

こんにちは。Tomoyuki(@tomoyuki65)です。
みなさん、『正規表現』という言葉を聞いたことはありますか?
Rubyだけに限った話ではないので、聞いたことがある方もいるかと思います。
この正規表現を使いこなすことで、文字列検索や置換を簡単に行うことができるようになるんです!
この記事では、そんな正規表現について解説します。
正規表現とは?
正規表現は、Wikipediaには次のように書いています。
正規表現(せいきひょうげん、英: regular expression)とは、文字列の集合を一つの文字列で表現する方法の一つである。
ちょっとわかりづらいですが、簡単に説明すると『パターンを指定して文字列を効率よく検索・置換する方法』です。
また、正規表現はRuby専用の機能ではなく、他のプログラミング言語やテキストエディタでも一般的に使われている機能です。
よって、一度学んでしまえば他のプログラミング言語でも活かせます。
正規表現を試す
まずは正規表現を試してみましょう。
以下の文章の中から、郵便番号だけを検索してみます。
東京駅の住所は、東京都千代田区丸の内1丁目です。 また、郵便番号は1000005です。
Rubyの正規表現を試す場合、「Rubular」というオンラインツールを使うと便利です。
Rubularを使った場合

ブラウザからRubularにアクセスして下さい。図のような画面が開きます。

次に画面の「Your test string:」に先ほどの文章を貼り付けて下さい。

