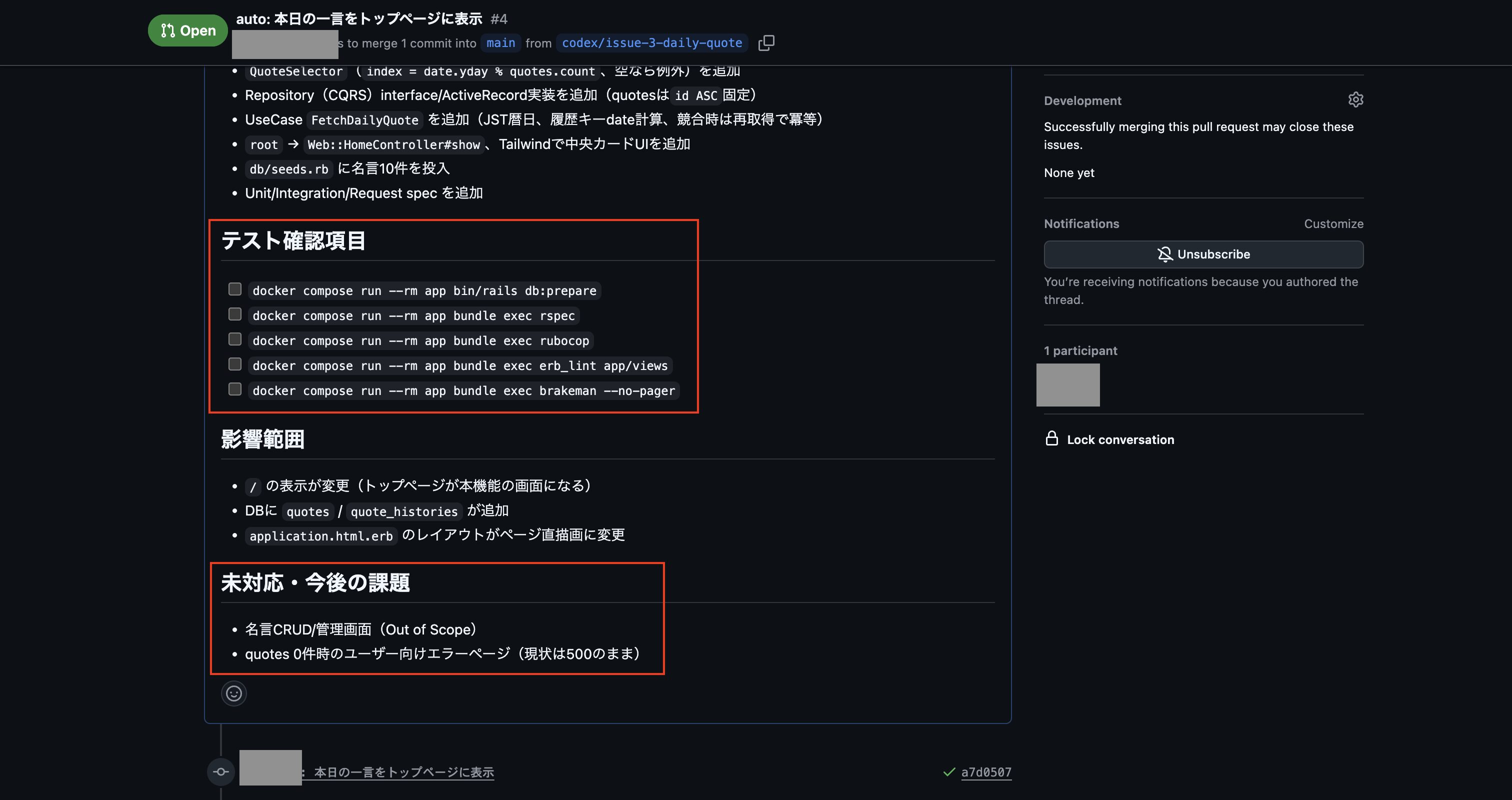
事前にCIのステータスチェックも設定していたため、一番下にはステータスチェックの内容が表示されています。
そんな感じで、スキル「auto-pr」による自動PR作成もほぼ想定通りに完了できたので、この後の流れとしては人間がレビューしていく感じになります。
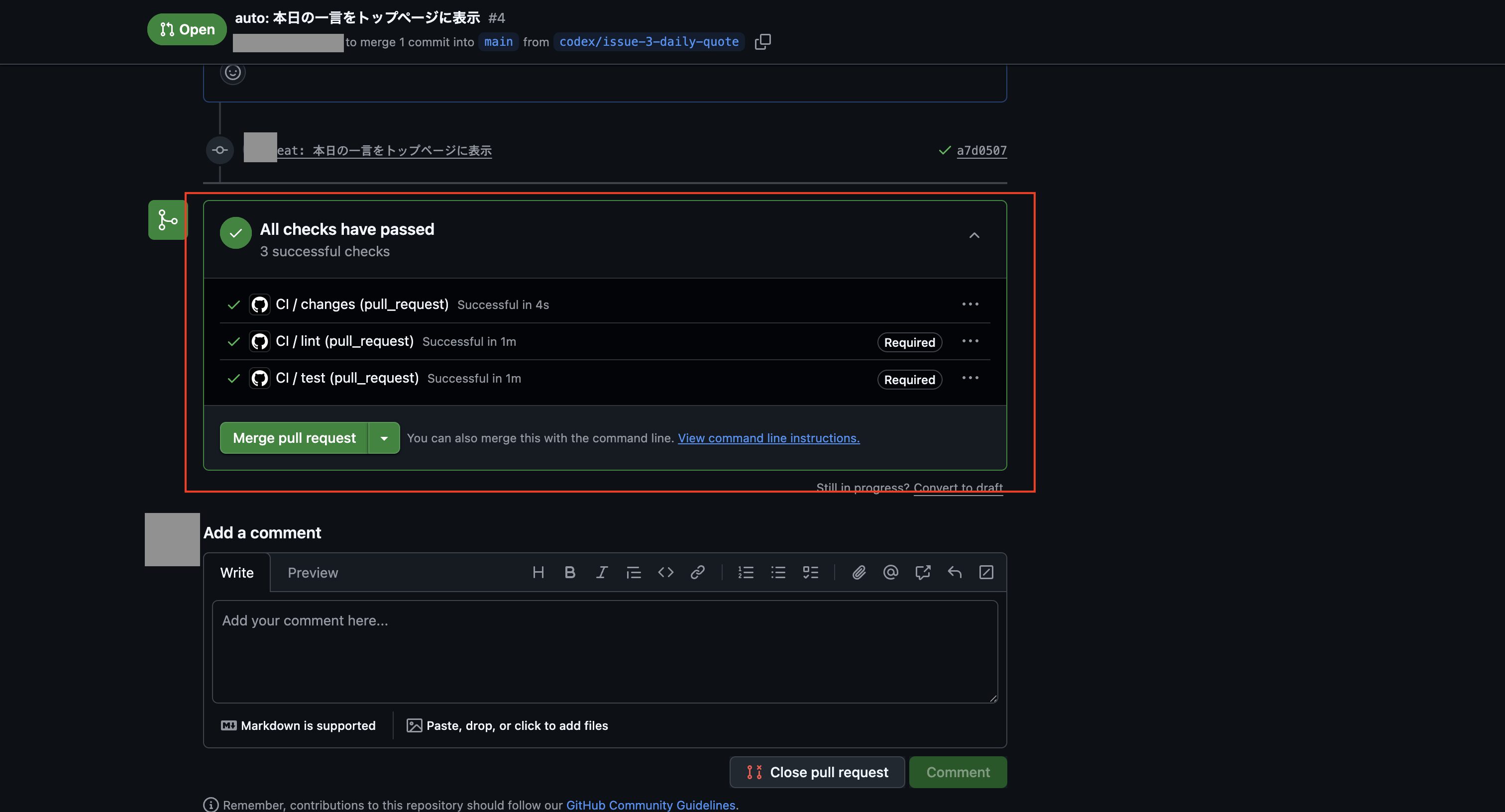
※CIを通らないとマージ不可にする設定です。
レビューした方がいいこと
AI駆動開発によって開発効率は劇的に上がりますが、品質担保の面ではその分レビュー工数が増えます。
ただ全てをレビューするのは現実的ではないため、それをカバーするのも含めて今回はRailsの設計思想「設定より規約」にも注目しています。
少なからず、以下の点についてはしっかりレビューするのが大事です。