次に画面の「Your regular expression:」に「\d+」(バックスラッシュ + d+)を入力して下さい。
画面の「Match result:」にマッチした結果が表示されます。
図のように郵便番号「1000005」がハイライトされていればOKです。
Rubyで試す場合
次はRubyで同様のことを試してみましょう。
以下のプログラムを実行してみて下さい。
text = <<TEXT
東京駅の住所は、東京都千代田区丸の内1丁目です。
また、郵便番号は1000005です。
TEXT
puts text.scan(/\d+/)
1000005
Rubyでも郵便番号を検索できましたね。
Rubyで置換を試す
次は置換を試してみましょう。
先ほどの文章の郵便番号をハイフン(-)で区切って表示してみましょう。
次のプログラムを実行してみて下さい。
text = <<TEXT
東京駅の住所は、東京都千代田区丸の内1丁目です。
また、郵便番号は1000005です。
TEXT
puts text.gsub(/(\d{3})(\d{4})/, '\1-\2')
東京駅の住所は、東京都千代田区丸の内1丁目です。
また、郵便番号は100-0005です。
郵便番号がハイフンで区切られましたね!
このように正規表現を使いこなせれば、文字列の検索や置換を簡単にすることができます。
正規表現のメタ文字を覚える
正規表現の使いこなすためには、まず「\d」のようなメタ文字の使い方を覚えましょう。
正規表現には主に以下のようなメタ文字があります。
| メタ文字 | メタ文字の意味 |
| [ ] | いずれか1文字を表す文字クラスを作る |