- 要件を満たしているかどうか
- テストケースが十分かどうか(内容、網羅性、エッジケース対応など)
- 重要機能についてはパフォーマンスに問題がないか
レビュー完了後にマージ
レビューが終わったらPRのコメントに「LGTM!」を記載したりします。
※LGTMは、「Looks Good To Me」の略で、コードレビューなどで「私的に良さそう(修正不要で承認)」を意味するフレーズです。チャットツールなどで承認の意思を素早く伝える際によく利用されます。
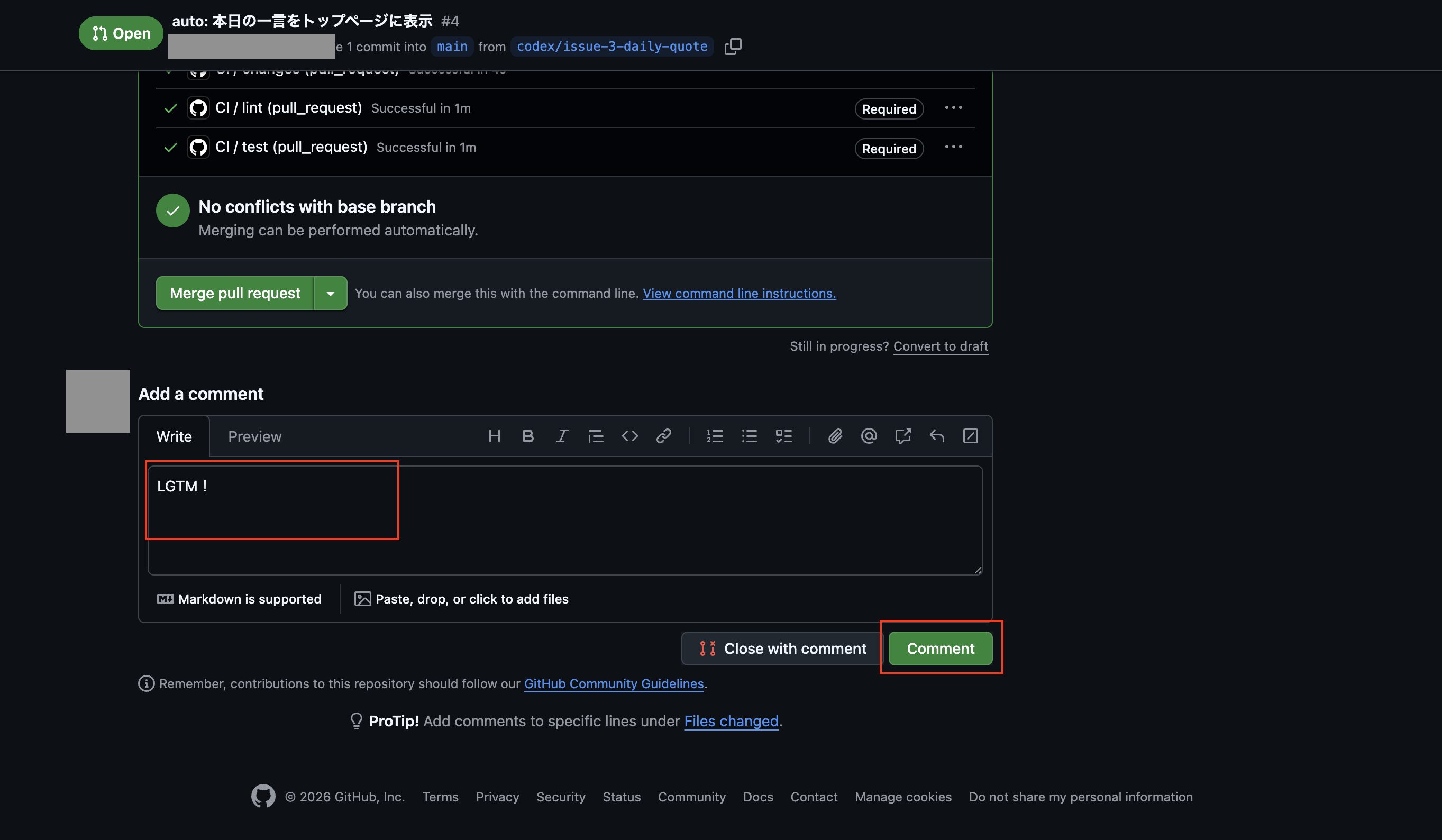
レビュー完了後にマージしたい場合は、PRの下にある「Merge pull request」をクリックします。
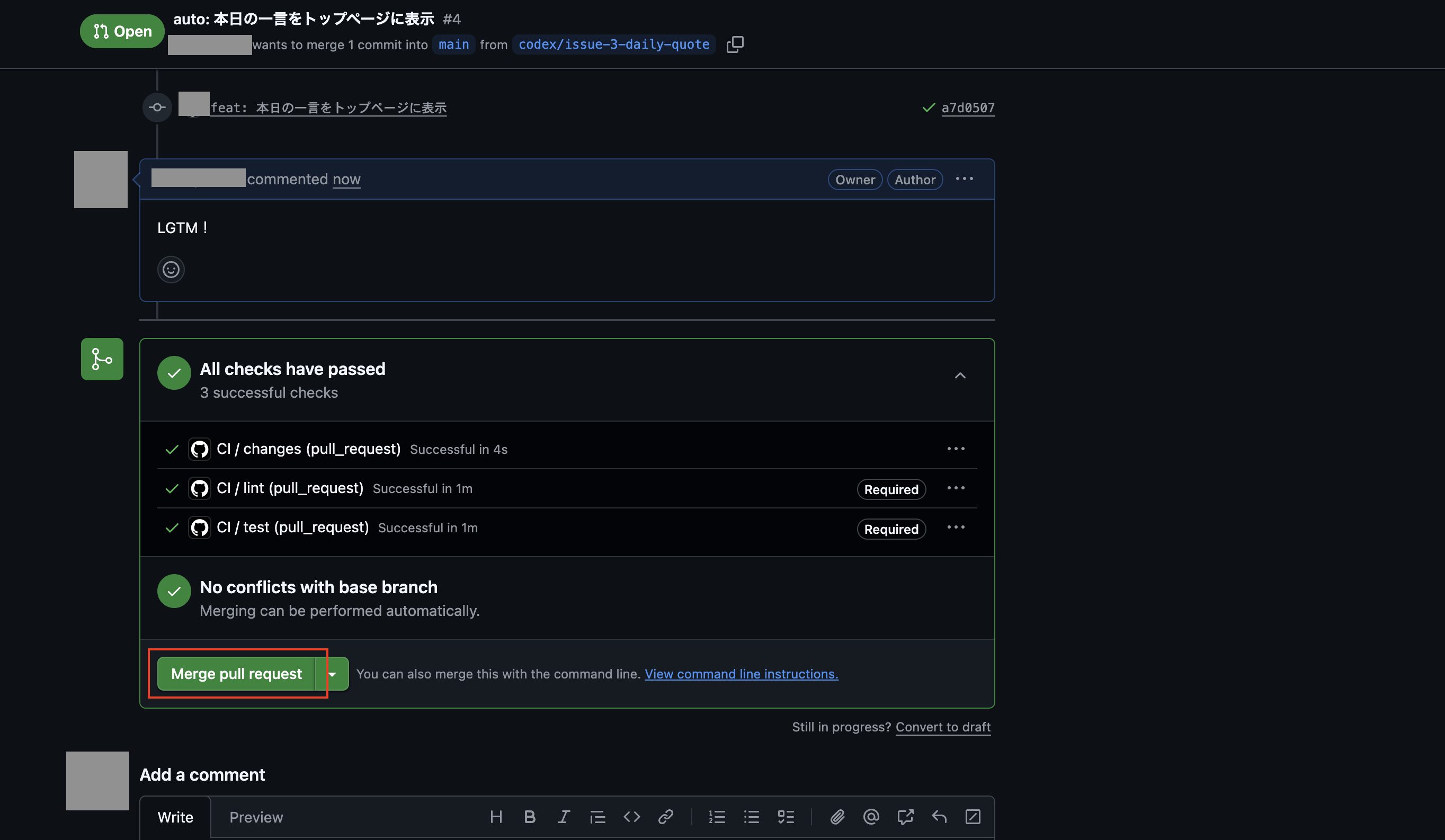
※今回はサクッとマージしますが、PR毎にどのブランチにマージされるかが設定されている(一番上の部分に表示されています。変更も可能です。)ので、そこが間違えてないかは気にするようにして下さい。
次に「Confirm merge」をクリックします。
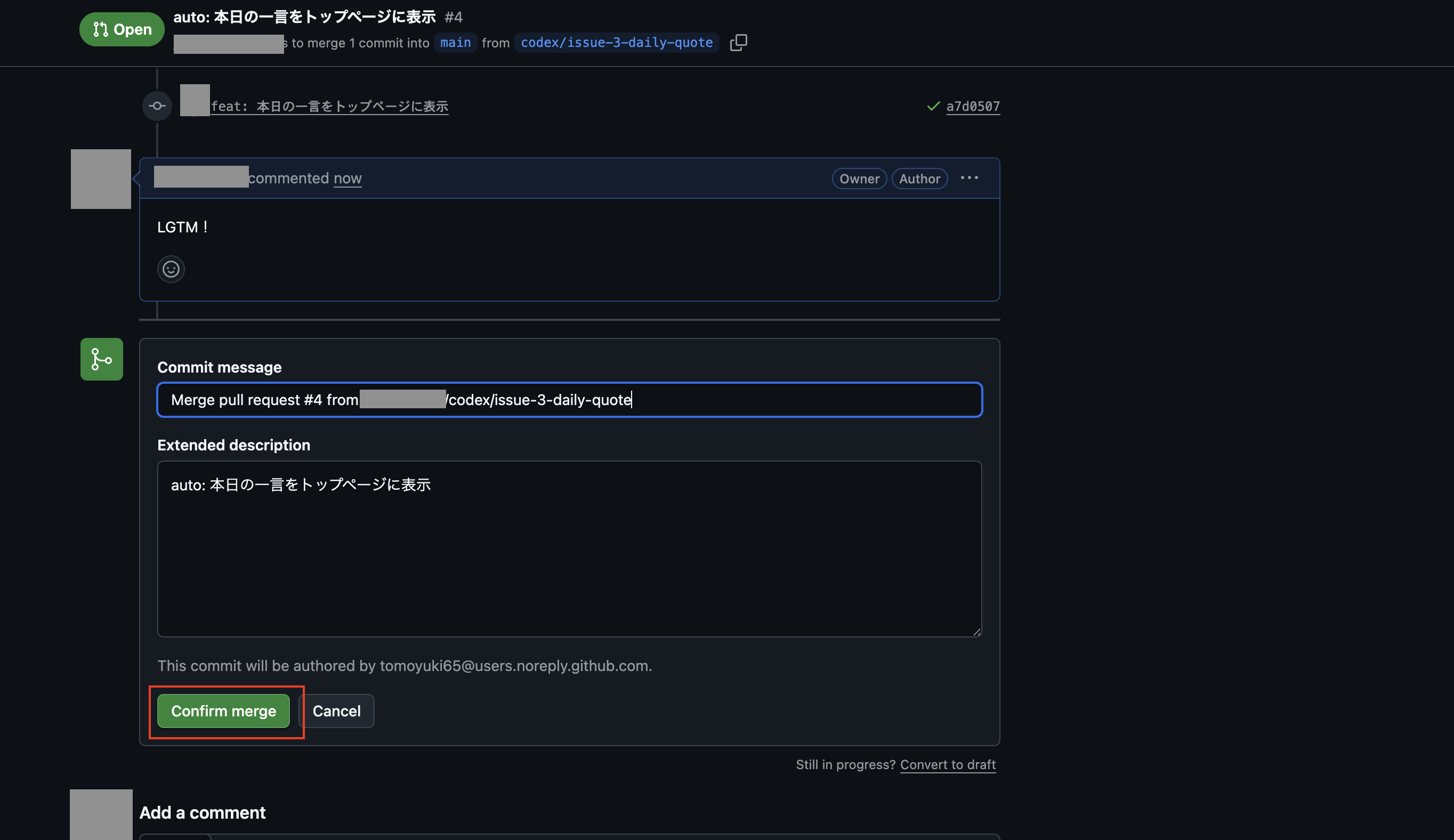
これでマージ完了です。(今回の例ではmainブランチにマージされてます。)
また、今回はブランチを残していますが、マージ後にPull request successfully merged and closedの右側にブランチ削除ボタン「Delete branch」が表示されるので、ここをクリックしてブランチ削除が可能です。
実務であれば無駄なブランチが溜まっていくので、マージ済みのブランチは削除していく方がいいかなと思います。
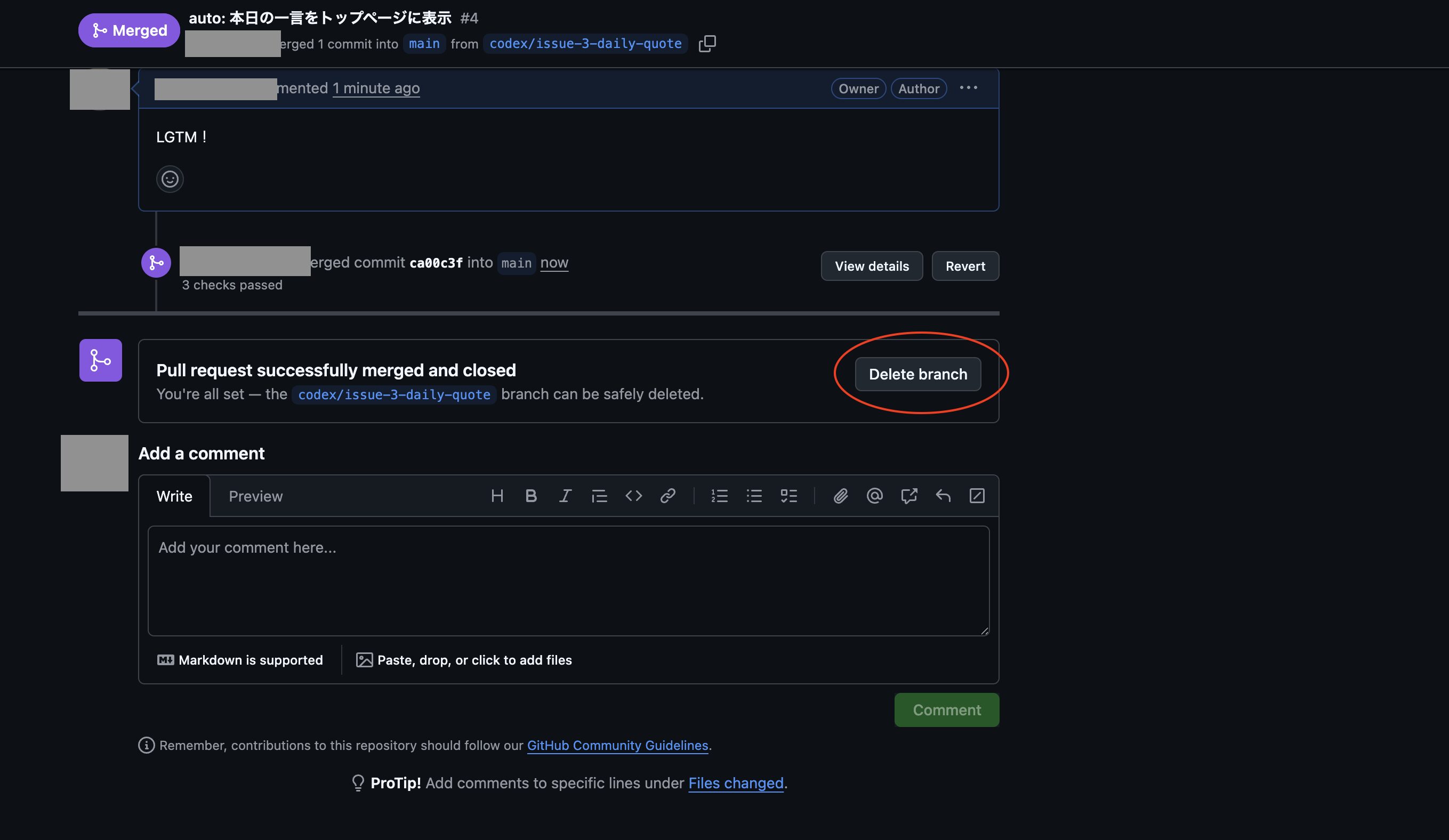
翌日