| [^ ] | 〜以外の任意の1文字を表す文字クラスを作る |
| – | []内で使われると文字の範囲を表す |
| . | 任意の1文字を表す |
| ( ) | 内部でマッチした文字列をキャプチャもしくはグループ化する |
| ? | 直前の文字やパターンが1回、もしくは0回現れる |
| * | 直前の文字やパターンが0回以上連続する |
| + | 直前の文字やパターンが1回以上連続する |
| {n,m} | 直前の文字やパターンがn回以上、m回以下連続する |
| | | OR条件を作る |
| ^ | 行頭を表す |
| $ | 行末を表す |
| \ | メタ文字をエスケープしたり、\nや\wといった他のメタ文字の一部になったりする |
[ ]の使用例
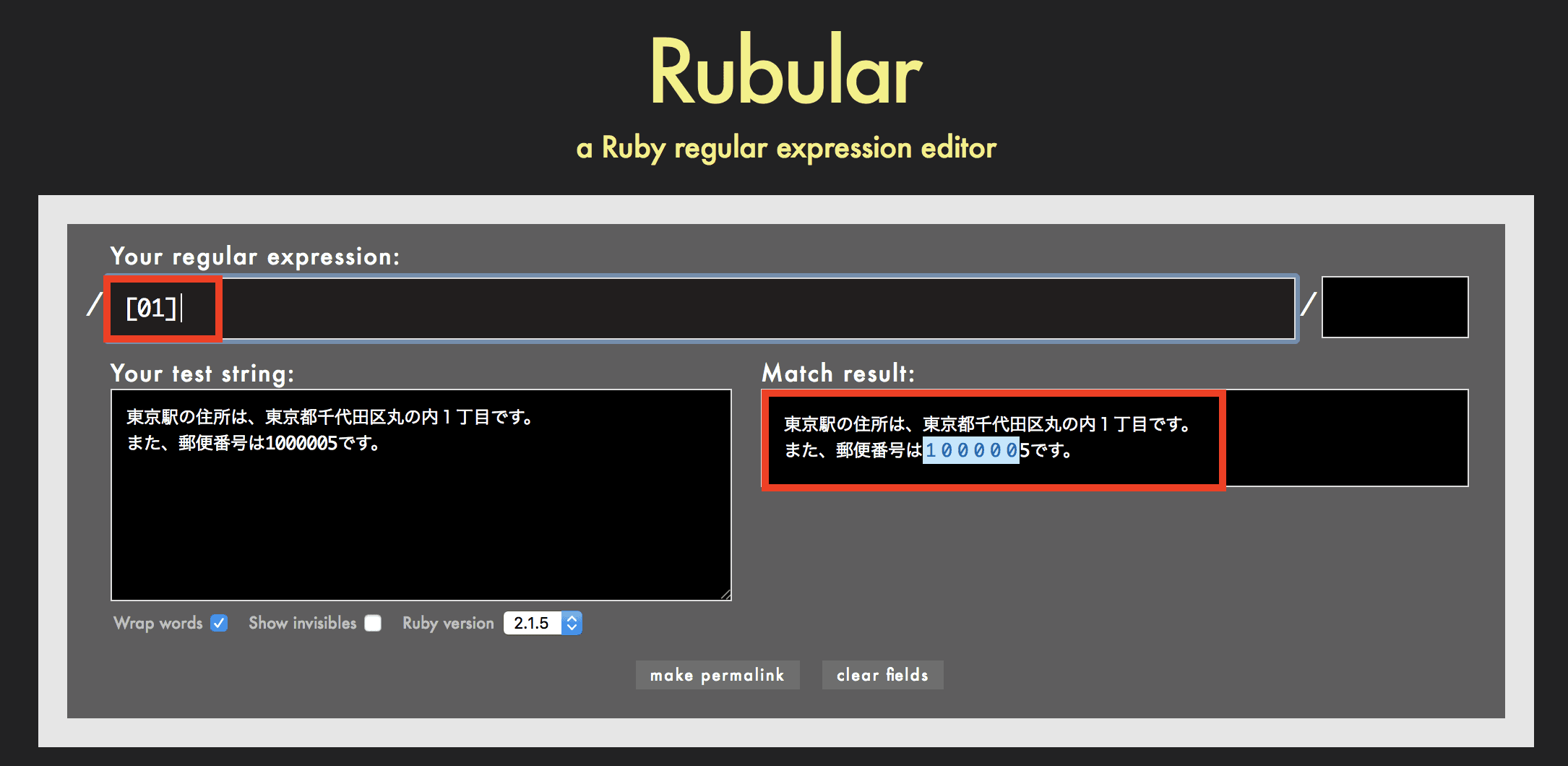
例えば正規表現が [01] の場合、0または1を検索します。
[^ ]の使用例
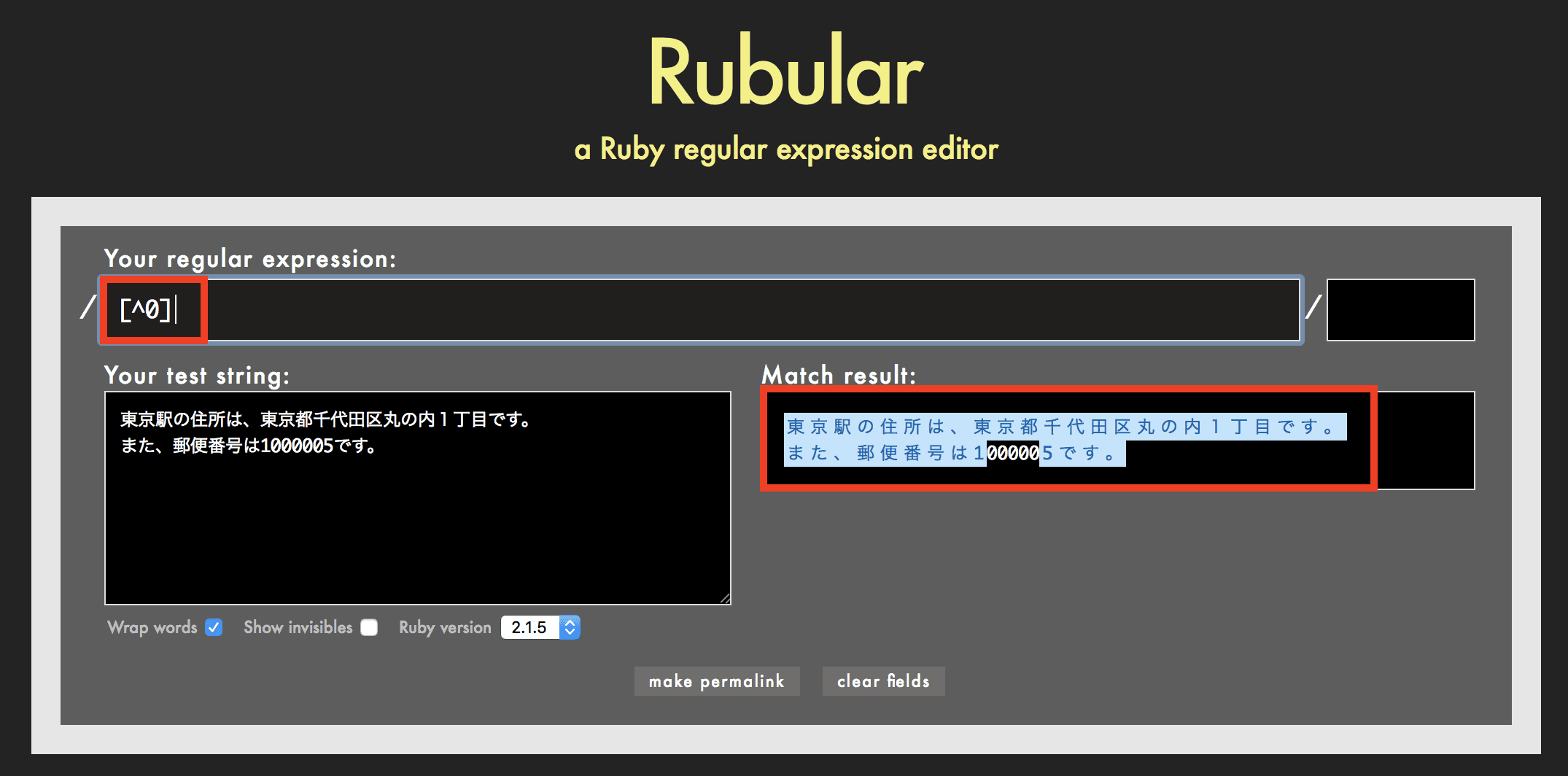
例えば正規表現が [^0] の場合、0以外の文字を検索します。
-の使用例
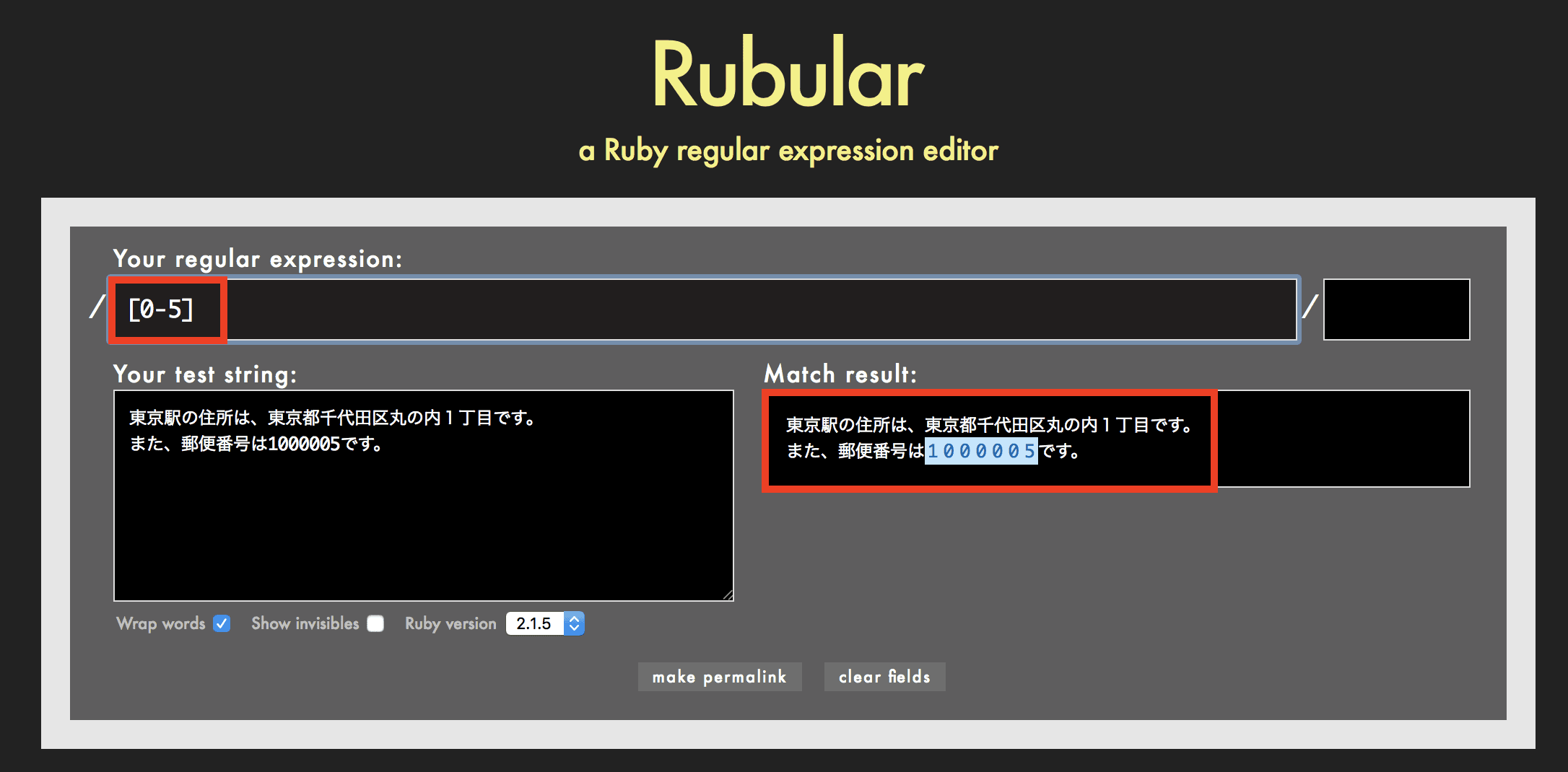
例えば正規表現が [0-5] の場合、0から5を検索します。
.の使用例
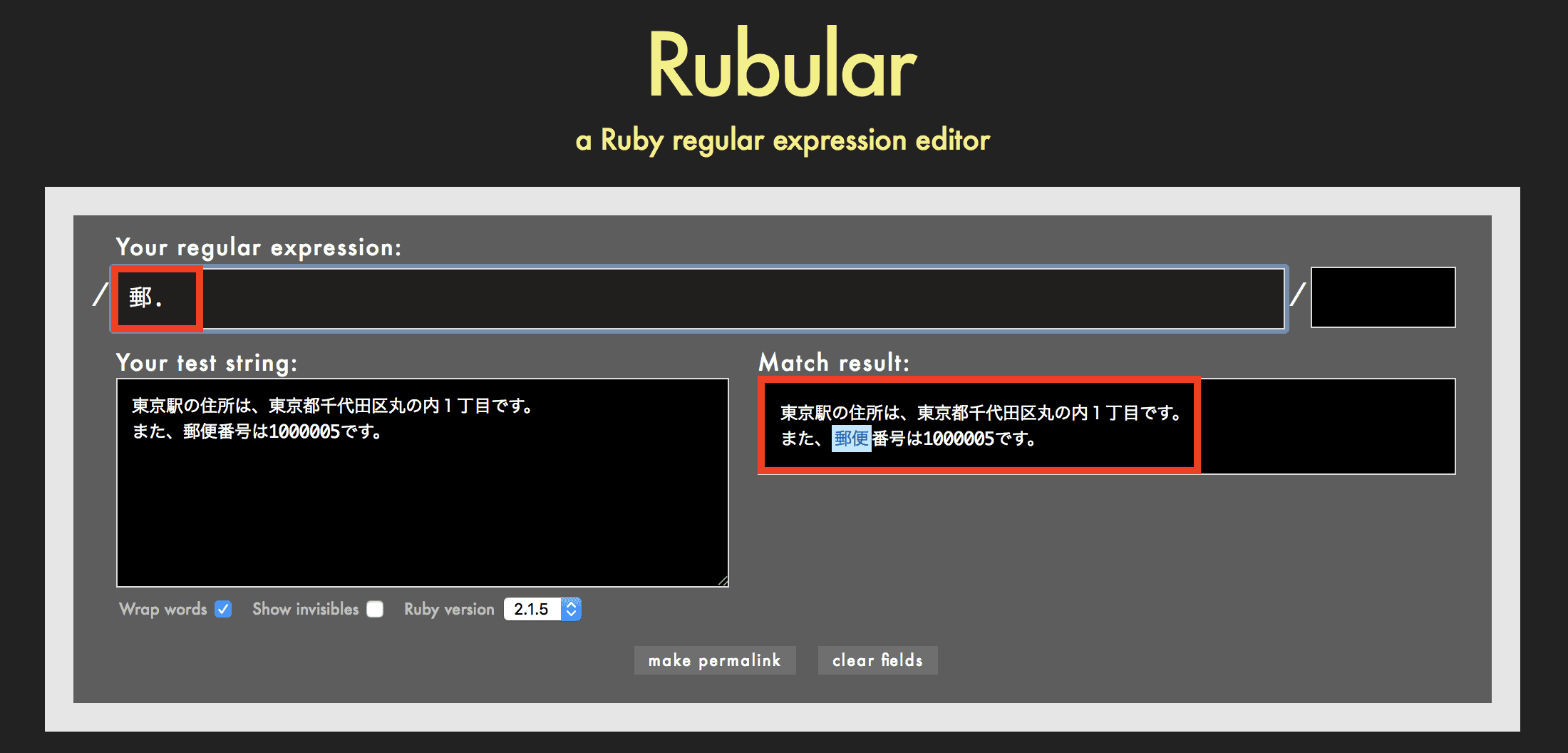
例えば正規表現が 郵. の場合、郵+任意1文字を検索します。
( )の使用例