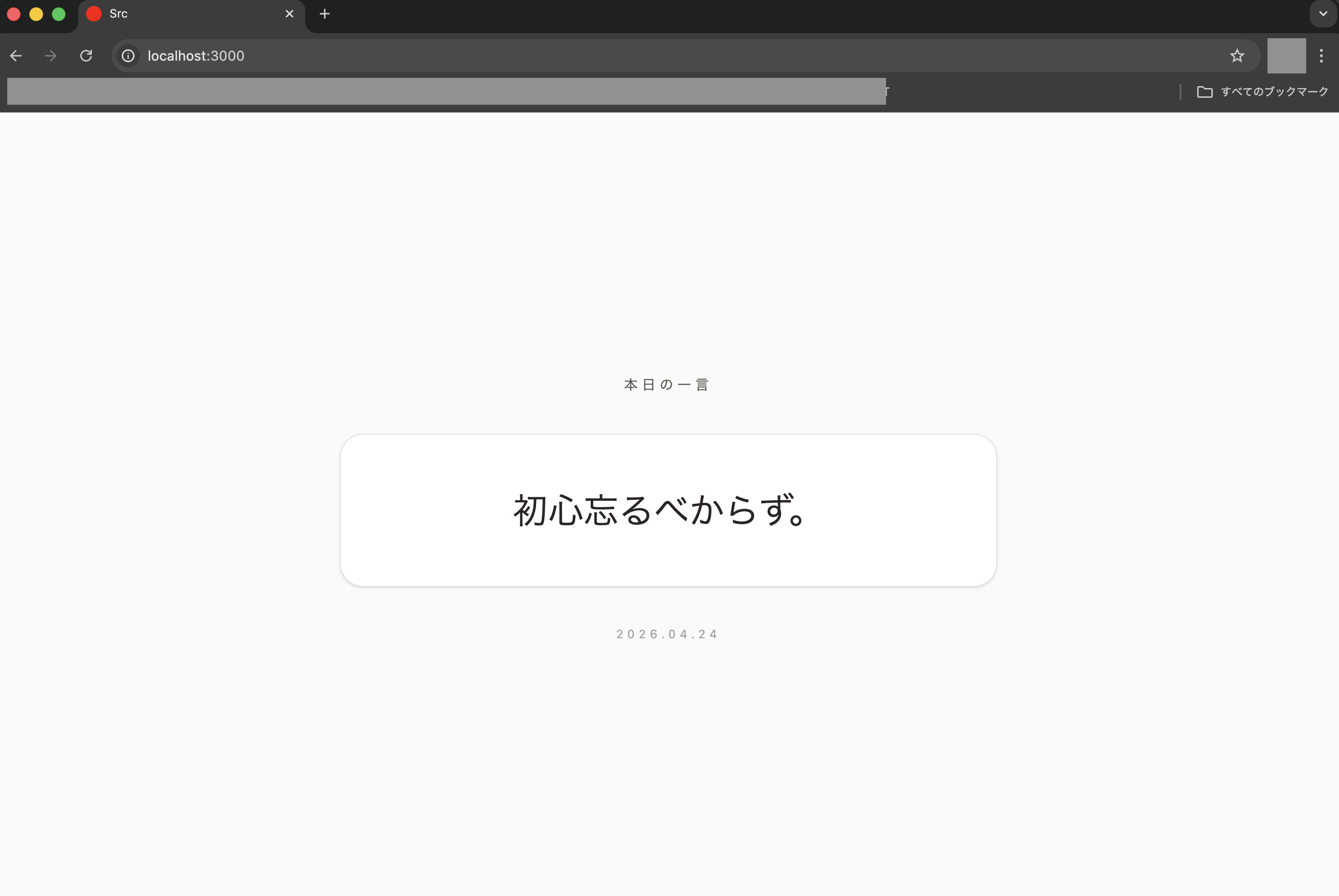
本番環境用のDockerコンテナについて
次に本番環境にデプロイする際は専用のDockefileを作って一つのDockerコンテナを作る必要がありますが、今回利用しているRails8には最初から本番環境用を想定したDockerfile(src/Dockerfile)が入っているため、これを利用すると作れます。
今回は割愛しますが、事前に各種設定ファイル(src/config/environments/production.rbやsrc/config/database.ymlなど)の必要な箇所を修正しておいて下さい。
次に以下のコマンドを実行し、一度起動中のDockerコンテナを止めます。
$ docker compose down
次にDBはローカル開発環境用のに接続して試すため、以下のコマンドを実行してDBコンテナだけ起動します。
$ docker compose up -d db
次にRails8のDockerfileを使ってローカルにコンテナを作って試してみますが、以下のコマンドを実行してDockerコンテナをビルドします。
$ docker build --no-cache -t rails-aidd-app:1.0.0 -f src/Dockerfile src※本番環境用を想定し、タグにはバージョン「1.0.0」を付けてます。
次に以下のコマンドを実行し、ビルドしたDockerコンテナを起動して試しますが、このタイミングで環境変数を渡す必要があり、特に環境変数「RAILS_MASTER_KEY」にはファイル「src/config/master.key」中身の値を設定する必要があります。
$ docker run -d \
-p 80:80 \
-e RAILS_MASTER_KEY={src/config/master.keyの中身の値} \
-e DB_HOST=host.docker.internal \
-e DB_USER=root \
-e DB_PASSWORD=root \
rails-aidd-app:1.0.0※Dockerコンテナ内のポートが80になっているため、ポート設定は「80:80」にしてます。また今回は例として開発環境用のDBと接続して試すため、DB_HOSTには「host.docker.internal」を設定してます。実際に本番環境で環境変数を設定する際は各種インフラにあるシークレットサービスを使って下さい。
コマンド実行後、Docker Desktopを確認し、以下のように二つのDockerコンテナが起動できていればOKです。
※尚、apiコンテナの方を止めたい場合は、Docker Desktopからだと簡単に削除できます。