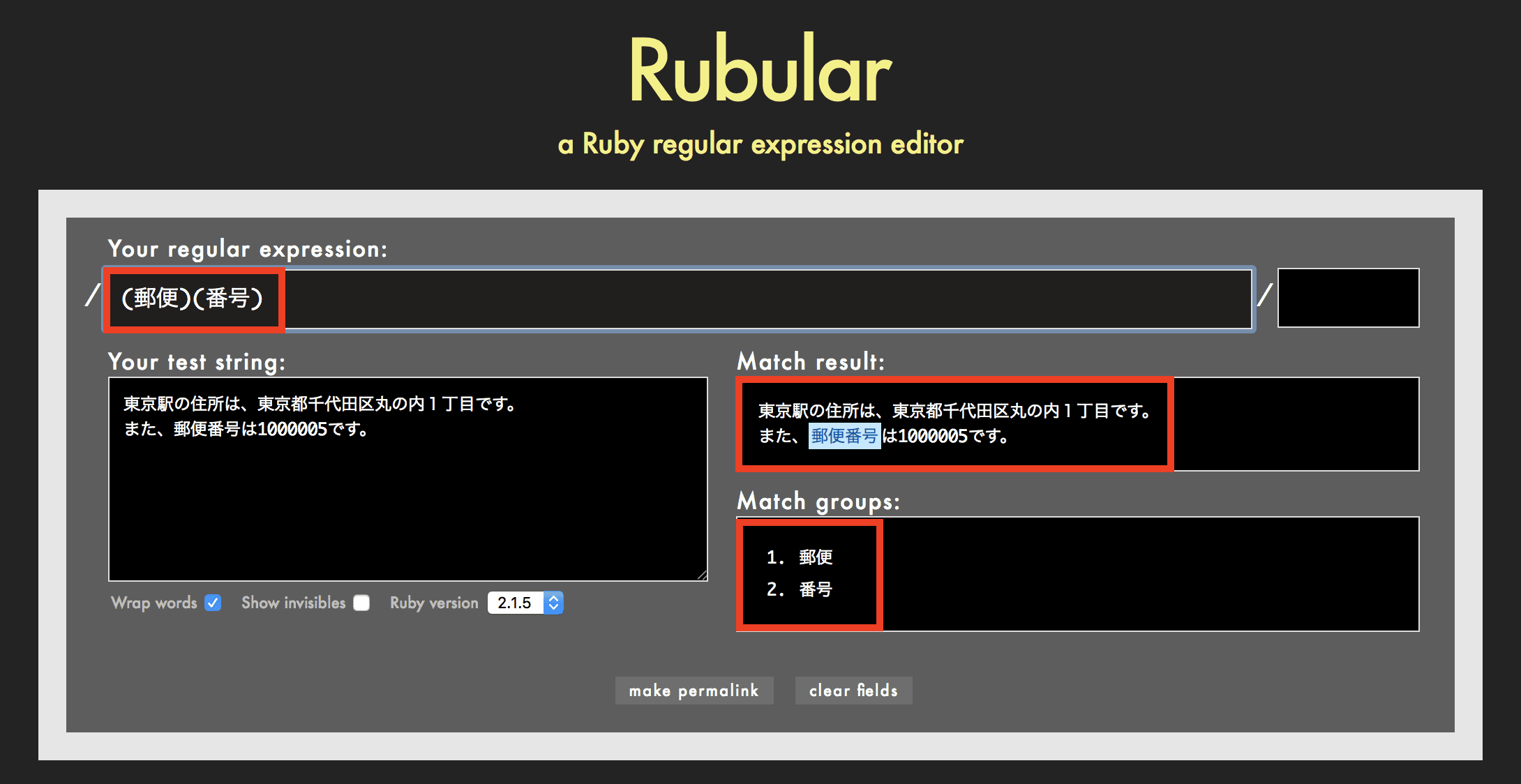
例えば正規表現が (郵便)(番号) の場合、郵便番号を検索し、郵便と番号をそれぞれキャプチャします。
?の使用例
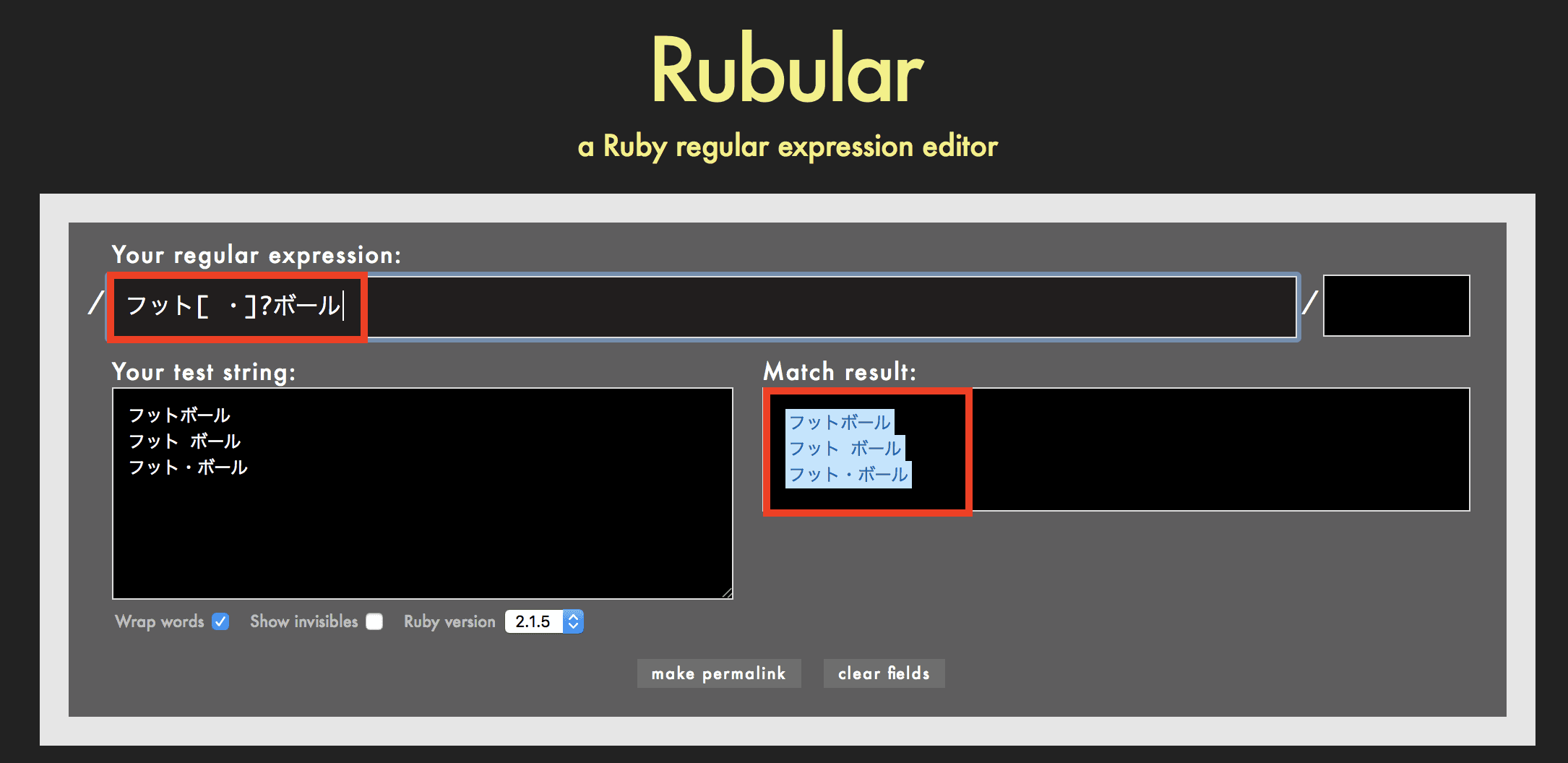
例えば正規表現が フット[ ・]?ボール の場合、フット+半角スペースまたは・(中点)が1文字または無し+ボールの文字列を検索します。
*の使用例
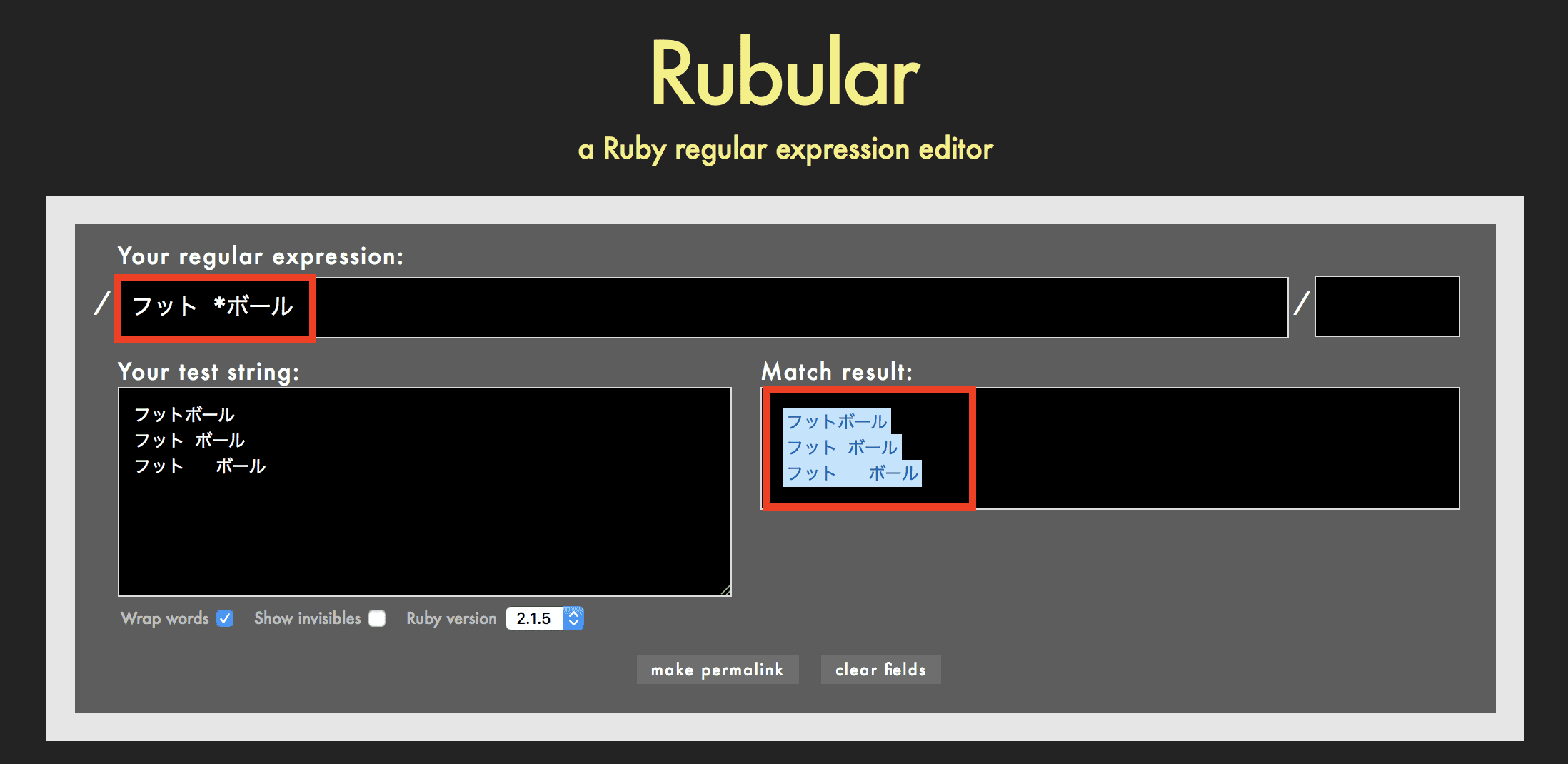
例えば正規表現が フット *ボール の場合、フット+半角スペースが0回以上連続する+ボールの文字列を検索します。
+の使用例
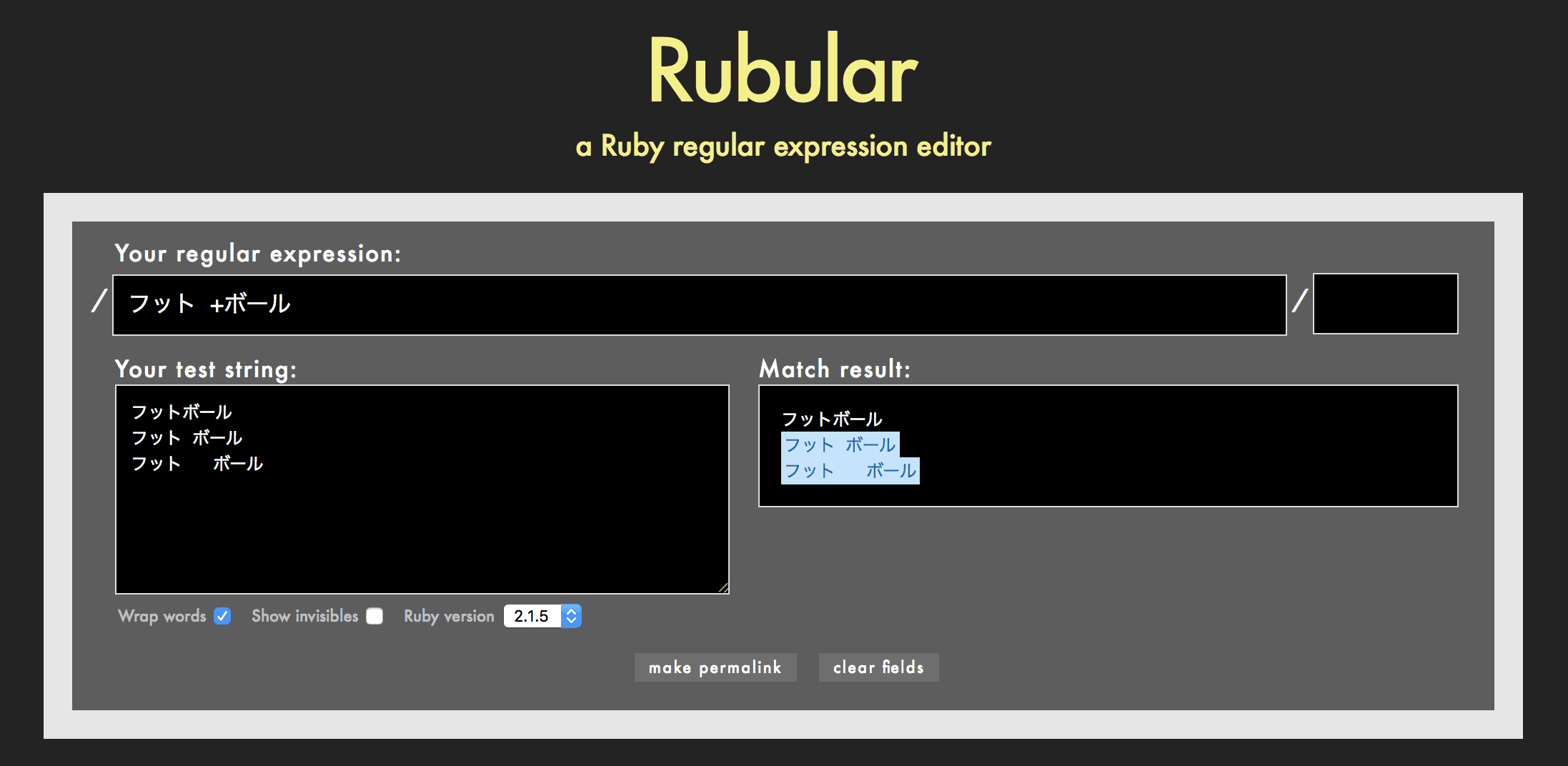
例えば正規表現が フット *ボール の場合、フット+半角スペースが1回以上連続する+ボールの文字列を検索します。
{n,m}の使用例
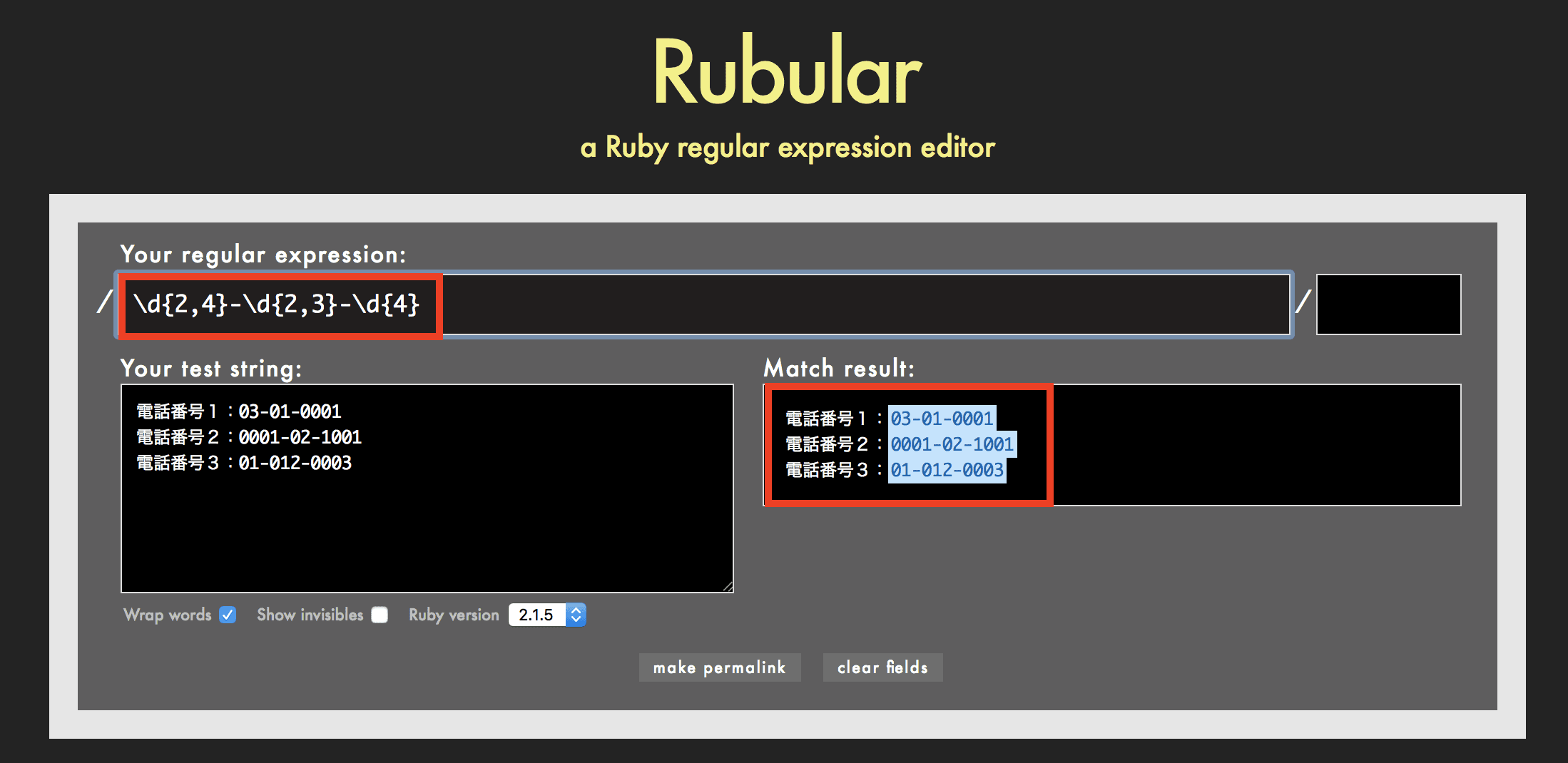
例えば正規表現が \d{2,4}-\d{2,3}-\d{4} の場合、半角数字が2〜4個、ハイフン、半角数字が2〜3個、ハイフン、半角数字が4個の文字列を検索します。
|の使用例

例えば正規表現が (?:十二|12)[月\/](?:十一|11)日? の場合、十二または12、月または/、十一または11、日または無しの文字列を検索します。
^の使用例
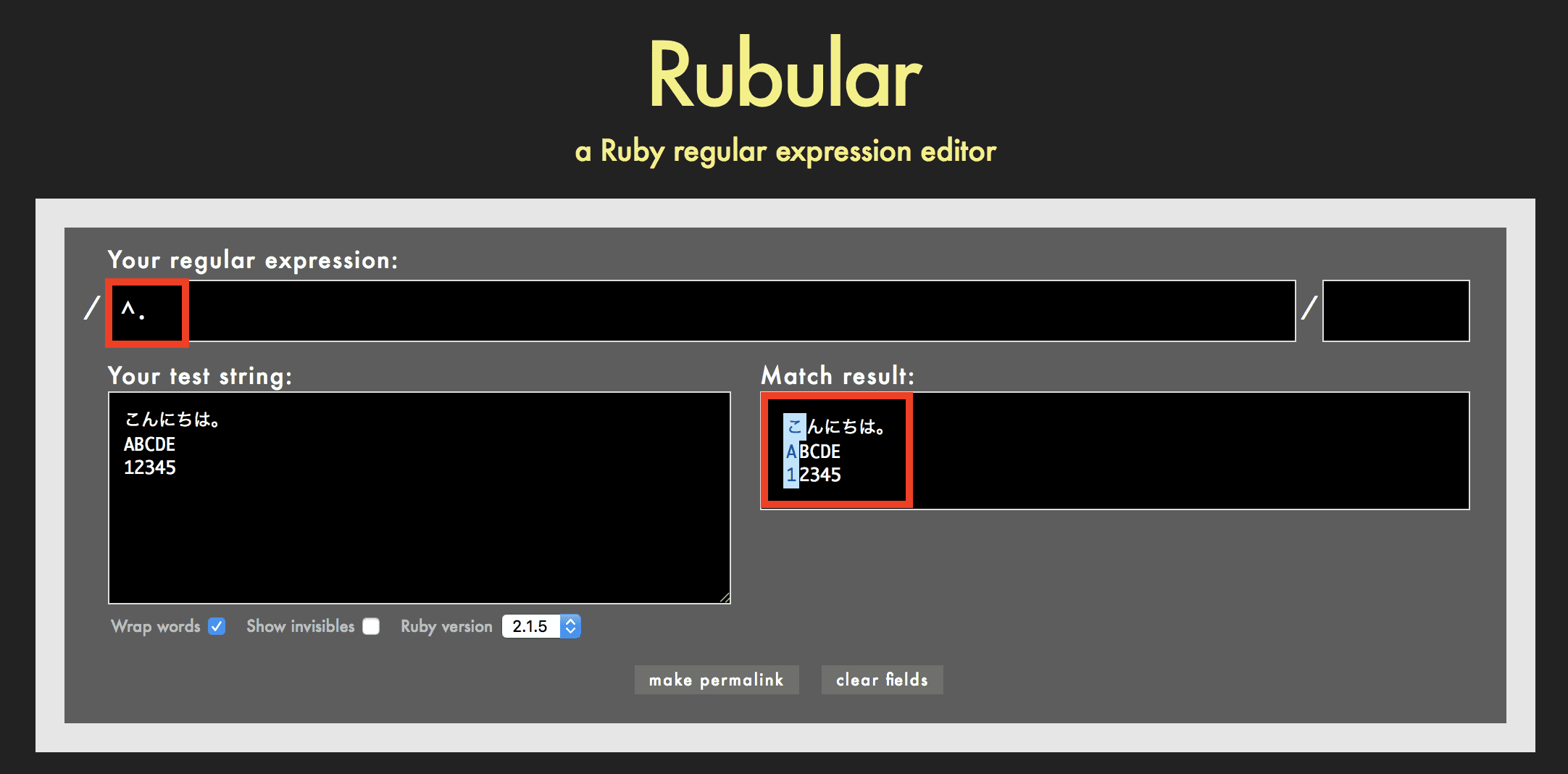
例えば正規表現が ^. の場合、行頭の任意の1文字を検索します。