次にブラウザで「http://localhost」にアクセスし、以下のように想定通りの画面が表示されればOKです。
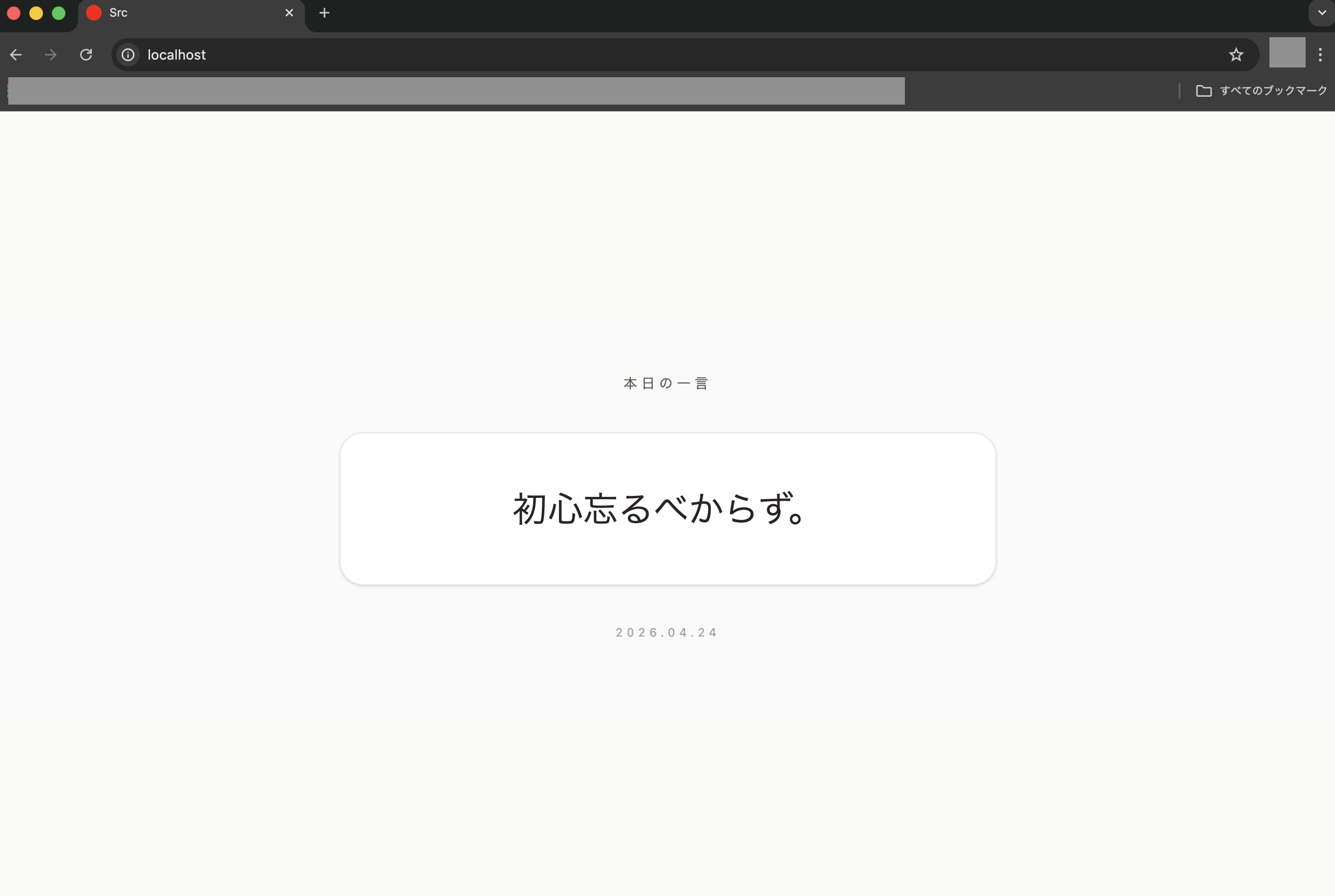
AIツール利用時のセキュリティ対策について
AIツールは便利ですが、セキュリティ知識が無い状態で安易に利用すると、知らないうちに意図せず機密情報を漏洩し、セキュリティ問題に発展する可能性があります。
最低限覚えておきたいセキュリティ知識については以下の記事にまとめたので、合わせでご確認下さい。
関連記事
・生成AIで機密情報は大丈夫?AIツール開発のセキュリティ対策|ゼロトラスト・サンドボックス・環境変数(.env)管理
最後に
今回はRuby on RailsによるAI駆動開発の実践方法についてご紹介しました。
実際に試してみて開発効率が約23倍だったのに非常にびっくりしましたが、これを踏まえても、もうAI駆動開発は避けられません。
そして、このAI駆動開発にあたって、一番大事だなと思ったところとしては、ハーネス設計の部分だったので、これからハーネスエンジニアリングが流行りそうです。
そんなハーネスエンジニアリングについては、システム開発におけるほぼ全工程のある程度の知識や経験がないと整えられないため、設計もできて、コードも書けて、AIツールも使える人ができる仕事であり、これからシニアエンジニアの需要がますます伸びそうです。
また、今回はRails(設計思想が「設定より規約」)を使っているので少なめのハーネス設計で済んでいますが、別の言語やフレームワークによってはもっとしっかりハーネスを作り込む必要がでるため、その点は十分注意しましょう。
ということで、これからRuby on RailsによるAI駆動開発をしていきたい方は、ぜひ参考にしてみて下さい!













コメントを残す