$の使用例
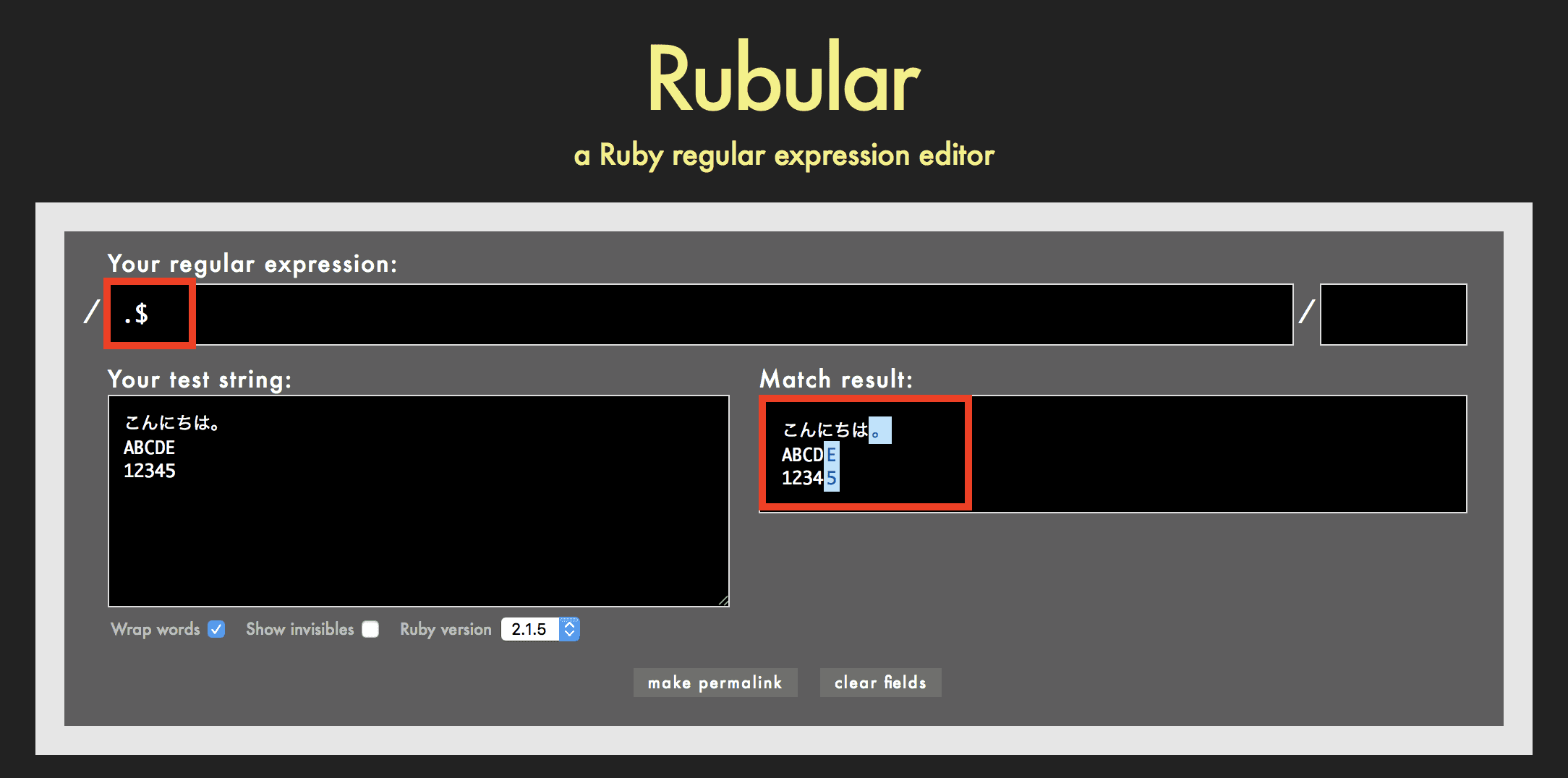
例えば正規表現が .$ の場合、行末の任意の1文字を検索します。
\の使用例
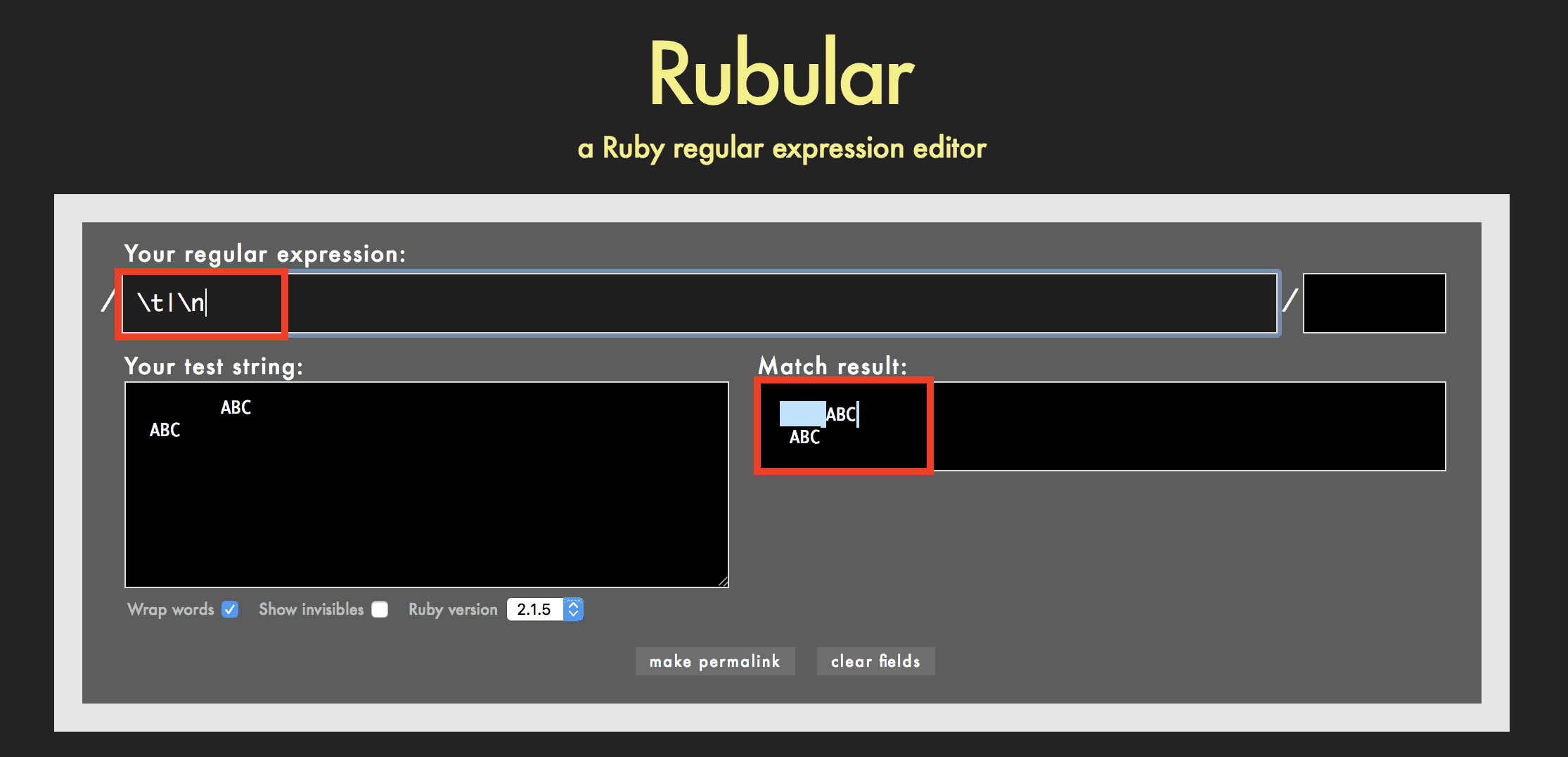
- \t はタブ文字を表す
- \n は改行文字を表す
- \s は空白文字(スペース、タブ文字、改行文字など)を表す
Rubyの正規表現オブジェクト
基本的な正規表現を理解した後、Rubyでの正規表現オブジェクトの使い方を覚えましょう。
Rubyの正規表現オブジェクトは、次のようにスラッシュで正規表現を囲んで作成します。
/正規表現/
では例として以下のプログラムを実行してみて下さい。
regex = /\d+/
puts regex.class
Regexp
実行結果の通り、正規表現はRegexpクラスのオブジェクトになります。
正規表現と文字列の比較
正規表現と文字列を比較する場合は「=~」を使います。
マッチした場合は文字列中のマッチした位置(0以上)を返し、マッチしなかった場合はnilを返します。
では例として以下のプログラムを実行してみて下さい。
p 'ABC-DEF' =~ /\w+-\w+/
0
「=~」はマッチすれば真、マッチしなければ偽を表すため、ifで比較することもできます。
if 'ABC-DEF' =~ /\w+-\w+/
puts 'マッチしました。'
else
puts 'マッチしませんでした。'
end
マッチしました。
その他、「!~」を使うとマッチしたときにfalse、マッチしなかった時にtrueを返します。
p 'ABC-DEF' !~ /\w+-\w+/
false
メソッドの使い方
Rubyで正規表現を使うには、以下のメソッドの使い方を覚えましょう。
- mach
- scan
- []、slice、slice!
- split
- gsub、grub!
mach
Rubyでキャプチャ(正規表現の( ))機能を利用するには、matchメソッドを使います。
文字列が正規表現にマッチするとMatchDataオブジェクトが返り、マッチしない場合はnilが返ります。
では以下のプログラムを実行してみて下さい。
text = '今日は2017年12月24日です。'
m = /(\d+)年(\d+)月(\d+)日/.match(text)
p m
puts m[1]
puts m[2]
puts m[3]
#<MatchData “2017年12月24日” 1:”2017″ 2:”12″ 3:”24″>
2017
12
24
実行結果の通り、年月日をそれぞれキャプチャできましたね。
また、キャプチャに名前を付けることもできます。
text = '今日は2017年12月24日です。'
m = /(?<year>\d+)年(?<month>\d+)月(?<day>\d+)日/.match(text)
p m
puts m[:year]
puts m[:month]
puts m[:day]
#<MatchData “2017年12月24日” year:”2017″ month:”12″ day:”24″>
2017
12
24
scan
scanメソッドは、引数で渡した正規表現にマッチする部分を配列に入れて返します。
では以下のプログラムを実行してみて下さい。
text = '今日は2017年12月24日です。'
m = text.scan(/(\d+)年(\d+)月(\d+)日/)
p m
p m[0]
p m[0][0]
p m[0][1]
p m[0][2]
“12”
“24”
[]、slice、slice!
[]に正規表現を渡すと、文字列から正規表現にマッチした部分を抜き出します。では以下のプログラムを実行してみて下さい。
text = '今日は2017年12月24日です。'
p text[/(\d+)年(\d+)月(\d+)日/]
“2017年12月24日”
尚、sliceメソッドは[]のエイリアスで、slice!はマッチした部分が文字列から破壊的に取り除かれます。
text = '今日は2017年12月24日です。'
text.slice!(/(\d+)年(\d+)月(\d+)日/)
p text
“今日はです。”
split
splitメソッドに正規表現を渡すと、マッチした文字列を区切り文字にして文字列を分解し、配列として返します。
では以下のプログラムを実行してみて下さい。
text = '12,345,67-89-0'
# 文字列で区切り文字を指定
p text.split(',')
# 正規表現で区切り文字を指定
p text.split(/,|-/)
gsub、grub!
gsubメソッドは、第1引数にマッチした文字列を第2引数の文字列で置き換えます。
では以下のプログラムを実行してみて下さい。
text = '12,345,67-89-0'
# 文字列で区切り文字を指定
p text.gsub(',', ':')
# 正規表現で区切り文字を指定
p text.gsub(/,|-/, ':')
“12:345:67-89-0”
“12:345:67:89:0”
また、キャプチャを使うと、第2引数で\1や\2のようにキャプチャした文字列を連番で参照できます。
text = '今日は2017年12月24日です。'
p text.gsub(/(\d+)年(\d+)月(\d+)日/, '\1-\2-\3')
“今日は2017-12-24です。”
名前付きキャプチャの場合は\k<name>を使います。
text = '今日は2017年12月24日です。'
p text.gsub(/(?<year>\d+)年(?<month>\d+)月(?<day>\d+)日/, '\k<year>-\k<month>-\k<day>')
“今日は2017-12-24です。”
尚、grub!メソッドは文字列の内容を破壊的に置換します。
最後に
今回は正規表現について解説しました。
いや〜、正規表現は覚えることが多いですね!
覚えてしまえば便利ですが、使いこなすには慣れが必要そうです。
まずは「正規表現を使えばこんなことができる」っていうのを覚えると良いでしょう。
正規表現を使いこなして、検索・置換マスターを目指しましょう!
- 関連記事















コメントを残す